FACULTAD DE ESTUDIOS ESTADÍSTICOS - MÁSTER EN MINERÍA DE DATOS E INTELIGENCIA DE NEGOCIOS - E-Prints ...
←
→
Transcripción del contenido de la página
Si su navegador no muestra la página correctamente, lea el contenido de la página a continuación
FACULTAD DE ESTUDIOS ESTADÍSTICOS MÁSTER EN MINERÍA DE DATOS E INTELIGENCIA DE NEGOCIOS Curso 2020/2021 Trabajo de Fin de Máster TITULO: Estudio de predicción en la radicación de quejas y reclamos por parte de usuarios inconformes en empresa de sanidad colombiana. Alumno: Paula Juliana Miranda Gualdrón Tutor: Antonio Sarasa. Julio de 2021
AGRADECIMIENTOS A Dios y a la vida por haberme dado esta oportunidad de estudiar y vivir en el extranjero. Esta experiencia me ha ayudado no solo a enfocar mi perfil profesional, sino a darme una visión con respecto a niveles de desarrollo de los países europeos con respeto a los países latinoamericanos. También agradezco a la Universidad Complutense por haberme admitido al programa del máster y a todos los docentes que impartieron las asignaturas del mismo. Agradezco por su labor de docentes y el esfuerzo adicional que han tenido que realizar en estos tiempos de pandemia. A mi asesor de trabajo, Antonio, por tomarse su tiempo en dirigirme y acompañarme durante este proceso para poder culminar el máster. 2
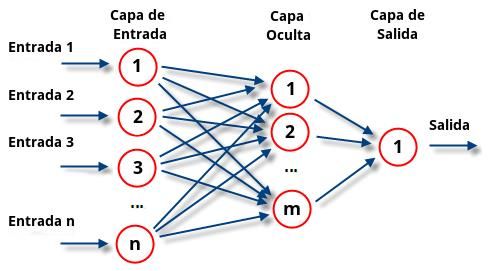
TABLA DE CONTENIDO 1. INTRODUCCION ................................................................................................... 7 2. DESCRIPCIÓN DEL PROBLEMA .......................................................................... 9 2.1 Planteamiento del problema. ........................................................................ 9 2.2 Formulación del problema .......................................................................... 10 3. OBJETIVOS ........................................................................................................ 10 3.1 General ...................................................................................................... 10 3.2 Específicos ................................................................................................ 10 4. MARCO TEORICO .............................................................................................. 10 4.1 Estado del Arte........................................................................................... 10 4.2 Metodología SEMMA.................................................................................. 12 4.3 Algoritmos de predicción ............................................................................ 13 4.3.1 KNN .................................................................................................... 13 4.3.2 Regresión logística .............................................................................. 14 4.3.3 Redes neuronales ............................................................................... 15 4.3.4 Arboles de clasificación y regresión ..................................................... 16 4.3.5 Bagging y Random Forest ................................................................... 17 4.3.6 Gradient Boosting ................................................................................ 18 4.3.7 Ensamblado ........................................................................................ 19 4.3.8 Medidas de evaluación de modelos ..................................................... 19 5. DESARROLLO DEL TRABAJO ........................................................................... 20 5.1 Análisis descriptivo del conjunto de datos ................................................... 21 5.2 Depuración de datos .................................................................................. 25 5.2.1 Tipos de variable y roles ...................................................................... 25 5.2.2 Corrección de errores, datos atípicos y faltantes. ................................. 26 5.2.3 Transformación y selección de variables .............................................. 27 5.3 Modelos predictivos .................................................................................... 30 5.3.1 KNN .................................................................................................... 30 3.3.2 Regresión Logística ............................................................................. 32 3.3.3 Redes ................................................................................................. 32 3.3.4 Bagging y Random Forest ................................................................... 34 3.3.5 Gradient Booting ................................................................................. 38 3.3.6 Ensamblado ........................................................................................ 41 4 ANALISIS DE RESULTDOS ................................................................................ 44 5 CONCLUSIONES Y TRABAJOS FUTUROS ........................................................ 47 6. BIBLIOGRAFIA.................................................................................................... 48 7. ANEXOS ............................................................................................................. 49 7.1 Anexo 1 – Reagrupación de variables categóricas. ..................................... 49 7.2. Anexo 2 – Códigos R utilizados .................................................................. 65 3
INDICE DE FIGURAS Figura 1. Representación sistema sanitario en Colombia ........................................................... 7 Figura 2. Fases de la metodología SEMMA ............................................................................. 12 Figura 3. Algoritmo del vecino próximo. ................................................................................... 13 Figura 4. Representación modelo de regresión logística .......................................................... 14 Figura 5. Funcionamiento modelo de Redes Neuronales ......................................................... 15 Figura 6. Ejemplo formulación de una red neuronal ................................................................. 16 Figura 7. Estructura básica de los modelos de árboles. ........................................................... 17 Figura 8. Estructura básica de modelos de Bagging y Rf ......................................................... 17 Figura 9. Algoritmo de Ensamblado ......................................................................................... 19 Figura 10. Funcionamiento matriz de confusión ....................................................................... 20 Figura 11. Interpretación Curva ROC ....................................................................................... 20 Figura 12. Estadísticos descriptivos variable de intervalo......................................................... 25 Figura 13. Estadísticos variables de clase................................................................................ 26 Figura 14. Niveles reducidos variables categóricas .................................................................. 27 4
