AWSDirectrices prescriptivas - Parches automatizados para instancias mutables en la nube híbrida medianteAWS Systems Manager
←
→
Transcripción del contenido de la página
Si su navegador no muestra la página correctamente, lea el contenido de la página a continuación
AWSDirectrices prescriptivas
Parches automatizados para
instancias mutables en la nube híbrida
medianteAWS Systems Manager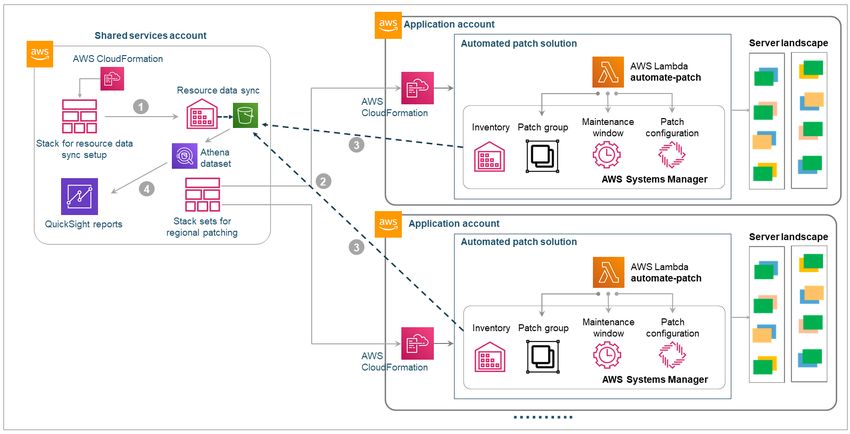
AWSDirectrices prescriptivas Parches
automatizados para instancias mutables en la
nube híbrida medianteAWS Systems Manager
AWSDirectrices prescriptivas: Parches automatizados para instancias
mutables en la nube híbrida medianteAWS Systems Manager
Copyright © Amazon Web Services, Inc. and/or its affiliates. All rights reserved.
Las marcas comerciales y la imagen comercial de Amazon no se pueden utilizar en relación con ningún producto o
servicio que no sea de Amazon de ninguna manera que pueda causar confusión entre los clientes y que menosprecie
o desacredite a Amazon. Todas las demás marcas comerciales que no son propiedad de Amazon son propiedad de
sus respectivos propietarios, que pueden o no estar afiliados, conectados o patrocinados por Amazon.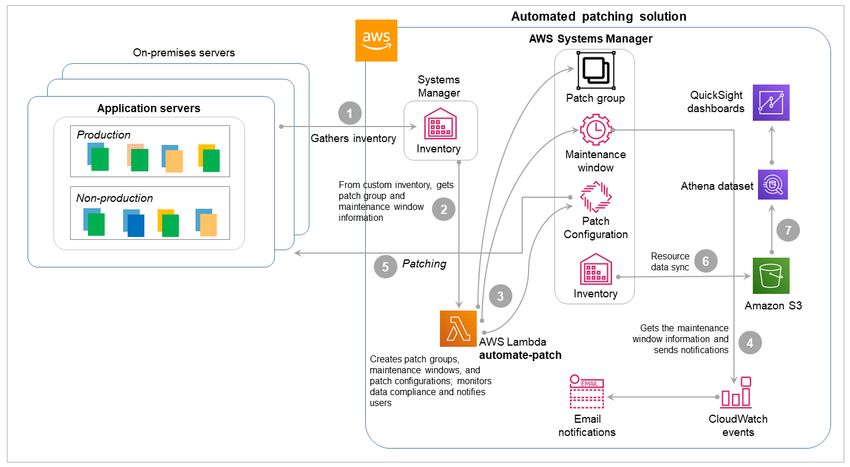
AWSDirectrices prescriptivas Parches
automatizados para instancias mutables en la
nube híbrida medianteAWS Systems Manager
Table of Contents
Introducción ....................................................................................................................................... 1
Información general ............................................................................................................................ 2
Términos y conceptos ................................................................................................................. 3
Historias clave de usuario ............................................................................................................ 3
Proceso de parches ............................................................................................................................ 6
Diseño para instancias EC2 mutables .................................................................................................... 8
Proceso automatizado ................................................................................................................. 8
Diseño para variosAWScuentas y regiones ........................................................................................... 10
Proceso automatizado ............................................................................................................... 10
Consideraciones y limitaciones acerca de la arquitectura ................................................................ 11
Cuotas de ventana de mantenimiento por cuenta ................................................................... 11
Otras consideraciones ....................................................................................................... 12
Diseño para instancias locales en un entorno de nube híbrida ................................................................. 13
Proceso automatizado ............................................................................................................... 13
Condiciones y limitaciones acerca de la arquitectura ...................................................................... 14
Principales partes interesadas, roles y responsabilidades ........................................................................ 16
Personas de usuario ................................................................................................................. 16
Matriz RACI ............................................................................................................................. 17
Pasos siguientes ............................................................................................................................... 19
Recursos adicionales ......................................................................................................................... 20
AWSGlosario de guía prescriptiva ....................................................................................................... 21
Historial de documentos ..................................................................................................................... 29
..................................................................................................................................................... xxx
iii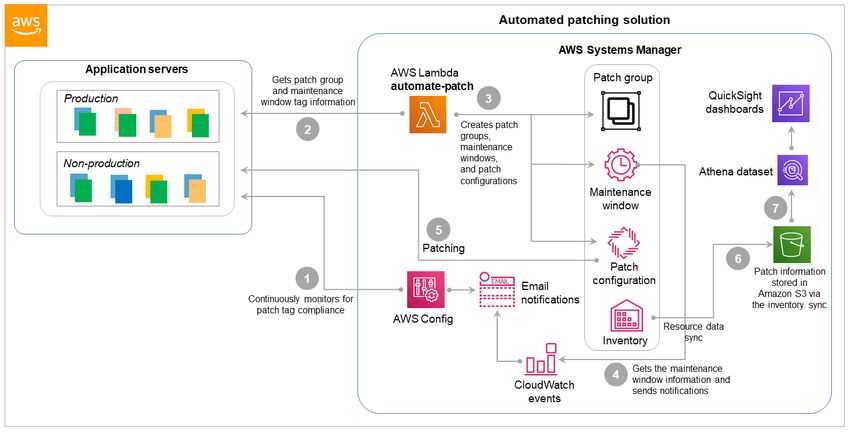
AWSDirectrices prescriptivas Parches
automatizados para instancias mutables en la
nube híbrida medianteAWS Systems Manager
Parches automatizados para
instancias mutables en la nube
híbrida medianteAWS Systems
Manager
Chandra Allaka, Consultora Senior, Integración de Operaciones,AWSServicios profesionales
Junio de 2020
En esta guía prescriptiva se describe una solución de parches automatizada que utiliza Amazon
Web Services (AWS) Systems Manager. Puede utilizar esta solución para aplicar parches a las
instancias mutables (de larga duración) de Amazon Elastic Compute Cloud (Amazon EC2) que abarcan
variasAWScuentas yAWSRegions y sus instancias on-premises.
