Ingeniería Inversa en Linux
←
→
Transcripción del contenido de la página
Si su navegador no muestra la página correctamente, lea el contenido de la página a continuación
Ingeniería Inversa en Linux
Diego Bauche Madero – diego.bauche@genexx.org
Mayo 2005
Índice:
1. Introducción.
2. Qué es la ingeniería inversa.
3. La no distribución del código fuente
4. Para qué se utiliza.
5. Utilidades.
6. El formato ELF.
7. Desarrollo de la Ingeniería Inversa.
8. Ingeniería inversa en un ejemplo real.
9. Conclusiones.
10. Referencias.
11. Información de contacto.
1. Introducción
Este documento pretende que el lector se inicie y aprenda de forma rápida y precisa el arte de la ingeniería
inversa sobre Linux. El documento no pretende ser muy grande. Tratare de explicar paso por paso cómo un
experto en la ingeniería inversa puede lograr convertir y entender el funcionamiento de un ejecutable de
Linux (Un ejecutable ELF) para distintos beneficios.
Para leer este documento es necesario que el lector tenga amplios conocimientos en la programación sobe
ensamblador en Intel a 32 bits, conocimientos sobre la programación en C, así como que tenga experiencia
depurando y programando aplicaciones y que sepa manejar el sistema operativo Linux.
2. Que es la ingeniería inversa
La ingeniería inversa (o de reversa) es el arte de poder entender como funciona un ejecutable o un objeto
para así poder revertirlo, duplicarlo o mejorarlo. La practica de la ingeniería inversa se utiliza desde hace ya
mucho tiempo en empresas con muchos fines, un ejemplo claro podría ser cuando una empresa distribuidora
de un software, compra el producto de una empresa rival, con el fin de poder entender la funcionalidad e
implementarla en su solución, un ejemplo mucho mas claro pasa con las empresas automotrices, las cuales
suelen comprar algún automóvil de la competencia con el fin de explorarlo, analizarlo, desensamblarlo y
poder crear algo mejor.
En términos técnicos, la ingeniería inversa quiere decir convertir el código máquina de vuelta a un lenguaje
legible, por ejemplo, convertir calc.exe a calc.c o calc.cpp.
3. La no distribución de el código fuente
El código fuente de los programas muchas veces (Sino es que la mayoría) no suele ser distribuido en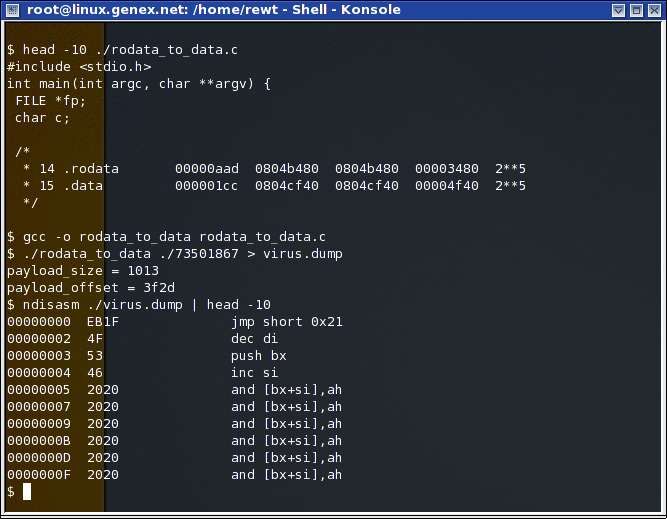
conjunto ni por separado con un programa, existen muchísimas razones por las cuales esto no sucede, las
mas claras y las mas dadas son, por ejemplo:
1. El código fuente es intelecto del programador, y quiere protegerlo.
2. La publicación del código fuente seria de gran riesgo para una empresa la cual compite con otros
programas.
3. Evadir la redistribución de el programa con otro con otro nombre como autor.
4. Dificultar mucho la búsqueda de vulnerabilidades dentro de la aplicación.
5. La penetración de servidores (Hacking) puede ser de muy alto riesgo, por lo tal muchos
programadores suelen usar técnicas antiforenses para dificultar el rastreo del intruso.
6. No permitir la mas mínima modificación a la aplicación.
7. Evadir la distribución de variaciones de la aplicación, lo cual representaría muchos problemas.
4. Para que se utiliza la ingeniería inversa
La ingeniería inversa es comúnmente usada para contrarrestar cualquiera de los propósitos de la no
distribución de código fuente dado en la tabla anterior, así como para descubrir código malicioso dentro de
un programa, saber como actúa para beneficio del usuario, etc. Por ejemplo, un usuario recibe una aplicación
llamada “Navidad.exe” por medio de MSN Messenger, el usuario, teniendo habilidades y experiencia en el
área de la Informática y sabiendo aplicar la ingeniería inversa, no confía mucho en esta aplicación por lo
cual utiliza la ingeniería inversa como método para tratar de buscar algún acto malicioso que el programa
realice, el usuario identifica el programa Navidad.exe como un Gusano que acaba de ser lanzado por lo cual
su Antivirus no pudo identificarlo, decide no correrlo, y lo reporta. Para dar un ejemplo de “Linux” y no solo
de Windows (Siguiendo la temática del documento), un caso común de Linux es cuando sospechas de algún
binario porque el MD5 no concuerda.