INDICE DE GRÁFICOS Gráfico 1. Cantidad de quejas por Sitio de Recepción. ............................................................ 22 Gráfico 2. Cantidad de quejas por Medio de Recepción. .......................................................... 22 Gráfico 3. Radicación de quejas por Género ............................................................................ 23 Gráfico 4. Histograma de edades ............................................................................................. 23 Gráfico 5. Cantidad de quejas por Sucursal ............................................................................. 23 Gráfico 6. Causas más comunes en la radicación de quejas.................................................... 24 Gráfico 7.Solucion de quejas fuera o dentro de tiempo. ........................................................... 25 Gráfico 8. Estadístico V de Cramer .......................................................................................... 27 Gráfico 9. Curva ROC modelos KNN para variables SAS6 ...................................................... 31 Gráfico 10. Boxplot training test KNN ....................................................................................... 31 Gráfico 11. Tasa de Fallos modelos Regresión Logística ......................................................... 32 Gráfico 12. Tasa de Fallos Modelos de Redes Neuronales ...................................................... 33 Gráfico 13. Tasa de Aciertos Redes Neuronales ...................................................................... 34 Gráfico 14. Error Obb Early Stopping ....................................................................................... 35 Gráfico 15. AUC modelos Bagging ........................................................................................... 36 Gráfico 16. Tasa de fallos modelos Bagging ............................................................................ 36 Gráfico 17. AUC modelos de Random Forest .......................................................................... 37 Gráfico 18. Tasa de Fallos modelos de RF .............................................................................. 38 Gráfico 19. Tuneo parámetros Gbm ......................................................................................... 39 Gráfico 20. Tuneo Early Stopping Gmb. ................................................................................... 40 Gráfico 21. Tasa fallos modelo Gbm ........................................................................................ 40 Gráfico 22. AUC Modelos de ensamblado................................................................................ 42 Gráfico 23. Tasa de Fallos ensamblados ................................................................................. 42 Gráfico 24. Mejores modelos de ensamblado .......................................................................... 43 Gráfico 25. Gráfico de calor mejores combinaciones de modelos ............................................ 43 Gráfico 26. Importancia de las variables modelo ganador ........................................................ 44 5
INDICE DE TABLAS Tabla 1. Usuarios afiliados a la compañía y tutelas radicas. ...................................................... 9 Tabla 2. Resultados estudio de enfermedad mentales ............................................................. 11 Tabla 3. Descripción de las Variables ...................................................................................... 21 Tabla 4. Sucursales con más radicación de quejas. ................................................................. 24 Tabla 5. Asignación de roles y clasificaciones de variables ...................................................... 25 Tabla 6. Reagrupación de niveles de la variable Causa ........................................................... 26 Tabla 7. Listado Selección de variables ................................................................................... 29 Tabla 8. Resultados modelos KNN .......................................................................................... 30 Tabla 9. Matriz de confusión modelo ganador KNN ................................................................. 31 Tabla 10. Parámetros y modelos de redes ............................................................................... 33 Tabla 11. Tuneo para modelos de Bagging y RF ..................................................................... 34 Tabla 12. Parámetros modelos de Bagging.............................................................................. 35 Tabla 13. Modelos de Random Forest ..................................................................................... 37 Tabla 14. Tuneo de parámetros GBM ...................................................................................... 38 Tabla 15. Tuneo early stopping Gbm ....................................................................................... 39 Tabla 16. Modelos Gmb ........................................................................................................... 40 Tabla 17. Modelos Ensamblados ............................................................................................. 41 Tabla 18. Comparativo de todos los modelos........................................................................... 44 Tabla 19. Top 20 importancia de las variables modelo ganador ............................................... 45 6
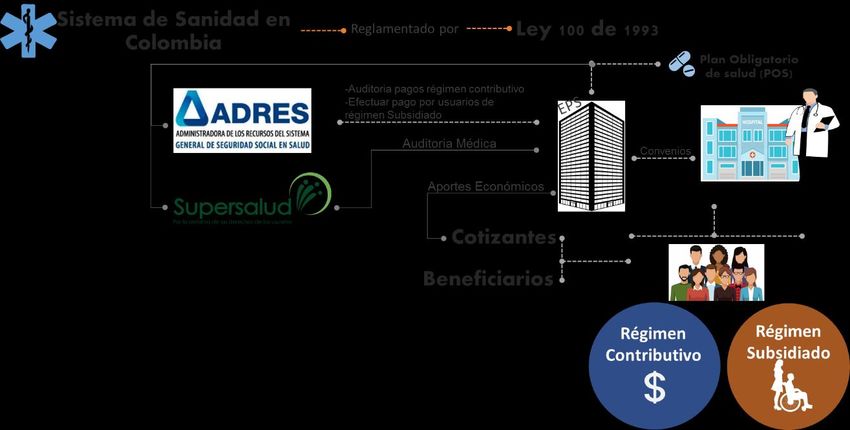