Esta guía está dirigida a los usuarios que participan en el diseño y la creación de capacidades operativas
en un entorno de nube híbrida para permitir que los equipos de aplicaciones cumplan las políticas de
parches de su empresa. Le proporciona un mecanismo de autoservicio para implementar parches
aprobados previamente en los servidores de aplicaciones.
Esta guía supone un buen entendimiento de lo siguiente:AWSservicios y conceptos:
• Systems Manager— Proporciona una interfaz de usuario unificada para ver datos operativos desde
variosAWSservicios y automatización de tareas operativas en todo suAWSde AWS.
• Inventario Systems Manager: proporciona visibilidad de su entorno informático local y Amazon EC2.
Puede utilizar Inventory para recopilar metadatos de las instancias administradas.
• Systems Manager Patch Manager: automatiza el proceso de aplicación de parches en instancias
administradas con actualizaciones relacionadas con la seguridad y otros tipos de actualizaciones.
• Systems Manager de mantenimiento de: permite definir una programación para realizar acciones
que pueden provocar interrupciones en las instancias, como la aplicación de parches en un sistema
operativo, la actualización de controladores o la instalación de software o parches.
• AWS Lambda: con este, puede ejecutar código sin aprovisionar ni administrar servidores.
• Amazon QuickSight: permite crear y publicar fácilmente paneles interactivos, incluidos Insights de
aprendizaje automático (ML). Puede acceder a los paneles desde cualquier dispositivo e incrustarlos en
sus aplicaciones, portales y sitios web.
• Etiquetado— Permite asignar metadatos a suAWSrecursos en forma de etiquetas. Cada etiqueta es
una marca que consta de una clave y un valor definidos por el usuario. Las etiquetas pueden ayudarle a
administrar, identificar, organizar, buscar y filtrar recursos.
1AWSDirectrices prescriptivas Parches
automatizados para instancias mutables en la
nube híbrida medianteAWS Systems Manager
Información general acerca de la
administración
Si participa en operaciones de aplicación o infraestructura, comprende la importancia de una solución
de parches de sistemas operativos (SO) que sea lo suficientemente flexible y escalable para cumplir
los diversos requisitos de los equipos de aplicaciones. En una organización típica, algunos equipos de
aplicaciones utilizan una arquitectura que incluye instancias inmutables, mientras que otros implementan
sus aplicaciones en instancias mutables.
La aplicación de parches de instancias inmutables implica aplicar los parches a las imágenes de máquina
de Amazon (AMI) que se utilizan para aprovisionar las instancias de aplicación EC2 inmutables. El parche
de instancias mutable implica una implementación de parches in situ en las instancias en ejecución durante
un período de mantenimiento programado.
En esta guía prescriptiva se describe cómo se puede utilizarAWS Systems ManagerPatch Manager
para aplicar parches de instancias mutables que abarcan variasAWScuentas yAWSRegiones de forma
automatizada, según las ventanas de mantenimiento y los grupos de parches definidos por los equipos de
aplicaciones en sus servidores mediante etiquetas.
En la guía se describe una solución de parches automatizada que utilizaAWS Lambdapara automatizar las
configuraciones y la programación de parches, mediante el Administrador de parches y las ventanas de
mantenimiento. Amazon QuickSight proporciona los informes y las capacidades de panel necesarias para
informar sobre el cumplimiento de parches.
Además, en esta guía se describe una arquitectura de referencia para entornos de nube híbrida. Los
usuarios que ejecutan sus aplicaciones en una configuración de nube híbrida buscan oportunidades
para consolidar, simplificar, estandarizar y optimizar sus operaciones de administración de parches
en todoAWSy su infraestructura local. La guía explica cómo se puede ampliar la solución de parches
automatizada para instancias mutables para admitir escenarios de nube híbrida.
En esta guía se describen:
• Historias clave de los usuarios para la administración de
• El proceso de parches
• Administración de parches para instancias mutables en una sola cuenta y en una sola
cuentaAWSRegión; consideraciones arquitectónicas y limitaciones
• Administración de parches para instancias mutables en un entorno de varias cuentas y regiones;
consideraciones arquitectónicas y limitaciones
• Administración de parches para instancias locales en un entorno de nube híbrida; consideraciones
arquitectónicas y limitaciones
• Principales partes interesadas, roles y responsabilidades
Note
En esta guía se describe la arquitectura de una solución automatizada (denominada lasolución de
parches automatizada) que puede implementar para admitir los requisitos de administración de
parches para instancias mutables. No se proporciona el código para crear la solución.
2AWSDirectrices prescriptivas Parches
automatizados para instancias mutables en la
nube híbrida medianteAWS Systems Manager
Términos y conceptos
Términos y conceptos
Term (Término) Definición
Instancias inmutables Las instancias inmutables son instancias de
servidor EC2 que no experimentan ningún cambio
mientras se ejecutan. Si es necesario realizar
cambios, crea una nueva instancia con la imagen
del servidor actualizada, vuelve a desplegar
la instancia y destruir la imagen del servidor
existente.
Base de referencia de parches Una línea base de parches es específica de un
tipo de SO y define la lista de parches aprobada
para la instalación en las instancias. Para obtener
más información, consulteAcerca de las bases
de referencia de parches personalizadas y
predefinidasen la documentación de Systems
Manager.