5. Utilidades
Hasta este momento, el lector ya sabe qué es la ingeniería inversa, el porque es necesaria y casos prácticos
en los cuales puede ser utilizada, pero... Como se desarrolla esta técnica?, Existen distintos tipos de
practicas para aplicarla, por lo tanto existen distintas técnicas y distintas utilidades, pero lo que nunca puede
faltar en la mano para hacer ingeniería inversa en Linux son:
strings: Un programa que te imprime en pantalla todas las partes del programa las cuales contienen cadenas
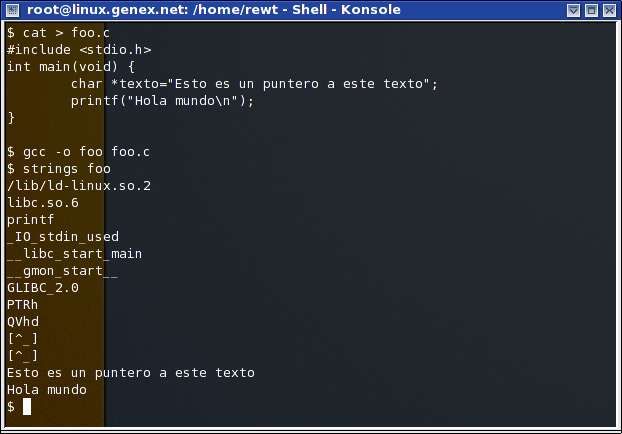
de caracteres legibles, como se muestra en el ejemplo de la siguiente imagen: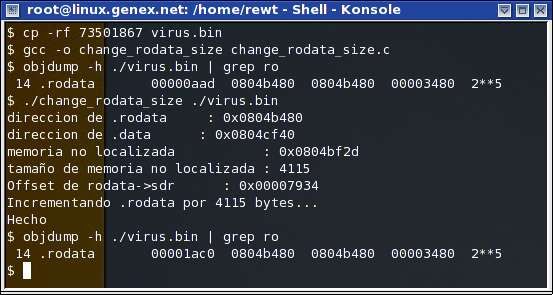
Como se puede apreciar, lo que nosotros hicimos fue crear un archivo llamado “foo.c” el cual es un código fuente en C, y después de la compilación, pudimos apreciar que con el comando “strings” podemos ver las cadenas de caracteres de los objetos de los cuales el programa depende (/lib/ldlinux.so.2, libc.so.6), así como los símbolos (printf), después alguna otra información, seguida por “Esto es un puntero a este texto” y “Hola mundo”. Strings generalmente viene incluida en todos las distribuciones Linux. en el paquete “binutils”. objdump: Esta aplicación es sumamente importante, ya que nos ayudara a desensamblar el código y nos dará información sobre el encabezado del objeto. Objdump generalmente viene incluida en todas las distribuciones Linux. En el paquete “binutils”. gdb: Es un depurador de aplicaciones, con el cual podremos seguir el flujo del objeto y modificarlo, así como desensamblarlo y averiguar información importante sobre el. Al igual que strings y objdump, gdb viene incluido en la mayoría de las distribuciones Linux, en el paquete “gdb”. DataRescue IDA Pro: El mejor desensamblador que conozco, puede desensamblar binarios ELF, PE, COFF, a.out, etc. Pero lo que lo hace tan buena herramienta es que te ayuda a entender claramente el flujo de una aplicación y te facilita la lectura de las instrucciones, así como genera gráficos, Etc. Desafortunadamente, IDA Pro no es un programa libre ni mucho menos gratuito, sin embargo, lo estaré utilizando en gran parte del proceso de este texto, así que recomendaría que el lector consiguiera una copia. IDA Funciona sobre Linux y Sobre Windows (a partir de la versión 4.7 salio un porte para Linux). Existe una copia de IDA Pro que es Freeware, pero en lo personal no la he probado, aunque posiblemente les servirá a las personas las cuales no puedan conseguir una copia de IDA Pro comercial (El enlace se encuentra en Referencias) 6. El formato ELF No pienso dar una explicación amplia sobre como funciona este tipo de formato binario, lo voy a resumir un
poco tratando de explicar claramente como funciona. ELF (Executable and Linking Format) es el formato binario por defecto de Linux. El mismo nombre nos da a entender que no es solo el formato de los binarios ejecutables, sino que es el mismo formato para objetos y objetos compartidos que después se enlazan a un ejecutable, podríamos llamar a estos módulos (esto quiere decir que así como ELF es el formato de /bin/ls, también es el formato de /usr/lib/libc.so, / usr/src/linux/kernel/kernel.o, Etc.). Para saber si nuestro binario es ELF, basta con reconocer los primeros 4 bytes de su encabezado, o usar la aplicación 'file' que viene incluida generalmente en cualquier Linux, la cual nos dirá aun mas información sobre el objeto: $ file /bin/ls /bin/ls: ELF 32bit LSB executable, Intel 80386, version 1 (SYSV), for GNU/Linux 2.2.5, dynamically linked (uses shared libs), stripped $ Como podemos apreciar en las lineas anteriores, utilice la aplicación 'file' sobre el binario /bin/ls, y el resultado me dice que la aplicación es una aplicación de tipo ELF, de 32 bits, es ejecutable, su arquitectura es Intel x86, para GNU/Linux, y esta enlazada dinámicamente, esta 'strippeada', que quiere decir que se uso la utilería 'strip', la cual remueve la sección .sym (Los símbolos) de la aplicación. El formato ELF se divide Generalmente (en el orden presentado) en 5 áreas (Las estructuras se localizan en elf.h): 1. Cabecera o Header, el cual es el que contiene toda la información del formato dentro de una estructura de tipo Elf32_Ehdr, como cual es la primera dirección a ejecutarse (Entry point), si es de 32 o 64 bits, si es un core, un archivo compartido (Shared object), ejecutable o reubicable (Relocatable), cuanto mide, Etc. 2. Program Header Table, Son varias estructuras Elf32_Phdr las cuales describen cada una la información de un segmento (Un segmento contiene una o mas secciones), la cual es información que el cargador de ejecutables y los shared objects necesitan para poder reservar memoria para ellos, y otras cosas. 3. Segmentos (.data, .text), Los segmentos son rangos de memoria física que contienen secciones especificas de la aplicación, utilizando arreglos de estructuras Elf32_Shdr. 4. Section Header Table, la cual es opcional para un ejecutable, ya que solo contiene una tabla de secciones que no están asociadas con un segmento, como .debug (La cual contiene información para depuración), .sym (La cual contiene los símbolos), Etc. 5. Otras secciones, no asociadas con los segmentos .text, .data, Etc. Creo que esto es todo lo que necesitamos saber para poder introducirnos en lo básico de la ingeniería inversa de binarios ELF. El formato ELF es importante y es de mucha utilidad saber cómo funciona, ya que contiene la información esencial de nuestra aplicación, si estas interesado en leer la documentación amplia sobre este formato, en la sección de Referencias se encuentra la documentación oficial de ELF.