1. INTRODUCCION Las compañías que laboran en cada uno de los diferentes sectores empresariales cuentan con una probabilidad de que sus clientes al estar inconformes con la prestación del servicio o del producto, radiquen quejas o reclamos expresando su desacuerdo con el bien o servicio adquirido. Las empresas deben entonces gestionar lo más pronto posible estas inconformidades a fin de satisfacer plenamente a sus clientes y evitar futuros problemas como perdida de este, mala imagen para la compañía y la no llegada de nuevos clientes. Este problema es de vital importancia cuando el sector en cuestión es la sanidad. Cuando se habla de quejas y reclamos en el sector de la salud, más allá de poner en juego la reputación de la compañía, el problema trasciende al poner en juego la vida de un paciente. Por esta razón, se vuelve prioridad gestionar a tiempo las quejas radicadas en este tipo de empresas. Este tema adquiere un poco más de complejidad cuando el foco de estudio son empresas de Sanidad Colombianas. La figura 1, permite visualizar de una forma gráfica como está constituido el sistema sanitario en Colombia. Figura 1. Representación sistema sanitario en Colombia El Sistema General de Salud Colombiano se encuentra reglamentado por la Ley 100 de 1993 el cual estable que todo ciudadano colombiano debe estar afiliado a la seguridad social bajo alguno de dos regímenes: Régimen Contributivo y Régimen subsidiado. - Régimen Contributivo: harán parte de este sistema todas las personas asalariadas, pensionados, autónomos y todo aquel que cuente con una capacidad de pago. El pago efectuado dependerá de su posición: un autónomo contribuirá al sistema con pagos mensuales cancelando la totalidad del valor. Un trabajador dependiente pagará el 4% de su salario mientras que el empleador contribuirá pagando un 8.5%, para un total de 12.5% de los ingresos laborales del empleado. - Régimen Subsidiado: harán parte de este sistema todas aquellas personas en situación de pobreza y que demuestren no tener capacidad de pago alguna para hacer parte del Régimen Contributivo. Este régimen es subvencionado en su totalidad por el Estado Colombiano por lo cual realizan procedimientos rigurosos para verificar que efectivamente las personas beneficiadas con este régimen estén en situación de vulnerabilidad. 7
La ley 100 también determina la creación de las Entidades Prestadoras de Salud (EPS). Estas instituciones se encargan de gestionar la vinculación de los ciudadanos a sus compañías y de brindar cobertura sanitaria a través de una de red de convenios con Hospitales, Instituciones Prestadoras de Salud (IPS) y Centros de salud. También tienen como función recaudar los montos pagados por los usuarios pertenecientes al régimen contributivo y hacer efectivo el pago a las instituciones con las cuales tiene convenio por los servicios otorgados a sus usuarios. También esta estipulado en dicha Ley que los usuarios de las EPS podrán ser Cotizantes o Beneficiarios. Un cotizante es la persona que efectúa los pagos a la entidad. Esta persona puede afiliar al sistema sanitario a su núcleo familiar, quienes recibirán el nombre de Beneficiarios. Por tanto, los Beneficiarios se benefician de los servicios de sanidad que presta la Entidad en razón de los pagos efectuados por el cotizante. Esto se puede realizar sin que el cotizante deba pagar valores adicionales por los beneficiarios. Cabe destacar que los beneficiarios del cotizante solamente pueden ser su cónyuge y sus hijos, siempre y cuando estos últimos sean menores de 25 años. Por otro lado, la ley permitió la creación de dos entidades encargadas de hacer seguimiento a las EPS y hospitales para velar por su correcto funcionamiento. • Por un lado, se tiene la entidad ADRES, encargada de hacer auditorias en cuestiones monetarias. Esta realiza seguimientos a los dineros recibidos por las EPS por parte de los usuarios pertenecientes al régimen contributivo, por otro lado, se encarga de girar dinero a estas entidades por los servicios otorgados a los usuarios del régimen subsidiado. • La segundad entidad es la Superintendencia de Salud (SuperSalud), encargada de realizar seguimiento en cuanto a los servicios médicos prestados a los usuarios. Su principal función es velar porque las EPS, hospitales y centros de salud cumplan con las normativas establecidas y eviten que estas instituciones vulneren los derechos de los ciudadanos al no prestarles la atención debida. Finalmente, el Ministerio de Salud anuncia cada año el Plan Obligatorio de Salud (POS). Este plan corresponde a un listado de medicamentos, exámenes y servicios básicos que deben otorgar las EPS a los usuarios sin ningún costo. Todo aquel medicamento recetado o examen solicitado por un medico que no se encuentre en la lista, deberá ser adquirido por cuenta propia del usuario. Teniendo en cuenta todo el anterior sistema, cuando un usuario radica una queja, entran en juego múltiples variables que deben ser analizadas para comprender en cual parte del sistema se ha presentado la falla. De esta manera una queja radicada por un usuario puede estar relacionada a un sinfín de motivos: problemas con entrega de medicamentos o servicios del POS, mala calidad en los servicios prestados por los hospitales o centro de salud en convenio, atención recibida por parte del personal tanto de la EPS como de los centros de Salud, problemas con los aportes pagados por parte de los cotizantes etc. Se vuelve primordial para una EPS gestionar estas reclamaciones para evitar que puedan llegar a la SuperSalud, ya que, de ser así puede acarrear sanciones monetarias para la compañía, además de esfuerzos adicionales debido a que su solución será por vías legales. Es por esto, que un estudio a fondo sobre las quejas radicadas por los usuarios puede ser una gran ayuda para identificar los puntos en los que está fallando la prestación del servicio para plantear acciones correctivas y preventivas en el debido tiempo. En el siguiente trabajo se analiza un set de datos de quejas radicadas por usuarios en el año del 2016 en una EPS Colombiana. Se analizan los principales factores por los cuales se realizan las reclamaciones, además de hacer un estudio predictivo para determinar si las quejas fueron atendidas en el tiempo estipulado por los procesos de la compañía. 8
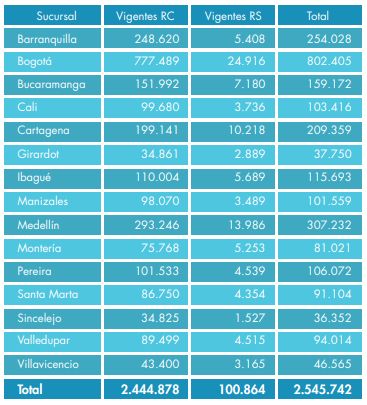
2. DESCRIPCIÓN DEL PROBLEMA 2.1 Planteamiento del problema. El análisis de las quejas para una compañía es de vital importancia por muchas razones, una de ellas está estrechamente relaciona con la satisfacción del cliente. Cuando un cliente está inconforme con un producto adquirido o un servicio contratado este realizara reclamaciones a la compañía ya que sus expectativas no fueron cumplidas del todo. Se convierte entonces en una carrera contra reloj para las compañías, dar una respuesta inmediata y tratar de solventar las insatisfacciones de los clientes con el fin de evitar que se vea afectada directamente la buena imagen de la compañía y por otro lado también para evitar posibles sanciones por entes gubernamentales que puedan terminar en considerables multas. El portal (Icorp, 2021) indica que las quejas son también un elemento que ayuda a la mejora continua. Un cliente inconforme permite visualizar en cuales cosas está fallando la compañía lo que permitirá establecer planes de acción para