Grupo de parches Un grupo de parches representa los servidores de
un entorno de aplicaciones que son objetivos de
una línea base de parches específica. Los grupos
de parches ayudan a garantizar que las líneas
base de referencia correctas se implementan en el
conjunto correcto de instancias. También ayudan
a evitar la implementación de parches antes de
que estos se hayan probado suficientemente.
Los grupos de parches se representan mediante
elGrupo de parchesetiqueta. Para obtener más
información, consulteAcerca de los grupos de
parchesen la documentación de Systems Manager.
Maintenance window (Periodo de mantenimiento) Los períodos de mantenimiento permiten
definir una programación para realizar acciones
potencialmente problemáticos en instancias,
como la aplicación de parches en un sistema
operativo, la actualización de controladores o la
instalación de software o parches. Cada periodo
de mantenimiento tiene una programación, una
duración máxima, un conjunto de instancias
de destino registradas y un conjunto de tareas
registradas. Los grupos de parches se representan
mediante elMaintenance Window (Periodo de
mantenimiento)etiqueta. Para obtener más
información, consulteAcerca de la programación de
parches con las ventanas de mantenimientoen la
documentación de Systems Manager.
Historias clave de usuario
El proceso típico de revisión del sistema operativo incluye tres tareas:
1. Análisis de las instancias EC2 y los servidores locales en busca de parches del SO aplicables.
3AWSDirectrices prescriptivas Parches
automatizados para instancias mutables en la
nube híbrida medianteAWS Systems Manager
Historias clave de usuario
2. Agrupación y revisión de las instancias en un momento adecuado.
3. Cumplimiento de parches de informes en todo el entorno de servidores.
En la tabla siguiente se indican las historias principales de usuario para la administración de parches de.
Escenario Función de usuario Description (Descripción)
Mecanismo de parches Equipos de desarrollo y soporte Como miembro del equipo de
de aplicaciones aplicaciones que es responsable
de los parches del SO, necesito
un mecanismo para corregir
mis instancias mutables o
de larga duración, de modo
que pueda mitigar cualquier
vulnerabilidad de seguridad del
SO y también asegurarme de
que las instancias cumplan la
línea base de parches definida
por el equipo de seguridad.
Solución de parches Propietario de servicio en la Como propietario de un servicio
en la nube que es responsable
de proporcionar servicios
en la nube a los equipos de
aplicaciones, necesito crear
una solución de parches de SO
que admita variosAWScuentas
yAWSRegiones y servidores
locales, de modo que los equipos
de aplicaciones puedan mitigar
cualquier vulnerabilidad de
seguridad del SO y también
cumplir con la línea base de
parches definida por el equipo de
seguridad.
Informes de conformidad de Administrador de operaciones de Como gestor de operaciones de
parches seguridad seguridad que es responsable
de garantizar el cumplimiento de
parches, necesito información
e informes detallados de
conformidad de parches en todo
el panorama de la nube, para
poder identificar servidores que
no cumplen con la línea base de
parches y los equipos de alerta
para implementar la mitigación
necesaria.
Definición de roles y Propietario de servicio en la Como propietario de servicios
responsabilidades en la nube, necesito crear
una matriz de funciones y
responsabilidades bien definida
que explique quién hace qué
hace en la administración de la
solución de parches de nube
4AWSDirectrices prescriptivas Parches
automatizados para instancias mutables en la
nube híbrida medianteAWS Systems Manager
Historias clave de usuario
Escenario Función de usuario Description (Descripción)
híbrida que creé, de modo
que se publican y cumplan
las obligaciones para las
operaciones de parches.
5AWSDirectrices prescriptivas Parches
automatizados para instancias mutables en la
nube híbrida medianteAWS Systems Manager
Proceso de parches
Los principales usuarios de la solución de parches son los equipos de desarrollo de aplicaciones y
operaciones. Cada aplicación se implementa normalmente en varios entornos, como desarrollo, pruebas
(integración, aceptación de usuarios, etc.) y producción. Los equipos de aplicación tienen que planificar
los programas de parches para cada entorno, de modo que cuando se aplica un parche al entorno de
producción, ya se ha probado y se ha determinado que no tiene efectos adversos en la aplicación.
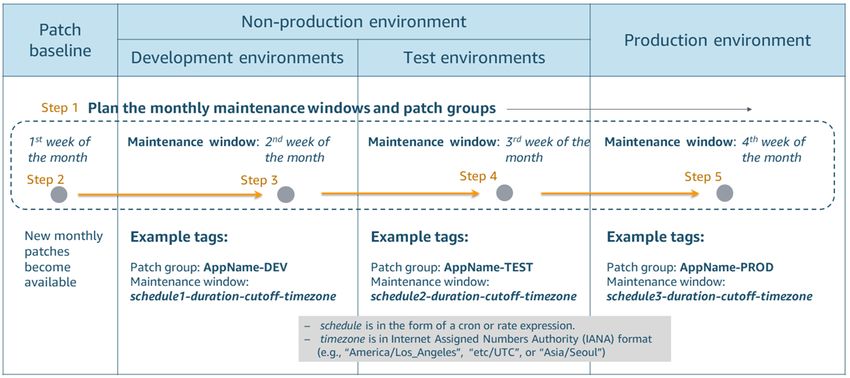
El siguiente flujo de trabajo proporciona un ejemplo de cómo planificar ventanas de parches para una
aplicación que se implementa en varios entornos y cómo configurar etiquetas.
• Paso 1. Cada equipo de aplicaciones planifica sus ventanas de mantenimiento para sus servidores
en varios entornos y configura las etiquetas que representan los grupos de parches y ventanas de
mantenimiento de los servidores en consecuencia:
• LaGrupo de parchesrepresenta los servidores de un entorno de aplicaciones que son los destinos
de una línea base de parches específica. Los grupos de parches ayudan a garantizar que las líneas
base de referencia correctas se implementan en el conjunto correcto de instancias. Los grupos de
parches también ayudan a evitar la implementación de parches en el entorno de producción antes de
que estos se hayan probado suficientemente.
• Si los servidores de aplicaciones incluyen varios sistemas operativos, el equipo de aplicaciones
crea grupos de parches basados en la combinación del entorno y el sistema operativo. Un grupo de
parches se puede registrar solo con una línea base de parches y una instancia puede formar parte de
un solo grupo de parches.