7. Desarrollo de la Ingeniería Inversa
Para poder documentar como se desarrolla la ingeniería inversa, lo primero que vamos a hacer va a ser un
programa chico y básico:
#include
#include
[1] void copia(char *dst, const char *src, short len);
[2] int main(int argc, char **argv) {
[3] char buf[1024];
[4] if(argc != 2) {
[5] printf("Se espera un argumento\n");
[6] return 2;
}
[7] copia(&buf[0],argv[1],sizeof(buf)1);
[8] printf("Los datos copiados son: %s\n", buf);
[9] return 0;
}
[10] void copia(char *dst, const char *src, short len) {
[11] for(;len;len)
[12] *dst++=*src++;
}
Este programa lo único que hace es, verificar que los argumentos no sean diferentes a dos (Que exista un
argumento), sino sale diciendo “Se espera un argumento”, si si hay un argumento, llama a la función copia
(), la cual simplemente copia una cadena a la otra (src a dst) len bytes, escribe “Los datos copiados son:
”, y sale con suceso. Si lo analizamos en pasos:
– [1] y [2] declaran las funciones copia() y main(), en este momento la que nos interesa es main, y por lo
que podemos ver, es declaración entera y utiliza 'argc' y 'argv'.
– [3] declara una cadena de datos de 1024 bytes de tipo 'char', la cual se llama buffer.
– [4] compara el argumento argc (la cuenta de cuantos argumentos se le pasaron a la aplicación), si no es 2
(si no existe un argumento), la linea [5] se ejecuta y retorna como se puede ver en [6].
– [7] es la llamada a la función copia(), y como vimos ya en [1], copia recibe tres argumentos: dst, src y
len.
– [8] y [9] Son las ultimas lineas del programa, las cuales simplemente despliegan el resultado de lo que
hizo [7] en pantalla, y retorna la aplicación.– [10] es simplemente la declaración de la función copia(), por lo tanto las lineas siguientes son parte de
esta función.
– [11] y [12] lo que hacen básicamente es copiar byte por byte la cadena 'src' a 'dst' len veces.
Ahora que entendemos perfectamente como funciona el programa, podemos empezar a analizarlo.
Después de compilarlo como ¨ejemplo1”, voy a desensamblarlo y voy a intentar explicar la información del
código. Como yo se que el binario no paso por “strip”, por lo tanto se que contiene los símbolos, y que las
funciones que me interesan son y , empezando por main. Ejecuto objdump para que me
muestre el código desensamblado de la sección .text el cual se va a mostrar en sintaxis Intel:
(Nota: Yo prefiero utilizar la sintaxis Intel en lugar de AT&T, y así la utilizare en todo el proceso)
$ objdump –dissasembleroptions=intel D section .text ./ejemplo1
...
08048364 :
8048364: 55 push ebp
8048365: 89 e5 mov ebp,esp
8048367: 81 ec 28 04 00 00 sub esp,0x428
804836d: 83 e4 f0 and esp,0xfffffff0
8048370: b8 00 00 00 00 mov eax,0x0
8048375: 29 c4 sub esp,eax
8048377: 83 7d 08 02 cmp DWORD PTR [ebp+8],0x2
804837b: 74 18 je 8048395
...
Este es el formato que objdump nos tira, algo ofuscado y difícil de leer, por esta misma razón, cada que
utilice un desensamblador utilizare IDA Pro, ya que es mucho mas claro:
ÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛ S U B R O U T I N E ÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛ
; Attributes: bpbased frame
public main
main proc near ; DATA XREF: _start+17^Xo
var_428 = dword ptr 428h
var_424 = dword ptr 424h
var_420 = dword ptr 420h
var_40C = dword ptr 40Ch
var_408 = dword ptr 408h
arg_0 = dword ptr 8
arg_4 = dword ptr 0Ch
push ebp
mov ebp, esp
sub esp, 428h
and esp, 0FFFFFFF0h
mov eax, 0
sub esp, eax
cmp [ebp+arg_0], 2
jz short loc_8048395mov [esp+428h+var_428], offset aSeEsperaUnArgu ; "Se espera un argumento\n"
call _printf
mov [ebp+var_40C], 2
jmp short loc_80483D7
; ÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄ
loc_8048395: ; CODE XREF: main+17^Xj
mov [esp+428h+var_420], 3FFh
mov eax, [ebp+arg_4]
add eax, 4
mov eax, [eax]
mov [esp+428h+var_424], eax
lea eax, [ebp+var_408]
mov [esp+428h+var_428], eax
call copia
lea eax, [ebp+var_408]
mov [esp+428h+var_424], eax
mov [esp+428h+var_428], offset aLosDatosCopiad ; "Los datos copiados son: %s\n"
call _printf
mov [ebp+var_40C], 0
loc_80483D7: ; CODE XREF: main+2F^Xj
mov eax, [ebp+var_40C]
leave
retn
main endp
; ÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛ S U B R O U T I N E ÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛ
; Attributes: bpbased frame
public copia
copia proc near ; CODE XREF: main+4E^Xp
var_2 = word ptr 2
arg_0 = dword ptr 8
arg_4 = dword ptr 0Ch
arg_8 = dword ptr 10h
push ebp
mov ebp, esp
sub esp, 4
mov eax, [ebp+arg_8]
mov [ebp+var_2], ax
loc_80483EC: ; CODE XREF: copia+34^Yj
cmp [ebp+var_2], 0
jnz short loc_80483F5
jmp short locret_8048415
; ÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄ
loc_80483F5: ; CODE XREF: copia+12^Xj
mov eax, [ebp+arg_0]
mov edx, eaxmov eax, [ebp+arg_4]
movzx eax, byte ptr [eax]
mov [edx], al
lea eax, [ebp+arg_4]
inc dword ptr [eax]
inc [ebp+arg_0]
movzx eax, [ebp+var_2]
dec eax
mov [ebp+var_2], ax
jmp short loc_80483EC
; ÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄ
locret_8048415: ; CODE XREF: copia+14^Xj
leave
retn
copia endp
Como se ve en el ejemplo anterior, el formato que nos tira IDA Pro es mucho mas claro, después de 4 o 5
minutos de leer el código, puedo convertirlo a C fácilmente, este es un programa de prueba, así que eso
explica porque solo tarde unos cuantos minutos, sin embargo, en programas grandes esto puede durar días y
semanas enteras.