erradicarlas o tratar de mitigarlas. Estos conceptos de quejas se convierten en un pilar crucial a la hora de hablar de compañías de salud ya que en ellas se ve involucrado directamente el bienestar de las personas. No atender una queja relacionada con una autorización de algún tratamiento de alto costo, realizar el proceso de cirugías, autorización para adquisición de medicamento, implica el avance de una enfermedad que puede terminar en la muerte del paciente. De acuerdo con los reportes de gestión de la compañía del año 2016 la empresa contaba con un total de 2.545.742 de afiliados, de estos el 96.03% se encontraban dentro del Régimen contributivo. La tabla 1 muestra la distribución de usuarios por sucursal, pertenecientes cada tipo de régimen. Teniendo en cuenta el total de quejas radicadas por los usuarios, el cual fue de 146.242, se identifica que el 5.74% de los usuarios radicaron quejas ante la compañía. Tabla 1. Usuarios afiliados a la compañía y tutelas radicas. Total usuarios afiliados por sucursal y régimen Tutelas presentadas Por otro lado podemos apreciar que un total de 13.264 tutelas* fueron radicadas por los usuarios ante la Súper intendencia de Salud. Esto representa para la compañía el inicio de un proceso judicial arduo si las dos partes no lleguen a un mutuo acuerdo. Por otro lado, de acuerdo con el informe anual, fueron presentadas 14.231 quejas ante el mismo ente gubernamental. *tutela: mecanismo previsto en el artículo 86 de la Constitución Política de Colombia, que busca proteger los Derechos fundamentales de los individuos "cuando cualquiera de éstos resulte vulnerados o amenazados por la acción o la omisión de cualquier autoridad pública" 9
Con estas cifras reales podemos corroborar otra importancia de la gestión temprana de quejas, el no hacerlo puede acarrear que el usuario acuda ante estos entes de control lo cual desencadena para la compañía muchos costos adicionales, auditorias y retrasos en los procesos. 2.2 Formulación del problema Partiendo de las anteriores premisas relacionadas con la radicación de quejas, se establece conveniente el planteamiento de alunas preguntas de instigación: - ¿Cuáles son los principales motivos en la radicación de quejas? - ¿Cuáles son las ciudades en las que más quejas se radica en la compañía? - ¿Cuáles son las áreas responsables de los procesos involucrados en las quejas radicadas? - ¿Qué factores intervienen para que una queja no sea atendida a tiempo? 3. OBJETIVOS 3.1 General El siguiente trabajo tiene como principal objetivo desarrollar un modelo predictivo que permita definir si una queja radicada por un usuario será solucionada a tiempo o no en una empresa de sanidad colombiana, analizando diferentes factores que intervienen no solo en la compañía. 3.2 Específicos - Determinar cuáles son las variables que intervienen en la tardanza para dar solución a las quejas radicadas. - Evaluar el poder de predicción de estas variables sobre la solución de las quejas ejecutando diferentes modelos para evaluar su comportamiento en cada uno de estos. - Comparar los diferentes modelos a fin de determinar con cual modelo se logra una mejor predicción a través de diferentes índices de medición. 4. MARCO TEORICO 4.1 Estado del Arte La minería de datos es un campo de la estadística ampliamente utilizado para hallar patrones de comportamiento en grandes conjuntos de datos, con el fin de tomar decisiones que permitan mejorar los procesos de las compañías o bien encaminar estrategias para un mejoramiento de la marca en el mercado. La flexibilidad de los métodos de la minería de datos permite que puedan ser utilizados en cualquier sector empresarial para analizar cualquier tipo de problemática. Uno de los sectores en los cuales es ampliamente utilizado es el sector de la salud. (De Hond, y otros, 2021) Desarrollaron un estudio en el cual analizaron bases de datos de unidades de urgencias de tres hospitales de Holanda, con el objetivo de estudiar modelos de machine learning que lograran predecir si un paciente seria hospitalizado o no. El estudio fue desarrollado teniendo en cuenta el tiempo que tardaba cada paciente en las unidades de urgencias después de realizado el triage, analizando los resultados del mismo y resultados de laboratorios de aquellos pacientes a los que autorizaban exámenes adicionales. Desarrollaron modelos de Random Forest, XGBoost y redes para compararlos con el modelo de regresión logística convencional. Se compararon los rendimientos de los modelos a través del área bajo la curva ROC. De los 172104 pacientes en urgencias solo el 39% fueron hospitalizados. Todos los modelos probados arrojaron excelentes resultados, con valores de AUC superiores a 0.82, pero no mostraron mucha mejoría en el rendimiento con respecto a la regresión. Se logró identificar con el estudio que los médicos tomaban la decisión de cuales pacientes hospitalizar y cuales no en un lapso inferior a 30 minutos, demostraron que los resultados de laboratorio no eran cruciales para la toma de esta decisión. 10
Este es un claro ejemplo de la utilidad y la importancia de realizar estos estudios de análisis de datos, ya que permiten mejorar acelerar procesos en los cuales interviene la vida de cientos de personas. (Srividya, Mohanavalli, & Bhalaji, 2018) Realizaron en su investigación un estudio de algoritmos de predicción de aprendizaje automático a fin de predecir la aparición de enfermedades mentales El estudio se desarrolló sobre tres grupos de estudio: estudiantes de secundaria, universitarios y profesionales que se encontraban trabajando. Para recopilar la información para el estudio, los autores desarrollaron una encuesta que consistía en 20 preguntas. Cada pregunta contaba con 5 posibles respuestas, clasificadas de 1 a 5 (casi nunca, a veces, a menudo, muy a menudo y casi siempre). Se aplicó a un total de 656 individuos y se realizó una clasificación para establecer cuáles de ellos eran propensos a sufrir de enfermedades mentales, clasificando cada una de las respuestas en tres grupos diferente: personas felices, neutrales o propensas a enfermedades. A continuación, desarrollaron modelos de machine learning para determinar qué tan acertados eran los modelos para predecir los casos positivos. De esta menara desarrollaron modelos de Regresión logística, Naïve bayes, SVM, Árbol de decisión y KNN, Bagging y Random Forest. De estos modelos se obtuvieron los resultados de la tabla 2: Tabla 2. Resultados estudio de enfermedad mentales Se puede observar como el modelo de SVM, Bagging y Random Rofest obtuvieron los mejores resultados. Se evidencia que, al implementar estos algoritmos en tiempo real, beneficiarán a la sociedad al servir como