Por ejemplo:appname-DEV-WINyappname-DEV-RHEL
• LaMaintenance Window (Periodo de mantenimiento)representa la programación para aplicar parches
a los servidores. Todos los servidores de un grupo de revisiones deben estar en la misma ventana de
mantenimiento. La etiqueta de ventana de mantenimiento debe seguir un formato coherente para las
expresiones cron y rate, de modo que una función Lambda que defina pueda analizar las expresiones
fácilmente. (En esta guía, nos referiremos a esta función Lambda comoautomate-patch.)
Por ejemplo: schedule-duration-cutoff-timezone
cron(0 2 ? * SAT#3 *)representa las 2:00 el tercer sábado de cada mes. Para obtener
información detallada sobre las expresiones cron y rate, consulte laDocumentación de Systems
Manager.
6AWSDirectrices prescriptivas Parches
automatizados para instancias mutables en la
nube híbrida medianteAWS Systems Manager
• Paso 2. Patch Manager de Systems Manager hace que los nuevos parches estén disponibles
periódicamente a través de líneas base de parches específicas del sistema operativo basadas en las
configuraciones definidas.
• Para cada sistema operativo, puede definir una línea base de parches personalizada que incluya las
reglas de aprobación y los parches que deben aplicarse a las instancias en todo el entorno de nube.
• Paso 3. El código de automatización personalizado configura Patch Manager para configurar los parches
basados en elGrupo de parchesyMaintenance Window (Periodo de mantenimiento)y aplica los parches
al entorno de desarrollo.
• Una vez finalizado el parche, los equipos de soporte y desarrollo de aplicaciones prueban la aplicación
y verifican que todo funciona correctamente.
• Si la aplicación encuentra algún problema con el nuevo parche, los equipos de aplicaciones solicitan
al equipo de servicios en la nube que detenga la aplicación de parches en otros grupos de parches y
otros entornos, deshabilitando las ventanas de mantenimiento o cancelando el registro de la ejecución
de la tarea de parches.
• Paso 4. Una vez que el entorno de desarrollo se ha aplicado correctamente, los parches se
implementan en cualquier otro entorno que no sea de producción. Al igual que en el entorno de
desarrollo, se prueba y se comprueba que la aplicación funciona correctamente en todos los entornos
que no son de producción. Si hay algún problema, los equipos de aplicaciones solicitan al equipo de
servicios en la nube que detenga la aplicación de parches en el entorno de producción.
• Paso 5. Después de que todos los entornos que no son de producción se hayan parchado
correctamente, se aplican parches al entorno de producción.
7AWSDirectrices prescriptivas Parches
automatizados para instancias mutables en la
nube híbrida medianteAWS Systems Manager
Proceso automatizado
Diseño de solución de parches para
instancias EC2 mutables
El proceso de parches para instancias mutables incluye los siguientes equipos y acciones:
• Laequipos de aplicaciones (DevOps)definir los grupos de parches de sus servidores según el entorno de
aplicación, el tipo de SO u otros criterios. También definen las ventanas de mantenimiento específicas
de cada grupo de parches. Esta información se almacena en elGrupo de parchesyMaintenance Window
(Periodo de mantenimiento)etiquetas de las instancias de aplicación EC2. Durante cada ciclo de
parches, los equipos de aplicaciones se preparan para la aplicación de parches, prueban la aplicación
tras el parche y solucionan cualquier problema con sus aplicaciones y SO durante el parche.
• Laequipo de operaciones de seguridaddefine las líneas base de parches para varios tipos de SO que
utilizan los equipos de aplicaciones, aprueba los parches y hace que los parches estén disponibles a
través del Administrador de parches de Systems Manager.
• Lasolución de parches automatizadase ejecuta regularmente e implementa los parches definidos en las
líneas base de parches en función de los grupos de parches definidos por el usuario y en las ventanas
de mantenimiento. La información de cumplimiento de parches se obtiene mediante una sincronización
de datos de recursos en Systems Manager Inventory y se utiliza para generar informes de conformidad
de parches a través de los paneles de Amazon QuickSight.
• Laequipos de gobernanza y cumplimientodefinir las directrices de aplicación de parches, definir procesos
y mecanismos de excepciones y obtener los informes de conformidad de Amazon QuickSight.
Para obtener información detallada sobre las principales partes interesadas involucradas en una solución
de administración de parches de SO exitosa y sus responsabilidades, consulte laPrincipales partes
interesadas, roles y responsabilidades (p. 16)sección más adelante en esta guía.
Proceso automatizado
La solución de parches automatizada utiliza variosAWSservicios que funcionan en conjunto para
implementar los parches en las instancias EC2. Este proceso implicaAWS Config,AWS Lambda, Systems
Manager, Amazon Simple Storage Service (Amazon S3) y Amazon QuickSight. En el siguiente diagrama
se muestra la arquitectura de referencia y el flujo de trabajo.
8AWSDirectrices prescriptivas Parches
automatizados para instancias mutables en la
nube híbrida medianteAWS Systems Manager
Proceso automatizado
El flujo de trabajo incluye estos pasos, en los que los números de paso coinciden con los rótulos del
diagrama:
1. AWS Configsupervisa continuamente lo siguiente y envía notificaciones con los detalles de las
instancias no conformes y las configuraciones necesarias:
• Cumplimiento del etiquetado de parches en instancias EC2.AWS Configcomprueba si hay instancias
que no tienenGrupo de parchesyMaintenance Window (Periodo de mantenimiento)etiquetas.
• LaAWS Identity and Access Management(IAM) con el rol de Systems Manager, que permite a
Systems Manager administrar las instancias.
2. La función Lambda (la llamaremosautomate-patch) se ejecuta en una programación predefinida y
recopila elGrupo de parchesyMaintenance Window (Periodo de mantenimiento)información de todos los
servidores.
3. Laautomate-patchcrea o actualiza los grupos de parches y las ventanas de mantenimiento
adecuados, asocia los grupos de parches a las líneas base de parches, configura el análisis de parches
e implementa la tarea de parches. Opcionalmente, elautomate-patchtambién crea eventos en
Amazon CloudWatch Events para notificar a los usuarios de parches inminentes.