Después de hacer un análisis y comentar el código, pude realizar una conversión directa (Pude invertirlo a su
código original):
#include
void copia(char *arg1, char *arg2, short arg3);
int main(int argc, char *argv[]) {
char buffer[1024];
if(argc != 2) {
printf("Se espera un argumento\n");
return 2;
}
copia(&buffer[0],argv[1],1023);
printf("Los datos copiados son: %s\n",buffer);
return 0;
}
void copia(char *arg1, char *arg2, short arg3) {
short len = arg3;
char *edx, *eax;
for(;len!=0;len) {
edx = arg1;
eax = arg2;*edx = *eax;
arg2++;
arg1++;
eax = (char *)&len;
eax;
}
}
Posiblemente, o mejor dicho, obviamente, el lector en estos momentos estará pensando “Bueno, si,
convertiste el código y hace exactamente lo mismo que el original, pero el código original tu ya lo poseías,
por lo tanto solo generaste una nueva solución”, Esto es incorrecto, no se si haya influido o no que yo
supiera como este código estaba hecho ya desde un principio, pero la conversión generada no fue
basada en ninguna nueva solución en lo absoluto, sino que a partir del código en ensamblador, logre
hacer la conversión a C.
Pero, cual fue el proceso que seguí?, como pude lograr tal hecho?, es solo cosa de analizar la parte
importante de nuestro código y comentarla.
IDA Pro tiene la opción de cambiar el nombre de las variables para poder hacer una mejor lectura,
así como puedes cambiar el nombre de las funciones y comentar cada instrucción, en este caso no
voy a cambiar ningún nombre de variable, funciones o etiquetas. Vamos a comentar parte por parte
del código desensamblado:
main:
[0] var_428 = dword ptr 428h
[0] var_424 = dword ptr 424h
[0] var_420 = dword ptr 420h
[0] var_40C = dword ptr 40Ch
[0] var_408 = dword ptr 408h
[0] arg_0 = dword ptr 8
[0] arg_4 = dword ptr 0Ch
[1] push ebp
[2] mov ebp, esp
[3] sub esp, 428h
[4] and esp, 0FFFFFFF0h
[5] mov eax, 0
[6] sub esp, eax
[7] cmp [ebp+arg_0], 2
[8] jz short loc_8048395
[9] mov [esp+428h+var_428], offset aSeEsperaUnArgu ; "Se espera un argumento\n"
[10] call _printf
[11] mov [ebp+var_40C], 2
[12] jmp short loc_80483D7– [0] es la forma en la que IDA Pro, a partir de su algoritmo, genera variables para facilitar a lectura del
código, como podemos apreciar tiene 2 argumentos, arg_0 y arg_4, por lo tanto deducimos “main(int
argc, char **argv) {”.
– [1] a la [6], no es código realmente importante, solo esta consiguiendo todo el espacio suficiente para las
variables dentro del stack.
– [7], podemos apreciar que compara [ebp+arg0] (o sea, [ebp + 8] = argc) con 2, podemos transformar
este código a un “if(argc == 2)”.
– [8], adentro del if(argc == 2), salta a la etiqueta loc_8048395, con esto sabemos que la [7] y la [8] son “
if(argc == 2) goto loc_8048395;”.
– [9], mueve a la variable var_428 (Si vemos que el valor de la variable var_428 es 428h, entonces la
operación de [esp+428h+var_428h] es (esp + 0x428 + 0x428) la dirección donde se encuentra la cadena
'“Se espera un argumento\n”'.
– [10], llama a printf, el argumento que printf toma es a donde apunta [esp+428h+var_428], por lo tanto,
podemos deducir que la linea [9] y la linea [10] finalizan siendo 'printf(“Se espera un argumento\n”);
'.
– [11] y [12] son irrelevantes, claramente se aprecia que lo que hacen es mover el valor entero '2' a
var_40C, y llamar a la etiqueta loc_80483D7, que simplemente termina el control del programa,
por lo cual deducimos que es “return 2;”, también deduciendo que la función main() es de tipo
'int'.
Así finaliza parte de nuestro análisis de la función , con lo cual la revertimos a código C,
quedando así:
int main(int argc, char **argv) {
if(argc == 2) {
goto loc_804395;
}
printf(“Se espera un argumento\n”);
return 2;
}
La segunda parte del análisis va enfocada a desensamblar la etiqueta loc_804395:
loc_8048395:
[1] mov [esp+428h+var_420], 3FFh
[2] mov eax, [ebp+arg_4]
[3] add eax, 4
[4] mov eax, [eax]
[5] mov [esp+428h+var_424], eax
[6] lea eax, [ebp+var_408][7] mov [esp+428h+var_428], eax
[8] call copia
[9] lea eax, [ebp+var_408]
[10] mov [esp+428h+var_424], eax
[11] mov [esp+428h+var_428], offset aLosDatosCopiad ; "Los datos copiados son: %s\n"
[12] call _printf
[13] mov [ebp+var_40C], 0
loc_80483D7:
[14] mov eax, [ebp+var_40C]
[15] leave
[16] retn
– [1] Se mueve 0x33F (0x33F = 1023) a la variable var_420.
– [2] Se mueve argv a eax.
– [3] Se suma 4 a eax. Como saben ya, *argv es argv[0], argv siendo un doble puntero, mide 4
bytes, por lo tanto, sumar 4 a eax es hacer que eax apunte a *argv + 4, que es argv[1].
– [4] Se mueve el valor de la dirección de eax a eax, que quiere decir esto?, básicamente “eax =
*eax”.
– [5] Se mueve a la variable var_424 lo que vale eax. “(int)var_424 = (int)eax”.
– [6] Se carga en eax la dirección de var_408. “eax = (char *)&var_408”.