una herramienta de monitoreo para las personas con tendencias a sufrir problemas de estabilidad mental. Prediction of early childhood obesity with machine learning and electronic health record data (Xueqin, Forrest, Masino, & Le-Scherban, 2021) es otro claro ejemplo de la aplicación de las técnicas de minería de datos. En este estudio los autores desarrollaron 7 modelos de machine learning con los cuales pretendían predecir los índices de obesidad infantil en niños de 2 a 7 años. La base de datos utilizada fue tomada del Hospital Infantil de Filadelfia contaba con más de 11 millones de registros correspondientes visitas médicas de más de 850 mil niños de la ciudad. Se desarrollaron modelos de Regresión Logística (RL), Arboles de decisión (DT), Gaussian Naive Bayes (GNB), Bernoulli Naive Bayes (BNB), Redes Neuronales (NN) Suport Vector Machine (SVM) y XGBoost. Para realizar validación de los modelos realizaron repeticiones Monte Carlo donde se arrojaron niveles de AUC superiores a 0.76. Se demuestra que el mejor modelo de predicción correspondió al XGBoost el cual contó con un área bajo la curva de 0.81. Finalmente podemos observar que la minería de datos no solamente es aplicable para los campos de modelos de predicción, los algoritmos también pueden ser utilizados para el análisis de texto a través de algoritmos de estudio como text-mining, en los cuales se realiza minería de datos sobre cadenas de texto a fin de encontrar patrones clave en los textos registrados. 11
Un ejemplo aplicado para esto fue desarrollado por (Lee, Levin, Finley, & Heilig, 2019) en esta investigación se analizó una base de datos procedente del departamento de Salud e Higiene Mental de la ciudad de Nueva York en el año de 2016 la cual contaba con 2,1 millón de registros correspondientes a visitas de pacientes a las unidades de urgencias. La base de datos contaba con información demográfica del paciente, y tres campos clave de estudio: queja principal (CC), diagnóstico de alta (DD) y código del diagnóstico (ICD). Desarrollaron modelos de redes neuronales basados en células de memoria a corto-largo plazo (LSTM) y modelos de unidades recurrentes cerradas (GRU) los cuales fueron comprados con dos modelos clásicos de análisis (MNB) y SVM. Los cuatro modelos fueron programados para predecir los tres campos de estudio clave (CC, DD, ICD). Se establecen las siguientes conclusiones: • El modelo LSTM funciona mejor cuando para predecir los diagnósticos de alta (DD) • El modelo GRU funciona mejor para predecir quejas principales (CC) • Dentro de los aspectos a evaluar, algunos síndromes son más fáciles de predecir que otros. Por ejemplo, con el modelo GRU los trastornos relacionados con el alcohol son más fáciles de detectar que los casos de influenza • Los modelos RNN (Recurrent Neural Network) 4.2 Metodología SEMMA Dentro del mundo de la minería de datos se han establecido metodologías que permiten llevar a cabo las tareas de análisis y detección de patrones de comportamiento, a través de procesos estandarizados manejados con determinados lineamientos. Dentro de estas metodologías encontramos la metodología SEMMA y CRIPS-DM. Ambas metodologías manejan tareas semejantes la diferencia radica que CRISP-DM realiza un estudio previo al análisis de los datos para entender el negocio sobre el cual se desarrollara el proyecto, estableciendo objetivos claros y una perspectiva desde el punto de vista del negocio. SEMMA es una metodología desarrollada por SAS Instittue y a diferencia de CRISP-DM cuenta con aspectos muy técnicos que no tienen en cuenta el problema del negocio o una comprensión profunda del problema que se está abordando. La figura 2 muestra las fases de esta metodología. Se puede observar que la palabra SEMMA es un acrónimo del nombre recibido por cada fase. Figura 2. Fases de la metodología SEMMA Sample Explore Modify (Muestreo) (Exploración) (Modificación) Model Assess (Modelado) (Valoración) • Sample (Muestreo): En esta primera fase se realiza una muestra a través de la extracción de un subconjunto de datos significativo que contenga información 12
relevante sobre el comportamiento del caso en estudio. Realizando esta muestra las empresas ahorran costos y tiempos de procesamiento de los datos. Es recomendable en esta fase hacer una separación de los datos entre entrenamiento, validación y prueba. • Explore (Exploración): A través de técnicas estadísticas se buscan tendencias en los datos, identificando datos atípicos en cada una de las variables y anomalías presentes en los datos. • Modify (Modificación): Fase en la cual se realiza una selección de variables para encontrar aquellas que tengan más afinidad con el objetivo, además de transformar los datos para que estén encaminados al proceso de modelado. • Model (Modelado): Aplicar determinados algoritmos haciendo uso de software estadístico, que permitan predecir con un nivel alto de confianza los resultados deseados. • Assess (Valoración): Evaluar los resultados obtenidos del modelo anterior. A partir de los datos prueba, ejecutar el modelo ganador para verificar el éxito en las predicciones. Si los resultados son favorables se procede a implementar el modelo en el desarrollo de la empresa, de lo contrario de debe desarrolla otro modelo. 4.3 Algoritmos de predicción 4.3.1 KNN Metodología conocida por su nombre K Nearest Neighbours. Es un algoritmo de aprendizaje supervisado lo cual indica a partir de unos datos iniciales su objetivo será clasificar de forma correcta nuevos datos que ingresen al sistema. El algoritmo funciona por medio de una premisa básica, los valores a predecir los calcula en base a una densidad de probabilidad, por tanto, se asume que los nuevos valores entrantes, que tengan comportamiento similar en las variables input a los ya existentes, tomará los mismos valores en la función objetivo. Se tiene una variable objetivo de clasificación en donde se identifica si una observación es catalogada como roja o azul. Al momento de evaluar un nuevo elemento, se calculan las distancias entre ese punto y los ya existentes. La figura 3 permite visualizar la explicación sobre el funcionamiento del algoritmo. Figura 3. Algoritmo del vecino próximo. 13
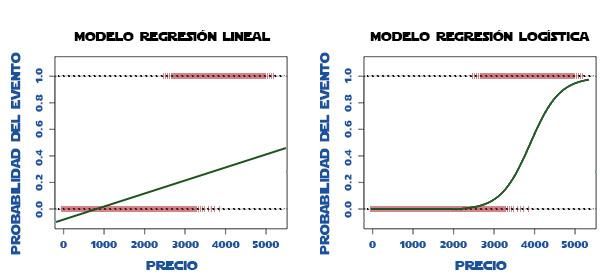