4. En función de las ventanas de mantenimiento, los eventos envían notificaciones de parches a los
equipos de aplicaciones con los detalles de la inminente operación de parches.
5. Patch Manager realiza parches del sistema según la programación definida y los grupos de parches.
6. Una sincronización de datos de recursos en Systems Manager Inventory recopila los detalles del parche
y los publica en un bucket de S3.
7. Los informes de conformidad de parches y los paneles están integrados en Amazon QuickSight a partir
de la información del bucket de S3.
9AWSDirectrices prescriptivas Parches
automatizados para instancias mutables en la
nube híbrida medianteAWS Systems Manager
Proceso automatizado
Diseño de solución de parches para
múltiplesAWScuentas y regiones
Puede ampliar la solución de parches automatizada para admitir servidores que abarcan
variosAWScuentas y varias cuentasAWSRegiones. La solución ampliada implica configurar la solución de
automatización de parches en cadaAWScuenta a través deAWS CloudFormationStackSets en una cuenta
de servicios compartidos y configuración de una sincronización de datos de recursos en las cuentas con la
cuenta de servicios compartidos.
Proceso automatizado
El siguiente diagrama ilustra la arquitectura de este escenario. Esta arquitectura incluyeAWS
CloudFormationStackSets yAWScuenta de servicio compartido.
El flujo de trabajo es similar al proceso descrito en la sección anterior, pero incluye los siguientes pasos
adicionales, en los que los números de paso coinciden con los rótulos del diagrama:
1. En la cuenta de servicios compartidos, unAWS CloudFormationStackSets se utiliza para configurar el
bucket de S3 para la sincronización de datos de recursos a través de Systems Manager Inventory.
2. El conjunto de pilas CloudFormation crea la pila con elautomate-patchFunción Lambda, configura
las líneas base de parches y configura la sincronización de datos de recursos de Systems Manager
Inventory en las cuentas de la aplicación para sincronizar los recursos de la cuenta de servicios
compartidos.
3. La información de recursos de las cuentas de aplicación se sincroniza con la información de recursos de
la cuenta de servicios compartidos.
4. Amazon QuickSight genera informes de cumplimiento de parches, utilizando el conjunto de datos de
Amazon Athena para obtener la información de recursos sincronizada.
10AWSDirectrices prescriptivas Parches
automatizados para instancias mutables en la
nube híbrida medianteAWS Systems Manager
Consideraciones y limitaciones acerca de la arquitectura
Consideraciones y limitaciones acerca de la
arquitectura
Cuotas de ventana de mantenimiento por cuenta
La arquitectura ilustrada y descrita en la sección anterior crea un período de mantenimiento para cada
grupo de parches. Sin embargo, la cuota para el número de períodos de mantenimiento porAWScuenta es
50 (suponiendo que no hayas solicitado un aumento de la cuota de servicio). Si espera que el número de
grupos de parches supere los 50 grupos en un soloAWS, esta arquitectura no se escalará para satisfacer
sus requisitos.
Si un aumento de la cuota de servicio no es suficiente para sus necesidades, existen dos opciones para
gestionar este desafío: utilizar ventanas de mantenimiento predefinidas y usar CloudWatch Events. Estas
son las ventajas e inconvenientes de cada enfoque.
Opción 1. Uso de períodos de mantenimiento predefinidos
• Defina una lista de los períodos de mantenimiento con varios períodos de tiempo (por ejemplo, de 15 a
20 períodos de mantenimiento por cuenta).
• Los equipos de aplicaciones eligen las ventanas de mantenimiento que se adaptan a ellos de la lista
predefinida y etiquetan las instancias en consecuencia.
• Actualice la solución de parches automatizada para asignar los grupos de parches a las ventanas de
mantenimiento seleccionadas en lugar de crear nuevas ventanas de mantenimiento.
Pros:
• Administración simplificada.
Contras:
• Menos flexibilidad para definir ventanas de mantenimiento personalizadas.
• Cuando varios grupos de parches comparten ventanas de mantenimiento y tareas de parches, cancelar
una tarea de parches específica para un grupo de parches específico requiere un esfuerzo manual
adicional.
Opción 2. Utilizar CloudWatch Events para activar tareas de parches en lugar de utilizar ventanas de
mantenimiento
• En lugar de crear ventanas de mantenimiento, utilice CloudWatch Events para activar tareas de parches
según la programación y los grupos de parches.
• En este escenario, cada grupo de parches se asocia a un evento de CloudWatch Events en lugar de a
un período de mantenimiento.
• Actualice la solución de parches automatizada para crear eventos en lugar de ventanas de
mantenimiento.
Pros:
• Diseño escalable.
• Proporciona flexibilidad para definir ventanas de mantenimiento personalizadas.
Contras:
11AWSDirectrices prescriptivas Parches
automatizados para instancias mutables en la
nube híbrida medianteAWS Systems Manager
Otras consideraciones
• Las ventanas de mantenimiento proporcionan funciones adicionales (como la duración y los tiempos
límite) que no están disponibles con CloudWatch Events.
Otras consideraciones
• La solución de parches automatizada descrita en esta sección no admite instancias EC2 que están
apagadas.
• Este proceso admite instancias EC2 en subredes públicas. Para aplicar parches de instancias en
subredes privadas, debe implementar unrepositorio de parches local como Windows Server Update
Services (WSUS).
• Debe ajustar la frecuencia de ejecución de la función Lambda para que los grupos de parches y las
ventanas de mantenimiento se actualicen de acuerdo con la programación requerida.
12AWSDirectrices prescriptivas Parches
automatizados para instancias mutables en la
nube híbrida medianteAWS Systems Manager
Proceso automatizado
Diseño de solución de parches para
instancias locales en un entorno de
nube híbrida
También puede ampliar la solución descrita en esta guía para aplicar parches a instancias de servidores
locales en un entorno de nube híbrida.
El proceso de revisión estándar para instancias locales consta de dos pasos:
• Puede configurar los servidores locales para que los administre Systems Manager. Para obtener más
información sobre este proceso, consulteConfiguración de Systems Manager para entornos híbridosen la
documentación de Systems Manager.