– [7] Se mueve a var_428 el valor de eax. “(long)var_428 = (long)eax”
– [8] Se llama a copia(), como podemos apreciar aquí, lo que contiene var_428 es la dirección de
var_408. var_408 es una arreglo de 0x408 bytes (0x408 = 1032), que haría que, menos 8 bytes
de alineamiento del compilador, var_408 equivalga a algo similar a “char buffer[1024];”. Por
lo tanto, siendo var_428 la dirección de buffer (&buffer[0]), var_424 apuntando a argv[1], y
argv_420 valiendo 1023, se pueda deducir que esta rutina es igual a “copia(&buffer[0],argv[1],
1023);”.
– [9] Se carga en eax la dirección de var_408 (buffer). “eax = &buffer[0]”
– [10] se carga a arg_424 el valor eax. “(long)arg_424 = (long)eax”
– [11] se carga a arg_428 el valor de la dirección donde se encuentra “Los datos copiados son: %
s\n”.
– [12] se llama a printf, por lo tanto, podemos deducir que de la linea [9] a la linea [12] convertido
a C significaría “printf(“Los datos copiados son: %s\n”,buffer);”
– [13] mueve a var_40C el entero 0.
– [14], [15] y [16] retornan el control, por lo tanto podemos deducir que [13], [14] y [15] son
“return 0;”
Después de tanta explicación, finalmente pudimos conseguir el código completo de main():
int main(int argc, char **argv) {
if(argc == 2) {
goto loc_804395;}
printf(“Se espera un argumento\n”);
return 2;
loc_804395:
copia(&buffer[0],argv[1],1023);
printf(“Los datos copiados son: %s\n”,buffer);
return 0;
}
copia() {
...
}
Bueno, la siguiente función ( copia() ) la vamos a desensamblar también:
[1] var_2 = word ptr 2
[2] arg_0 = dword ptr 8
[2] arg_4 = dword ptr 0Ch
[2] arg_8 = dword ptr 10h
push ebp
mov ebp, esp
sub esp, 4
[3] mov eax, [ebp+arg_8]
[4] mov [ebp+var_2], ax
loc_80483EC: ; CODE XREF: copia+34j
[5] cmp [ebp+var_2], 0
[6] jnz short loc_80483F5
[7] jmp short locret_8048415
; ÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄ
loc_80483F5: ; CODE XREF: copia+12j
[8] mov eax, [ebp+arg_0]
[9] mov edx, eax
[10] mov eax, [ebp+arg_4]
[11] movzx eax, byte ptr [eax]
[12] mov [edx], al
[13] lea eax, [ebp+arg_4]
[14] inc dword ptr [eax]
[15] inc [ebp+arg_0]
[16] movzx eax, [ebp+var_2]
[17] dec eax
[18] mov [ebp+var_2], ax[19] jmp short loc_80483EC
; ÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄ
[20] locret_8048415: ; CODE XREF: copia+14j
[21] leave
[22] retn
copia endp
– [1] , como podemos ver, var_2 es una WORD (o sea, una variable de 2 bytes, por lo tanto podemos
deducir que es de tipo 'short').
– [2], Aquí podemos ver que tiene tres argumentos, arg_0, arg_4 y arg_8, por lo tanto el programa esta
declarado con 3 argumentos.
– [3] y [4], Aquí apreciamos que lo que esta haciendo es mover el valor de arg_8 a eax, y de (short)eax a
var_2 ((short)eax == ax), como dijimos en [1], var_2 es una WORD, por lo tanto podemos deducir que el
arg_8 (siendo el tercer argumento) es “short arg_8;”.
– [5], [6] y [7], estas lineas hacen una comparación de 0 con var_2 (var_2 como ya lo vimos contiene el
valor del argumento 3), si la comparación no se cumple, salta a loc_80483F5; Si sí se cumple, salta a
locret_8048415, Como podemos ver, el nombre de esta ultima función es ¨locret_...¨, cuando generalmente
es loc_, que quiere decir esto?, IDA Pro detecta si la parte donde se encuentra esta función es solo un
“return”, y si sí, declara el nombre de la función así, por lo tanto hasta aquí podemos deducir que estas
lineas podrían ser “if(var_2 == 0) { goto loc_80483F5; } else { goto locret_8048415; }”
– [8] y [9], aquí vemos como mueve a edx el valor de arg_0 (o sea, del segundo argumento), con lo cual
podríamos decir “eax = arg_0; edx = eax;”
– [10], aquí podemos ver como mueve el valor de arg_4 (del segundo argumento) a eax, “eax = arg_4”.
– [11], aquí vemos como mueve a eax el primer byte de la dirección de eax, que podría ser, “eax = *eax;“
– [12], se mueve *eax (que es al obviamente) a *edx, (recordemos que edx apunta a arg_0) o sea que es
algo como “*edx = (char)eax;”.
– [13], [14] y [15], se carga en eax la dirección de el segundo argumento, y después se incrementa eax,
después se incrementa el primer argumento, que seria “eax = arg_4; eax++; arg_0++;”
– [16], [17] y [18], se mueve a eax la el valor de var_2, se decrementa eax y se mueve el valor de eax a
var_2, seria “(short)eax = var_2; eax; var_2 = (short)eax;”
– [19], salta a loc_80483EC (que es [5]), por lo cual deducimos que desde [5] hasta [19], son un loop, y por
esta misma razón descubrimos que “if(var_2 == 0) { goto loc_80483F5; } else { goto locret_8048415; }
” de [5], [6] y [7] realmente seria “for(; var_2 != 0; var2) {”
– [20], [21] y [22] finalmente aquí podemos ver que no se regresa ningún valor cuando el for acaba, por lo
tanto deducimos que copia() es del tipo 'void'.