Si nos enfocamos en los tres vecinos más cercanos (K=3) es posible notar que hay más presencia de elementos rojos que azules, por tanto, la nueva observación será catalogada como roja. Para el cálculo de las distancias se utiliza como técnica más común las distancias Euclidianas a través de las coordenadas de cada punto entre el eje X y el eje Y. Debido a que cada variable input tendrá unidades de medición diferentes entre sí, es recomendable antes de ejecutar el modelo estandarizar todas las variables para que tengan los mismos pesos y así calcular las distancias entre observación de forma unánime. 4.3.2 Regresión logística Este modelo de regresión es de utilidad cuando la variable dependiente, es decir la variable objetivo es de tipo dicotómica, es decir que solamente toma dos categorías Si o No. El propósito del algoritmo es predecir la probabilidad de que ocurra un determinado evento (1) y de que no ocurra (0). De esta manera en un principio es posible ajustar el modelo a una regresión lineal para calcular la probabilidad de que una observación tome los valores de la variable objetivo. Sin embargo, trabajar con un problema de regresión lineal por sí solo, nos trae como resultado un recta donde las probabilidades podrán estar fuera de los rangos 0 y 1. Se busca entonces una función que permita obtener estas probabilidades transformadas dentro de los rangos mencionados y esta es la función logística. La figura 4 representa lo que sería el modelo por si solo de una regresión lineal y el modelo ajustado con la función logística Figura 4. Representación modelo de regresión logística Se determina entonces que la función de la regresión logística viene dada por una probabilidad de evento A y una probabilidad de evento B: 1 1 = ( = 1 | 1 , 2 , … ) = 1+ −( 0 + 1 1 +⋯+ ) −( 0 + 1 1 +⋯+ ) 0 = 1 − 1 = ( = 0 | 1 , 2 , … ) = 1 + −( 0 + 1 1 +⋯+ ) Estas funciones se pueden ajustar a través de una función logarítmica para obtener los Odds, los cuales se definen como la probabilidad de que ocurra un evento sobre la probabilidad de que no ocurra. 14
ln ( 1 ) = 0 + 1 1 1 − 1 Para el desarrollo de los modelos también es de vital importancia realizar una correcta selección de variables que permita tener en cuenta solo aquellas que guarden una estrecha relación con la variable objetivo. Se presentan 3 procesos para realizar selección de variables: • Forward: Este método consiste en introducir al modelo secuencialmente, una a una las variables que presenten mayor correlación con la objetivo hasta que no hayan variables que aporten información relevante al modelo. • Backward: El modelo inicia teniendo en consideración todas las variables del conjunto de datos y secuencialmente elimina una a una las variables para evaluar su impacto en el modelo. En cada etapa descarta las variables menos influyentes de acuerdo con resultados del test de la F o de la t. • Stepwise: Es una combinación de los dos métodos anteriores, durante el proceso se introducen variables de igual manera que modelo forward, con la diferencia que durante el proceso se pueden eliminar variables que no cuenten con un P-valor muy alto. El modelo termina cuando no encuentre variables que introducir o eliminar. También hay que tener en consideración indicar un número máximo de iteraciones para evitar que el proceso entre en un bucle introduciendo y eliminado las mismas variables una y otra vez. 4.3.3 Redes neuronales Este algoritmo se caracteriza por imitar el funcionamiento de las neuronas en el cerebro de los seres humanos. Cuentan con una estructura formada por nodos enlazados que transfieren señales entre sí. Estas señales se transmiten desde un nodo de entrada hasta un nodo de salida. El objetivo de las redes es lograr que estas aprendan a modificarse automáticamente para que puedan desarrollar tareas complejas que no pueden ser resultas por medio de la programación convencional. Las redes cuentan con una estructura básica, cuentan con unos nodos Input o de entrada, los cuales representan en un modelo de análisis de datos, las variables independientes. Cada entrada se conecta a un nodo perteneciente a una capa oculta, llamados neuronas. Cada una de las neuronas de la red, posee un peso que modifica la información recibida de los nodos de entrada. Los nuevos valores salen de las neuronas para continuar su camino por toda la red. Finalmente, los datos llegan a una capa de salida que corresponde a las predicciones realizadas por la red. A mayor cantidad de capas ocultas posea la red, más compleja será y los cálculos a realizar serán más difíciles de obtener. La figura 5 permite visualizar el funcionamiento de una red neuronal. Figura 5. Funcionamiento modelo de Redes Neuronales 15
El algoritmo realiza el siguiente proceso: • Cada nodo input ( 1 , 2 … ) se conecta a cada una de las neuronas de la capa oculta ( 1 2 … ). Cada unión cuenta con un peso, el cual es un valor que se debe estimar ( 1,1 , 1,2 … ). Esta unión se realiza a través de una función de combinación tipo lineal. Adicional a esto cada neurona cuenta con un parámetro de constante B • A continuación, en cada neurona de aplica una función de activación la más utilizada es la tangente hiperbólica. • Se aplica nuevamente una función de combinación de cada una de las neuronas al nodo de salida. De esta manera sí tomamos en consideración una red con tres nodos input, una capa oculta con dos neuronas y una salida como la que se evidencia en la figura 6, se obtendría una fórmula matemática del modelo como la que muestra a continuación: Figura 6. Ejemplo formulación de una red neuronal = tanh ( 1 (tanh( 11 1 + 21 2 + 31 3 + 1 )) + ( 2 (tanh( 12 1 + 22 2 + 32 3 + 2 )) + ) De esta manera, el cálculo computacional consistiría en hallar los parámetros w y B. Los valores van variando en cada una de las iteraciones hasta conseguir el modelo óptimo. Otro aspecto importante a tener en consideración para realizar modelos de redes consiste en evaluar diferentes combinaciones de parámetros que permitan obtener diferentes resultados. Dentro de los parámetros que son posibles modificar en cada modelo a realizar son: • Variables de clase a tener en cuenta en el modelo. Es posible no hacer uso de todas las variables dependiendo del proceso de selección realizado previamente. • Variables continúas a tener en cuenta en el modelo. Es posible no hacer uso de todas las variables dependiendo del proceso de selección realizado previamente • Numero de nodos. Hace referencia a la cantidad de neuronas a utilizar en la capa oculta. • Parámetro decay, el cual es un parámetro de regularización de los pesos w • Función de activación: función que se aplica en los nodos de la capa oculta. La más utilizada corresponde a la tangente hiperbólica • Algoritmo de aproximación el cual servirá para retocar los valores de los pesos w de tal manera que se minimice el error. 4.3.4 Arboles de clasificación y regresión Los árboles de regresión y clasificación son una poderosa técnica de predicción que se encuentra basado en la estructura de un árbol seco invertido. A través de múltiples bifurcaciones anidadas unas por debajo de las otras, obtenemos al final una predicción. Se habla de un árbol de clasificación cuando la variable objetivo es de tipo cualitativo, es decir que la predicción puede tomar una de dos opciones. Se trata de un árbol de regresión cuando la variable dependiente Y es de tipo cuantitativo, es decir se debe obtener un número real. 16