• Configura el adecuadoGrupo de parchesyMaintenance Window (Periodo de mantenimiento)etiquetas
para estas instancias administradas en las instalaciones mediante elAWS Command Line Interface(AWS
CLI)comando add-tags-to-resource.
Sin embargo, este enfoque requiere que el equipo de aplicaciones o el equipo de la nube ejecuten
manualmente elAWS CLIsiempre que quieran realizar cambios en los grupos de parches o en las ventanas
de mantenimiento.
Proceso automatizado
En la siguiente ilustración se describe un enfoque alternativo para aplicar parches a instancias locales que
utiliza la opción de inventario personalizado de Systems Manager. Este proceso es una extensión de la
solución de parches automatizada que describimos anteriormente para instancias EC2 mutables.
13AWSDirectrices prescriptivas Parches
automatizados para instancias mutables en la
nube híbrida medianteAWS Systems Manager
Condiciones y limitaciones acerca de la arquitectura
1. En lugar de utilizar etiquetas, Systems Manager captura la información de parches (grupos de parches
y ventanas de mantenimiento) de las instancias administradas en las instalaciones mediante una
colección de inventario personalizada.
Sample custom inventory JSON file
{
"SchemaVersion": "1.0",
"TypeName": "Custom:PatchInformation",
"Content": {
"Patch Group": "",
"Maintenance Window": "XXX"
}
}
2. La Lambdaautomate-patchse ejecuta todos los días, recopila la información del grupo de parches
y de la ventana de mantenimiento del inventario personalizado del servidor local y crea elGrupo de
parchesyMaintenance Window (Periodo de mantenimiento)etiquetas de las instancias administradas.
3. La Lambdaautomate-patchcrea o actualiza los grupos de parches y las ventanas de mantenimiento
adecuados, asocia los grupos de parches con las líneas base de parches, configura los análisis de
parches e implementa la tarea de parches, en función del inventario personalizado que se recopiló.
Opcionalmente, elautomate-patchtambién crea eventos en CloudWatch Events para notificar a los
usuarios de parches inminentes.
4. En función de las ventanas de mantenimiento, los eventos envían notificaciones de parches a los
equipos de aplicaciones con los detalles de la inminente operación de parches.
5. Patch Manager realiza parches del sistema según la programación definida y los grupos de parches.
6. Una sincronización de datos de recursos en Systems Manager Inventory recopila los detalles del parche
y los publica en un bucket de S3.
7. Los informes de conformidad de parches y los paneles están integrados en Amazon QuickSight a partir
de la información del bucket de S3.
Condiciones y limitaciones acerca de la arquitectura
Como se ha comentado en las secciones anteriores, existen dos enfoques para aplicar parches a
instancias locales: mediante inventario personalizado o mediante etiquetas. A continuación se detallan los
beneficios e inconvenientes de cada método.
Opción 1. Utilizar inventario personalizado para obtener información de parches
• Los equipos de aplicaciones que trabajan con servidores locales configuran la información de parches
en el fichero de inventario personalizado y Systems Manager selecciona esa información.
• La información de parches de inventario personalizada se utiliza para crear las tareas de parches.
Pros:
• Es mucho más sencillo de configurar porque solo implica una actualización de archivos.
Contras:
• Los cambios en la configuración de parches se limitan a la programación de recogida de inventario.
Opción 2. Utilizar etiquetas para instancias administradas on-premise
14AWSDirectrices prescriptivas Parches
automatizados para instancias mutables en la
nube híbrida medianteAWS Systems Manager
Condiciones y limitaciones acerca de la arquitectura
• Crear equipos de aplicaciones que trabajan con servidores on-premisesGrupo de parchesyMaintenance
Window (Periodo de mantenimiento)etiquetas medianteAWS CLIcon la información de parches
adecuada.
• La información de la etiqueta se utiliza para crear las tareas de parches.
Pros:
• Enfoque coherenteAWSy en las instalaciones para impulsar la estandarización y automatización de
parches.
Contras:
• Los equipos de aplicaciones que trabajan con instancias locales tienen que aprender y utilizarAWS
CLIpara crear o actualizar las etiquetas.
15AWSDirectrices prescriptivas Parches
automatizados para instancias mutables en la
nube híbrida medianteAWS Systems Manager
Personas de usuario
Principales partes interesadas,
roles y responsabilidades en la
administración de parches
La gestión correcta de parches del SO requiere tener funciones y responsabilidades bien definidas para
dar soporte a la solución de parches automatizada y optimizarla continuamente. En esta sección se
describen las funciones y responsabilidades sugeridas que puede modificar según sus necesidades y
estructura organizativa.
Personas de usuario
En la tabla siguiente se describen las personas de usuario involucradas en la solución de parches
automatizada.
Persona de usuario Description (Descripción)
Consumidores (C) La solución de administración de parches para
instancias de larga duración la utilizan diferentes
equipos que participan en la administración del SO,
entre ellos:
• Equipos de desarrollo que administran entornos
de aplicaciones de pila completa.
• Equipos de operaciones que administran el SO
del servidor de aplicaciones.
Ingeniería en la nube (CE) El equipo responsable de:
• Optimización continua de la solución de
administración de parches.
• Creación de automatización de servicios en la
nube.
• Apoyo a la automatización.
Oficina de negocios en la nube (CBO) El equipo que participa en:
• Gestión de la experiencia del consumidor para la
solución.
• Habilitación y participación de los usuarios.
• Asegurarse de que la solución de parches
satisfaga las necesidades de los consumidores.
Propietario de servicio/producto en la nube (CPO) La persona responsable de:
• Proporcionar servicios en la nube a los
consumidores.
• Trabajar en estrecha colaboración con el equipo
directivo para alinear la prestación de servicios
con las expectativas y directrices.
16AWSDirectrices prescriptivas Parches
automatizados para instancias mutables en la
nube híbrida medianteAWS Systems Manager
Matriz RACI
Persona de usuario Description (Descripción)
• Gestionar todas las expectativas y escalaciones
de los clientes relacionadas con la plataforma.
• Ser dueño de la hoja de ruta de la plataforma.
Operaciones de seguridad (SO) El equipo que administra las líneas de base de
parches y las aprobaciones.