Después de convertir todo esto, y después de cambiar algunas cosas las cuales no son validas en C, podemos
finalmente convertir el programa completo con éxito, el cual quedaría así:
void copia(char *arg_0, char *arg_4, short arg_8) {
short var_2 = arg_8;char *eax, char *edx;
for(; var_2 != 0;) {
eax = arg_0;
edx = eax;
eax = arg_4;
*edx = *eax;
arg_4++;
arg_0++;
(short *)eax = (short)var_2;
eax;
var_2 = (short)eax;
}
return;
}
int main(int argc, char **argv) {
if(argc == 2) {
goto loc_804395;
}
printf(“Se espera un argumento\n”);
return 2;
loc_804395:
copia(&buffer[0],argv[1],1023);
printf(“Los datos copiados son: %s\n”,buffer);
return 0;
}
Como se puede apreciar, lo que este código hace es lo que hace el mismo código original, para hacer la
prueba, compilamos este código como prueba1_rev2.c y lo probamos:
$ !gcc
gcc o prueba1_rev2 prueba1_rev2.c
prueba1_rev2.c: In function `copia':
prueba1_rev2.c:14: warning: cast from pointer to integer of different size
$ ./prueba1_rev2 aaaa
Los datos copiados son: aaaa
$
Como se ve, es exactamente lo mismo. Después de saber muy bien como funciona, podemos simplificar el
código y hacerlo mas entendible, hasta el punto de llegar al código original, pero sin poder conseguir los
nombres de variables, hasta quedar asi:void copia(char *arg_0, char *arg_4, short arg_8) {
for(; arg_8 != 0;arg_8) {
*arg_0++ = *arg_4++;
}
return;
}
int main(int argc, char **argv) {
char buffer[1024];
if(argc != 2) {
printf("Se espera un argumento\n");
return 2;
}
copia(&buffer[0],argv[1],1023);
printf("Los datos copiados son: %s\n",buffer);
return 0;
}
Y, como se ve en este ultimo código, es exactamente lo mismo que el original, eso quiere decir que hemos
podido revertir el código completamente.
8. Ingeniería Inversa en un ejemplo real.
Para el ejemplo real, se escoge una aplicación sin código fuente. Lo primero que se me vino a la cabeza fue
packetstorm, ya que a veces ahí publican cosas como exploits sin código fuente, entonces, abrí mi navegador
y fui a www.packetstormsecurity.com/removed/
Ahí, encontré un binario que se llamaba 73501867, el cual, por deducción (Creo que ya todos sabemos que si
empieza con 7350, generalmente es un exploit del grupo TESO) supe que era supuestamente un exploit, lo
primero que hago es obviamente bajarlo
$ wget http://www.packetstormsecurity.com/removed/73501867
...
16:28:19 (7.37 KB/s) `73501867' saved [41948/41948]
$
Como en lo personal no confío mucho en la fuente (packetstorm), tampoco si es solo binario sin código
fuente ni mucho menos si se encuentra en una carpeta llamada “removed”, verifico la información del
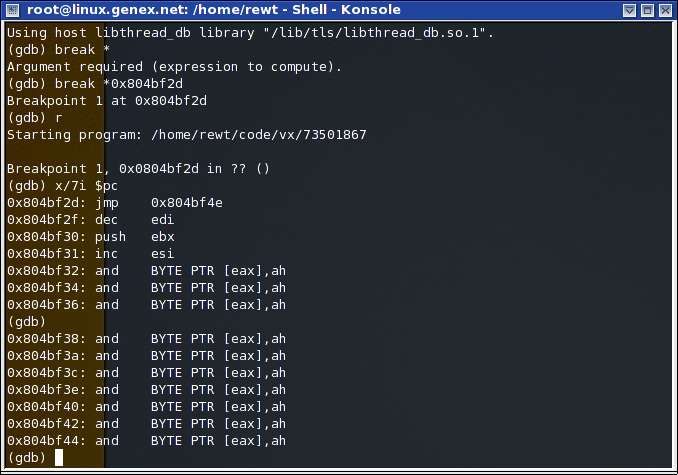
binario para verificar si es anormal:$ chmod x 73501867 $ ./elf_ep_check 73501867 v ELF Size: 41948 bytes Entry Point: 0x0804bf2d .text address: 0x08048fd0 Alert: Entry point is modified, possible ELF modification (Virus, backdoor,trojan, binary compression?) $ Como podemos ver aquí, lo que hice fue correr la aplicación “elf_ep_check” (codigo bastante simple el cual pueden encontrar en http://genexx.org/pubs/iil/elf_ep_check.c), que lo que hace es conseguir la dirección de .text (Que es donde generalmente debe empezar una aplicación, o sea que el entry point debe apuntar a ahí), y como podemos ver, el entry point apunta a 0x0804bf2d. Parece ser que el binario esta modificado, vamos a checar en que segmento se encuentra 0x0804bf2d para poder ver que contiene, para esto vamos a utilizar objdump: $ objdump h ./73501867 ./73501867: file format elf32i386 Sections: Idx Name Size VMA LMA File off Algn ... 13 .fini 0000001e 0804b44c 0804b44c 0000344c 2**2 14 .rodata 00000aad 0804b480 0804b480 00003480 2**5 ... $ Aquí lo que hice fue usar la opción 'h' de objdump la cual saca información sobre las secciones de los segmentos, y como podemos ver, las únicas dos secciones las cuales empiezan de un numero “0x0804bXXX” son .fini y .rodata, sin embargo, el segmento mas cercano es .rodata (El nombre nos hace entender que .rodata significa “ReadOnly data”), por lo cual medimos el tamaño de este segmento buscando si se encuentra ahí nuestra dirección a la cual apunta entry point (0x0804bf2d). Lo que vamos a hacer va a ser sumar VMA (Que es la dirección virtual del segmento) con Size, lo cual nos dará el resultado de la ultima dirección en la cual acaba el segmento .rodata, y asi podremos saber con exactitud si 0x0804bf2d se encuentra dentro (VMA + Size): $ gdb q (gdb) p/x 0x0804b480+0x00000aad $1 = 0x804bf2d Como podemos ver, el resultado de VMA + Size = 0x0804bf2d, acaba justamente donde empieza a ejecutarse nuestro código, por lo tanto no se encuentra adentro de ninguna sección!, Que raro... memoria no localizada, desde aquí ya huele a virus. El problema ahora es que no va a ser fácil desensamblar esta dirección, ya que objdump desensambla de acuerdo a la memoria localizada en secciones, sin embargo IDA debería hacer el truco, pero... por alguna razón al estar haciendo pruebas y analizar profundamente las posibilidades de poder lograr esto, no funcionó, esta dirección como ya vimos no esta localizada dentro
ninguna sección por lo tanto confunde a los desensambladores ya que su análisis de los binarios ejecutables ELF se basa de acuerdo a la cabecera de Program Header Table. Por lo tanto, utilice gdb para desensamblar esta parte del código: Bien, por fin pude obtener el código escondido, sin embargo, como se puede apreciar, no luce tan lindo como si lo hubiera hecho en IDA, aparte de que va a dar algunos problemas y no va a ser fácil de revertir, por lo tanto, tuve que pensar en alguna otra solución. La segunda solución que vino a mi mente fue simplemente: “Porque no saco solo el código escondido y lo veo con ndisasm[3]?”, por esta razón cree un código en C (el cual pueden encontrar en las referencias como rodata_to_data.c) el cual abre el fichero binario, localiza el código que se encuentra entre .rodata y .rdata y lo imprime en pantalla:
Bien, aquí otra vez, pude lograr obtener el código de una forma totalmente diferente, sin embargo, aun me sigue pareciendo un código difícil de seguir, por lo cual tuve que buscar aun otra solución La tercera solución que vino a mi mente fue la mejor pero la mas complicada, lo que hice fue crear un nuevo código, el cual cuando le pasabas como argumento el binario, leía la aplicación, utilizaba elf.h para buscar la locación de .rodata y .data, después de esto calculaba información como cuantos bytes había entre uno y el otro (Calculaba la memoria no localizada), y modificaba el Elf32_Shdr de .rodata para que .rodata tuviera su tamaño MAS el tamaño que había enmedio (Este código se encuentra en las Referencias con el nombre change_rodata_size.c):
Como pueden ver, .rodata fue modificado, el tamaño ahora es mucho mayor y cubre toda la información que
faltaba, por lo tanto ahora los desensambladores que estoy utilizando deben analizar esta porción de
memoria.