La figura 7 muestra la estructura de este modelo de predicción. El árbol parte de un nodo raíz ubicado en un primer nivel. A partir de este, se pueden desplegar nodos internos los cuales serán llamados hijos, estos nodos pueden seguir dividiéndose hasta llegar a unos nodos terminales. En el ejemplo de la figura se puede apreciar que en el segundo nivel hay un nodo interno, junto con un nodo terminar y en un tercer nivel solo hay presencia de dos nodos terminales. Figura 7. Estructura básica de los modelos de árboles. Los criterios de división del nodo raíz y de los nodos internos se dan teniendo en cuanta que ambos nodos resultantes sean heterogéneos entre ellos y homogéneos con la variable objetivo. De esta manera se debe seleccionar entre todas las variables input aquella cuyo valor de división cuente con una entropía o índice de Gini más bajo. De esta manera se garantiza que los hijos de un determinado nodo serán mejores que el nodo padre. El proceso es iterativo y se realiza hasta llegar a un punto en el cual un nodo descendiente no cuenta con las condiciones para ser dividido de nuevo, por tanto, se convierte en un nodo terminal. 4.3.5 Bagging y Random Forest Los modelos de Bagging y Randon Forest (Rf) están basados en la construcción de varios modelos diferentes usando en cada uno muestras aleatorias para que finalmente sean combinados y ensamblados en un modelo final. El algoritmo usado para la construcción de modelos Bagging es el siguiente (Ver figura 8): a. Tomar los datos de entrenamientos y dividirlos en submuestras aleatorias diferentes las cuales deben tener las siguientes características: - Todas las submuestras deben tener la misma cantidad de datos - Reemplazo: las observaciones pueden repetirse de una submuestra a otra. b. Con cada submuestra se construye un árbol predictivo, obteniendo así modelos, misma cantidad de submuestras. c. Se ensamblan todos los modelos en uno solo a través de la media de las predicciones de todos los árboles construidos. Figura 8. Estructura básica de modelos de Bagging y Rf 17
Este modelo es muy versátil ya que, al utilizar diferentes submuestras con diferentes observaciones en cada una, reduce la dependencia del modelo a comportarse de una misma manera para la construcción de un único modelo, esto ayuda a reducir bastante la varianza y el sesgo en los resultados. De acuerdo a lo mencionado anteriormente se determina que los parámetros para tener en cuenta para la construcción de un modelo Bagging son los siguientes: - Cantidad de submuestras a utilizar. Se definen también como cantidad de iteraciones a realizar. - Tamaño de cada submuestra, en relación con la cantidad de observaciones por submuestra. - Características de los árboles: cantidad de hojas finales, si hay poda, número de observaciones mínimo en cada nodo para poder dividirse. Por otro lado, los modelos de Rf, cuenta con un algoritmo muy similar al Bagging con una única diferencia, para este caso se agrega la opción de dar aleatoriedad no solo a las observaciones por cada submuestra sino también a las variables. Es decir que, para la construcción de cada árbol, intervendrán variables diferentes. De esta manera el algoritmo realiza el siguiente proceso: a. Tomar los datos de entrenamientos y dividirlos en submuestras aleatorias diferentes las cuales deben tener las siguientes características: - Todas las submuestras deben tener la misma cantidad de datos - Reemplazo: las observaciones pueden repetirse de una submuestra a otra. b. Seleccionar el número de variables que intervendrán en la construcción de cada árbol. c. Con cada submuestra y las variables aleatorias se construye un árbol predictivo, obteniendo así modelos, misma cantidad de submuestras. d. Se ensamblan todos los modelos en uno solo a través de la media de las predicciones de todos los árboles construidos. Este modelo se vuelve mucho más dinámico que el modelo Bagging ya que al agregar aleatoriedad a las variables que pueden participar en la construcción de cada árbol, reducir la probabilidad de tener sobreajustes. 4.3.6 Gradient Boosting Este modelo también está basado en la construcción de árboles y también tiene un proceso iterativo. La idea principal del algoritmo es entrenar modelos secuencialmente, de tal forma que en una nueva iteración ajuste los errores de los modelos anteriores. El proceso que realiza es el siguiente: • Se ajusta un primer modelo 1 para predecir la variable objetivo . ( ) 1 = ̂ • Se calculan los residuos de este primer modelo 1 ( ) ( ) 1 = − ̂ • A través de un árbol de clasificación ajustar los residuos de este primer modelo ( ) ( ) 1 → ̂ • Realizar un segundo modelo el cual intentara predecir y corregir los errores cometidos por el modelo 1 ( +1) ( ) ( ) 2 = ̂ = ̂ + ̂ • Repetir los anteriores pasos m veces, hasta lograr una reducción máxima del error. Dentro de este proceso interviene un parámetro llamado shrinkage ( ). Este es un parámetro de regularización que limita el peso de cada modelo en el ensamblado final. Generalmente se establece dentro de un rango de valores 0.001 y 0.3. Entre mayor sea este número, menos 18
estricto será el modelo. Pero con un valor muy bajo se debe aumentar la cantidad de modelos a construir. 4.3.7 Ensamblado Este algoritmo consiste en la construcción de modelos a través de la fusión de varios algoritmos diferentes. La figura 9 muestra el comportamiento de este algoritmo cuyo funcionamiento es el siguiente: • Se construye un modelo con cualquiera de los algoritmos propuestos (regresión, Knn, redes, bagging, Rf, Gradient Boodsting) para obtener unas predicciones 1 • Se construye un segundo modelo, el cual puede ser el mismo algoritmo usado para las predicciones de 1 pero con parámetros diferentes para obtener resultados variados. • Se construye n modelos usando los múltiples algoritmos con múltiples parámetros diferentes. • Se realiza una unión de todos los modelos anteriores para obtener predicciones basadas en el promedio de todos los modelos construidos. También se cuenta con la posibilidad de construir un modelo de ensamblado basado en un solo algoritmo, tomando como variables input las predicciones de otros modelos realizados, de esta manera se da aleatoriedad a los resultados. Figura 9. Algoritmo de Ensamblado 4.3.8 Medidas de evaluación de modelos Existen múltiples métodos para hacer evaluación de los modelos que se construyen para medir