Gerente de operaciones de seguridad (SOM) El gerente responsable del cumplimiento de
parches.
Matriz RACI
La siguiente matriz responsable, responsable, consultada e informada (RACI) especifica las actividades
involucradas con la solución de administración de parches. Para cada paso del proceso, enumera las
partes interesadas y su participación:
• R— responsable de completar el paso
• UNA— responsable de aprobar y firmar el trabajo
• C— consultado para proporcionar información para una tarea
• I— informado de los progresos, pero no directamente involucrados en la tarea
Solución de CPO CBO CE SO SOM C
administración
de parches
Ejecución A C R C C I
de hoja
de ruta de
productos de
administración
Arquitectura A I R C I
y diseño de
administración
de parches
Desarrollo y A R C
configuración
de
administración
de parches
Validación y A I R I I
pruebas de
administración
de parches
NuevoAWSincorporación
A C R I
de cuentas,
aplicaciones
y servidores
para parches
17AWSDirectrices prescriptivas Parches
automatizados para instancias mutables en la
nube híbrida medianteAWS Systems Manager
Matriz RACI
Solución de CPO CBO CE SO SOM C
administración
de parches
Participación A R I I I
y habilitación
de los
usuarios
Gestión A R I I
de la
escalación y
comentarios
de los
usuarios
Administración A R C I
de cambios
de productos
Gestión y A R C
resolución
de
problemas
Aplicación C C AR
de parches y
cumplimiento
de parches
de
Configuración C R A C
de referencia
de parches
Informes de C R AR I
parches y
cumplimiento
18AWSDirectrices prescriptivas Parches
automatizados para instancias mutables en la
nube híbrida medianteAWS Systems Manager
Pasos siguientes
En esta guía se describe una solución de parches automatizada para instancias mutables enAWSe
instancias locales en un entorno de nube híbrida. Para crear la solución, recomendamos consultar la
documentación de laAWSservicios descritos en esta guía. Si tiene alguna pregunta, póngase en contacto
con suAWSequipo de cuentas para obtener asistencia.
Para obtener más información, consulte laRecursos adicionales (p. 20)sección.
19AWSDirectrices prescriptivas Parches
automatizados para instancias mutables en la
nube híbrida medianteAWS Systems Manager
Recursos adicionales
AWSrecursos
• AWSDirectrices prescriptivas
• Documentación de AWS
• AWSReferencia general de
• AWSglosario
AWSServicios de
• AWS CloudFormation
• Amazon CloudWatch
• Amazon EC2
• IAM
• AWS Lambda
• Amazon QuickSight
• AWS Systems Manager
Otros recursos
• Aplicación de parches de instancias Amazon EC2 en subredes privadas UsoAWS Systems
Manager(AWSGestión y gobernanza (blog)
• Cómo usa Moody'sAWS Systems Managerpara aplicar parches a servidores en varios proveedores de
nube(AWSGestión y gobernanza (blog)
• Configuración deAWS Systems Managerpara entornos híbridos(documentación de Systems Manager)
• Aplicación de parches centralizada en varias cuentas y regiones conAWS Systems
ManagerAutomatización(AWSGestión y gobernanza (blog)
• Aplicación de parches para las instancias Amazon EC2 medianteAWS Systems ManagerAdministrador
de parches de(AWSGestión y gobernanza (blog)
• Cómo aplicar parches, inspeccionar y proteger las cargas de trabajo de Microsoft Windows enAWS—
Parte 1(AWSBlog de seguridad)
20AWSDirectrices prescriptivas Parches
automatizados para instancias mutables en la
nube híbrida medianteAWS Systems Manager
AWSGlosario de guía prescriptiva
Términos de IA y ML (p. 21)|Condiciones de migración (p. 22)|Plazos de modernización (p. 27)
Términos de IA y ML
Los siguientes son términos utilizados comúnmente en estrategias, guías y patrones relacionados con la inteligencia
artificial (IA) y el aprendizaje automático (ML) proporcionados porAWSDirectrices prescriptivas. Para sugerir entradas,
utilice elProporcionar comentariosenlace al final del glosario.
clasificación binaria Proceso que predice un resultado binario (una de las dos clases posibles). Por
ejemplo, es posible que su modelo de ML tenga que predecir problemas como
«¿Es spam de correo electrónico o no spam?» o «¿Este producto es un libro o un
automóvil?»
clasificación Proceso de categorización que ayuda a generar predicciones. Los modelos ML
para problemas de clasificación predicen un valor discreto. Los valores discretos
siempre son distintos unos de otros. Por ejemplo, un modelo podría tener que
evaluar si hay o no un automóvil en una imagen.
Preprocesamiento de datos Para transformar datos sin procesar en un formato que su modelo de ML analiza
fácilmente. El procesamiento previo de los datos puede significar eliminar
determinadas columnas o filas y corregir valores faltantes, incoherentes o
duplicados.
conjunto profundo Combinar varios modelos de deep learning para la predicción. Puede utilizar
conjuntos profundos para obtener una predicción más precisa o para estimar la
incertidumbre en las predicciones.
aprendizaje profundo Subcampo ML que utiliza varias capas de redes neuronales artificiales para
identificar la asignación entre los datos de entrada y las variables de destino de
interés.
análisis de datos exploratorios El proceso de análisis de un conjunto de datos para comprender sus principales
(EDA) características. Recopila o agrupa datos y, a continuación, realiza investigaciones
iniciales para encontrar patrones, detectar anomalías y comprobar las
suposiciones. EDA se realiza calculando estadísticas resumidas y creando
visualizaciones de datos.
21AWSDirectrices prescriptivas Parches
automatizados para instancias mutables en la
nube híbrida medianteAWS Systems Manager
features Los datos de entrada que se utilizan para realizar una predicción. Por ejemplo, en
un contexto de fabricación, las entidades podrían ser imágenes que se capturan
periódicamente de la línea de fabricación.
transformación de funciones Optimizar los datos para el proceso de ML, incluido enriquecer datos con fuentes
adicionales, escalar valores o extraer varios conjuntos de información de un único
campo de datos. Esto permite que el modelo ML se beneficie de los datos. Por
ejemplo, si desglosa la fecha «2021-05-27 00:15:37» en «2021», «mayo», «jue»
y «15», puede ayudar al algoritmo de aprendizaje a aprender patrones matizados
asociados con diferentes componentes de datos.