Ahora si, como se ve en el ejemplo siguiente, IDA Pro pueden desensamblar este código a la perfección.
; ÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛ S U B R O U T I N E ÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛ
public start
start proc near
[1] jmp short loc_804BF4E
; ÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄ
db 4Fh ; O
db 53h ; S
db 46h ; F
...
Esta subrutina es el empiezo de el bloque de memoria el cual no estaba localizado dentro de ninguna
sección, como podemos ver en [1], lo que hace únicamente esta subrutina es saltar a loc_804BF4E.
El bloque de código es bastante extenso y me tomo varias horas analizarlo, entenderlo y revertirlo, todo el
código del bloque del virus que muestre de aquí en adelante puede ser visto en
http://genexx.org/pubs/iil/virus.asm , siendo el análisis de IDA Pro de la porción de código del virus, el
primero el código original que se genera.
Por la razón anteriormente dada no pienso poner en este documento el análisis del código desensamblado
comentado y modificado por mi ya que tomaría bastante tiempo, por lo tanto solo imprimiré una porción del
mismo. El código analizado extensamente lo pueden encontrar en
http://genexx.org/pubs/iil//virus.analizado.asm; ÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛ S U B R O U T I N E ÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛ
; Attributes: bpbased frame
osf_startup proc near ; CODE XREF: start+27^Xp
var_1018 = dword ptr 1018h
var_100C = dword ptr 100Ch
var_1004 = dword ptr 1004h
var_1000 = dword ptr 1000h
push ebp
mov ebp, esp
sub esp, 100Ch
push edi
push esi
push ebx
call sub_804CD01 ; char var_80[128];
test eax, eax ; if(eax == 0)
jz short salir ; salir();
lea eax, [ebp+var_1004] ; eax = var_1004;
push eax
call carga_payload ; carga_payload(&var_1004);
[...]
; ÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛ S U B R O U T I N E ÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛ
; Attributes: bpbased frame
carga_payload proc near ; CODE XREF: osf_startup+1C^Yp
var_488 = dword ptr 488h
var_478 = dword ptr 478h
var_474 = dword ptr 474h
var_468 = dword ptr 468h
var_440 = dword ptr 440h
var_42C = dword ptr 42Ch
var_400 = dword ptr 400h
arg_0 = dword ptr 8
push ebp
mov ebp, esp
sub esp, 47Ch
push edi
push esi
push ebx
mov [ebp+var_478], 0 ; var_478=0;
lea esi, [ebp+var_400] ; esi = var_400;
push 400h
push esi
push 0call decifra ; decifra(0,&var_400,1024); // 0 = /proc/
mov edi, esi ; edi = var_400; ("/proc/")
xor eax, eax ; eax = 0;
cld
mov ecx, 0FFFFFFFFh
repne scasb
not ecx
lea ebx, [esi+ecx1] ; ebx = strlen(var_400);
push 14h
call sub_804BF89 ; syscall getpid();
mov edx, eax ; edx = getpid();
push edx
call lennumeros ; 1 = 1, 11 = 2, 111 = 3, etc. en eax.
mov edx, eax ; edx = lennumeros(getpid());
mov edi, esi ; edi = var_400
xor eax, eax ; eax = 0;
cld
mov ecx, 0FFFFFFFFh
repne scasb
not ecx
lea ecx, [esi+ecx1] ; ecx = strlen(esi)
add edx, ecx ; edx = strlen(var_400) + strlen(lennumeros(getpid()));
push 5
push edx
push 1
call decifra ; decifra(1,edx,5); // 1 = /exe
add esp, 20h
push ebx
push 14h
call sub_804BF89 ; syscall getpid()
add esp, 4
mov edx, eax ; edx = getpid();
push edx
call concatena ; esi = "/proc" + str(getpid()) + "/exe"
push 0
push 0
push esi
push 5
call syscall_ejecuta
mov ebx, eax ; ebx = eax = open(esi,O_RDONLY);
add esp, 18h
test ebx, ebx ; if(ebx != 0) {
jl salir ; if(ebx == 1) {
push 34h
lea eax, [ebp+var_474]
push eax
push ebx
call lee ; eax = lee_header(ebx,eax,0x34); (var_468 = offset)
add esp, 0Ch
[...]; ÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛ S U B R O U T I N E ÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛÛ
; Attributes: bpbased frame
decifra proc near ; CODE XREF: carga_payload+24^Yp
; carga_payload+65^Yp ...