los niveles de exactitud en las predicciones realizadas en cada uno. Uno de estos métodos corresponde a la Matriz de Confusión. Esta matriz de confusión se realiza sobre el grupo de datos test. La figura 10 muestra la estructura de la matriz. Cuenta con dos columnas y dos filas en cuyos intercepto se ubican las predicciones de acuerdo en el siguiente orden: a. True Positives (Verdaderos Positivos): Corresponde a la cantidad de observaciones que en la data real estaban clasificados como positivos (1) y el modelo las ha catalogado como tal. b. False Negative (Falsos negativos): Corresponde a la cantidad de observaciones que en la data real estaba catalogados como Positivos (1), pero el modelo los ha catalogado como negativos (0). c. False Positive (Falsos positivos): Corresponde a la cantidad de observaciones que en la data real estaban catalogados como negativos (0) y el modelo los ha catalogado como positivos (1). d. True negatives (Verdaderos negativos): Cantidad de observaciones que en la data original estaban catalogados como negativos (0) y el modelo los ha catalogado como tal. De esta manera el objetivo radica en la diagonal principal a y d, los cuales son los valores que el modelo ha clasificado de forma correcta. 19
Figura 10. Funcionamiento matriz de confusión a b c d A partir de estos valores ubicados en la matriz, es posible obtener otras medidas: • Tasa de fallos: Se define como porcentaje en que el modelo se ha equivocado en hacer las predicciones. + + + + • Tasa de aciertos: Se define como el porcentaje en qué modelo ha acertado en las predicciones que ha realizado. + + + + Otro parámetro de evaluación corresponde a la curva ROC, este parámetro mide los modelos en cuanto a sus niveles de especificidad y sensibilidad, los cuales son obtenidos a partir de la matriz de confusión. Se define la especificidad como tasa de verdaderos negativos, mide la capacidad del modelo para clasificar los casos como malos. Por otro la sensibilidad mide la tasa de verdaderos positivos o razón de éxitos. Mide la capacidad del modelo para detectar casos positivos. La figura 11 muestra el comportamiento de la curva, por tanto un modelo ideal será aquel que se acerque más a la coordenada 1 ,1, curva azul de la figura. Y un modelo nada óptimo es aquel que cuenta con una sensibilidad y especificidad de cero en ambos parámetros, en cuyo caso correspondería a la línea de color rosa. Figura 11. Interpretación Curva ROC 5. DESARROLLO DEL TRABAJO Los datos fueron obtenidos a través de convenio con una EPS, cuenta con un total de 146242 observaciones correspondientes a las quejas radicadas por los usuarios de la empresa en el año del 2016. Por temas de privacidad de datos, estos no pueden ser publicados. 20
Contaba con un total de 49 variables con las que se ha realizado un trabajo previo: • Se han eliminado por completo variables que contenían información personal de los usuarios y de los funcionarios de la empresa: nombres, DNI, números de teléfono y móvil, ubicación de domicilios; esto a fin de anonimizar por la identidad de ambos grupos. Se ha creado una variable ID para lograr identificar al usuario de cada queja. • Se han eliminado dos variables las cuales contenían párrafos de texto donde estaban escritos los comentarios dados por los usuarios y las respuestas del funcionario. Se han eliminado ya que su análisis habría requerido de otras técnicas relacionadas con text- mining o análisis de sentimientos. • La variable Fecha de nacimiento fue eliminada y en remplazo se creó la variable Edad. • Las fechas de radicación, fecha límite de respuesta y solución de la queja fueron eliminadas y en su remplazo se ha creado la función objetivo. Esta es de tipo dicotómica y permite identificar si la queja fue solucionada a tiempo (0) o no (1) De esta manera el total de variables a trabajar es de 18 las cuales se explican en el siguiente apartado. 5.1 Análisis descriptivo del conjunto de datos La tabla 3, muestra la descripción de las variables finales que se utilizaron para el estudio. Tabla 3. Descripción de las Variables VARIABLE DESCRIPCIÓN ID Identificador asignado a cada queja radicada Regimen_Afil Régimen al que pertenece el usuario. (C= Contributivo, S=Subsidiado) SitioRecepcion Lugar en el cual se recibió la queja (Línea Total, Front Desk, Pagina web, CLD, IPS Propia, Servicio al Cliente, Dirección General, Área Comercial, IPS Red Contratada, Área de Cartera, Presidencia) Oportunidad_I Objetivo (1=Solución fuera de tiempo, 0=Solución a tiempo) SucursalResponsable Sucursal encargada de dar solución a la queja. (18 Categorías) Estado Estado del caso (Solución, Cerrado contacto, Pendiente por Contactar, Solución no procedente, Consultada por el usuario, Gestión Adicional) SucursalClasificacion Ciudad en la que fue radicada la queja (18 Categorías. Ejemplo: Barranquilla, Bogotá, Cartagena, Cali …) GrupoResponsableActual Área de la compañía o centro médico sobre la cual cae la responsabilidad (195 categorías. Ejemplo: Auditoria Cali, Operaciones Barranquilla, Autorizaciones Medellín, Tesorería, Comercial…) MedioRecepcion Medio a través del cual se recibió la queja (Carta, Caja, Sobre, Buzón, Pagina Web, Personal, Teléfono, Asociación) Genero (F=Femenino, M=Masculino) Gestante Si la usuaria se encontraba en estado de embarazo (Si, No) Causa Motivo que generó la queja (271 Categorías. Ejemplo: disponibilidad de agenda para asignación de citas, reembolsos, programación de cirugías, fallas en la asignación de citas…) Causa_Ini Desagregación de la variable Causa. Muestra más especificidad de la variable. (347 Categorías. Ejemplo: Causa -> Resolutividad del acto médico Causa_Ini -> Atención de urgencias, Medicina general, Medicina especializada, Promoción y Prevención…) Área Nombres genéricos asignados a grupos de quejas según motivo de la causa (16 Categorías. Ejemplo: Oportunidad de citas, Pagos de prestaciones, Servicios Médicos, Servicios Legales a Usuarios) Categoría Clasificación de la queja (Queja, Reclamo) Discapacitado Si el usuario presenta alguna discapacidad (Si, No) TipoContacto Condición del usuario (Afiliado, Empleador, No Afiliado) Edad Edad del paciente Se utiliza Power BI para dar un primer vistazo al conjunto de datos y se identifican los siguientes comportamientos. El gráfico 1, permite visualizar la cantidad de quejas radicadas por Sitio de Recepción, se identifica que el 40.22% fueron radicadas a través de Línea Total el cual corresponde al sistema Call Center. En segundo lugar, se sitúa el Front Desk con 19.15%, correspondiente a los puntos de recepción donde se anuncia la llegada de los pacientes a la 21
También puede leer

















