var_10 = dword ptr 10h
caracter = byte ptr 4
saltocuenta = dword ptr 8
buffer = dword ptr 0Ch
len = dword ptr 10h
push ebp
mov ebp, esp
sub esp, 4
push edi
push esi
push ebx
mov ebx, [ebp+saltocuenta] ; ebx = saltocuenta;
call sub_804C20D
mov esi, eax ; esi = ptr to “\x20\x7f\x7d\x60\x6c\x20\x00\x20\x6a\x77\x6a\x00...”
test ebx, ebx ; if(ebxcld ; limpia la flag de direccion
mov ecx, 0FFFFFFFFh
repne scasb
not ecx
dec ecx ; ... = ecx = strlen(esi);
mov eax, [ebp+len] ; eax = len
cmp ecx, eax ; if(strlen(esi) < len)
ja short algoritmo_enc ; goto algoritmo_enc;
mov edi, esi
xor eax, eax
cld
mov ecx, 0FFFFFFFFh
repne scasb
not ecx
loc_804C295: ; ebx = strlen(esi) (codigo encriptado);
lea ebx, [ecx1] ; goto loc_804c2a0;
jmp short loc_804C2A0 ; ecx = 0;
; ÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄ
db 8Dh ; ~M
db 76h ; v
db 0
; ÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄ
algoritmo_enc: ; CODE XREF: decifra+48^Xj
mov ebx, [ebp+len]
oc_804C2A0: ; CODE XREF: decifra+5B^Xj
xor ecx, ecx ; ecx = 0;
cmp ecx, ebx ; if(ebxsalir: ; CODE XREF: decifra+67^Xj
lea esp, [ebp10h]
pop ebx
pop esi
pop edi
leave
retn
decifra endp
Aquí acaba la explicación del código, como pueden ver, el análisis es diferente al que normalmente genera
IDA, ya que las rutinas tienen nombres, y existe código comentado que parece “Pseudocodigo” de C, todo
esto lo hice yo, es la forma en la que voy comentando el código y lo voy entendiendo, posiblemente existan
algunos errores dentro de los comentarios, pero son insignificantes ya que no estamos revirtiendo el análisis
a C directamente.
Como pudieron notar, esto es una peque~a parte del código del virus OSF, y si revertimos este código a C
quedaría algo parecido a esto:
#include
void decripta(int saltos, char *buffer, int len) {
char *enc =
"\x20\x7f\x7d\x60\x6c\x20\x00"
"\x20\x6a\x77\x6a\x00"
"\x20\x7f\x7d\x60\x6c\x20\x7a\x7f\x7b\x66\x62\x6a\x00"
"\x62\x6a\x00"
"\x20\x6d\x66\x61\x00";
int cuenta;
char caracter;
for(;saltos;saltos,enc++) {
while(*enc) enc++;
}
memset(buffer,0,len);
for(cuenta=0;cuentaint lennumeros(char *buffer) {
int len = 0;
while(isdigit(*buffer) && *buffer) {
buffer++;
}
return len;
}
Para probar si la función de descifrado fue revertida realmente, podemos agregar main() y probarlo
directamente:
...
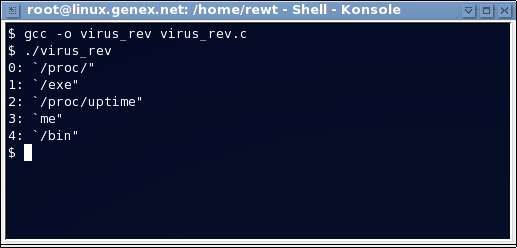
int main(void) {
char buffer[128];
int fd;
decripta(0,&buffer[0],128);
printf("0: `%s\"\n",buffer);
decripta(1,&buffer[0],128);
printf("1: `%s\"\n",buffer);
decripta(2,&buffer[0],128);
printf("2: `%s\"\n",buffer);
decripta(3,&buffer[0],128);
printf("3: `%s\"\n",buffer);
decripta(4,&buffer[0],128);
printf("4: `%s\"\n",buffer);
return 0;
}
Y ejecutándolo:Como podemos ver, hemos completado el análisis del programa que nos pusimos como objetivo. 9. Conclusiones Haré una conclusión corta: Espero que este documento le haya servido al lector para cualquier utilidad que le pueda o quiera dar a la ingeniería inversa. En realidad, aun cuando el documento no es corto, sigue siendo una introducción, existen varios temas, técnicas y formas los cuales no fueron tratados. La ingeniería inversa comúnmente no es algo fácil de aplicar, crear un documento completo implicaría enseñar temas los cuales podrían ser de tamaños inmensos, por esta misma razón, en este documento he tratado de simplificar, aclarar y sintetizar el tema. Cualquiera que sea la razón del lector por la cual llego a este documento, espero que haya encontrado este tema interesante y trate de alimentarse con mas información. 10. Referencias 1. “The Executable and Linking Format (ELF)” http://www.cs.ucdavis.edu/~haungs/paper/node10.html 2. “DataRescue IDA Pro” http://www.datarescue.com/idabase/ 3. “IDA Pro Freeware version download” http://www.themel.com/ida.html 4. “rodata_to_data.c” http://genexx.org/pubs/iil/rodata_to_data.c 5. “change_rodata_size.c” http://genexx.org/pubs/iil/change_rodata_size.c 6. “Reverse Code Engineering Community” http://www.reverseengineering.net/ 15. Información de Contacto Gracias al lector por tomarse el tiempo para leer este documento el cual siempre pueden encontrar en linea en el enlace http://genexx.org/pubs/iil/IIL.pdf Cualquier duda, pregunta, comentario, información o critica, me pueden contactar de la forma que gusten: Nombre: Diego Bauche Madero Edad: 18 Residencia: Guadalajara, Jal. México Pagina Web: http://genexx.org/ EMail: diego.bauche@genexx.org MSN: diego.bauche@genexx.org AIM: dexosexo1 Información Legal: ESTE DOCUMENTO ES PROPIEDAD DE Diego Bauche Madero El contenido de este archivo no puede ser modificado en forma total ni parcial sin la previa autorización del autor. Este documento puede ser distribuido libremente con previa notificación al autor.
También puede leer

















