Clasificación multiclase Proceso que ayuda a generar predicciones para varias clases (predicción de
uno de más de dos resultados). Por ejemplo, un modelo de ML podría preguntar:
«¿Este producto es un libro, un automóvil o un teléfono?» o «¿Qué categoría de
producto es más interesante para este cliente?»
regresión Técnica ML que predice un valor numérico. Por ejemplo, para resolver el problema
de «¿A qué precio se venderá esta casa?» un modelo ML podría utilizar un modelo
de regresión lineal para predecir el precio de venta de una casa basándose en
hechos conocidos sobre la casa (por ejemplo, el metro cuadrado).
formación Para proporcionar datos para que su modelo de ML pueda aprender de ellos. Los
datos de entrenamiento deben contener la respuesta correcta. El algoritmo de
aprendizaje encuentra patrones en los datos de entrenamiento que asignan los
atributos de los datos de entrada al destino (la respuesta que desea predecir).
Produce un modelo ML que captura estos patrones. A continuación, puede utilizar
el modelo de ML para realizar predicciones sobre datos nuevos para los que no se
conoce el destino.
variable de destino El valor que intenta predecir en ML supervisada. A esto también se le conoce
comovariable de resultado. Por ejemplo, en un ajuste de fabricación, la variable de
destino podría ser un defecto del producto.
ajuste Cambiar aspectos del proceso de formación para mejorar la precisión del modelo
ML. Por ejemplo, puede entrenar el modelo de ML mediante la generación de un
conjunto de etiquetas, la adición de etiquetas y, a continuación, la repetición de
estos pasos varias veces en diferentes configuraciones para optimizar el modelo.
incertidumbre Concepto que se refiere a información imprecisa, incompleta o desconocida que
puede socavar la fiabilidad de los modelos ML predictivos. Existen dos tipos de
incertidumbre: Incertidumbre epistémicase debe a datos limitados e incompletos,
mientras queincertidumbre aleatoriaes causada por el ruido y la aleatoriedad
inherentes a los datos. Para obtener más información, consulte laCuantificación de
la incertidumbre en los sistemas de aprendizaje profundoguía.
Condiciones de migración
Los siguientes son términos utilizados comúnmente en las estrategias, guías y patrones relacionados con la migración
proporcionados porAWSDirectrices prescriptivas. Para sugerir entradas, utilice elProporcionar comentariosenlace al
final del glosario.
7 Rs Siete estrategias de migración comunes para mover aplicaciones a la nube. Estas
estrategias se basan en las 5 R que Gartner identificó en 2011 y consisten en lo
siguiente:
• Refactor/re-arquitectos: mueva una aplicación y modifique su arquitectura
aprovechando al máximo las características nativas de la nube para mejorar
la agilidad, el rendimiento y la escalabilidad. Normalmente, esto implica portar
22AWSDirectrices prescriptivas Parches
automatizados para instancias mutables en la
nube híbrida medianteAWS Systems Manager
el sistema operativo y la base de datos. Ejemplo: Migrar su base de datos de
Oracle local a Amazon Aurora PostgreSQL Edición compatible con
• Replataforma (levantar y remodelar): mueva una aplicación a la nube e
introduzca cierto nivel de optimización para aprovechar las capacidades de
la nube. Ejemplo: Migración de su base de datos de Oracle local a Amazon
Relational Database Service (Amazon RDS) para Oracle enAWSCloud.
• Recompra (entrega y tienda): cambie a un producto diferente, normalmente
cambiando de una licencia tradicional a un modelo SaaS. Ejemplo: Migrar su
sistema de gestión de relaciones con el cliente (CRM) a Salesforce.com.
• Realojar (levantar y cambiar): mueve una aplicación a la nube sin realizar ningún
cambio para aprovechar las capacidades de la nube. Ejemplo: Migración de su
base de datos de Oracle local a Oracle en una instancia EC2 en laAWSCloud.
• Reubicación (elevación y desplazamiento a nivel de hipervisor): mueva la
infraestructura a la nube sin comprar hardware nuevo, reescribir aplicaciones ni
modificar sus operaciones existentes. Este escenario de migración es específico
de VMware Cloud onAWS, que admite compatibilidad con máquinas virtuales
(VM) y portabilidad de cargas de trabajo entre su entorno local yAWS. Puede
utilizar las tecnologías de VMware Cloud Foundation desde sus centros de datos
locales cuando migra su infraestructura a VMware Cloud onAWS. Ejemplo:
Reubicar el hipervisor que aloja la base de datos Oracle en VMware Cloud
onAWS.
• Retener (volver a visitar): mantenga las aplicaciones en su entorno de origen.
Estos pueden incluir aplicaciones que requieren una refactorización importante,
y desea posponer ese trabajo hasta un momento posterior, y aplicaciones
heredadas que desea conservar, porque no hay justificación empresarial para
migrarlas.
• Retirar: retira o elimina aplicaciones que ya no son necesarias en el entorno de
origen.
cartera de aplicaciones Recopilación de información detallada sobre cada aplicación utilizada por una
organización, incluido el costo de crear y mantener la aplicación y su valor
empresarial. Esta información es clave parael proceso de descubrimiento y análisis
de carteray ayuda a identificar y priorizar las aplicaciones que se van a migrar,
modernizar y optimizar.
operaciones de inteligencia Proceso de uso de técnicas de aprendizaje automático para resolver problemas
artificial (AIOps) operativos, reducir los incidentes operativos y la intervención humana y aumentar la
calidad del servicio. Para obtener más información acerca de cómo se utiliza AIOps
en laAWSestrategia de migración, consulte laguía de integración de operaciones.
AWSMarco de adopción de la Un marco de directrices y mejores prácticas deAWSpara ayudar a las
nube (AWSCAF) organizaciones a desarrollar un plan eficiente y eficaz para trasladarse
correctamente a la nube.AWS CAF organiza orientación en seis áreas de enfoque
denominadas perspectivas: negocios, personas, gobierno, plataforma, seguridad
y operaciones. Las perspectivas de negocio, personal y gobernanza se centran
en las habilidades y los procesos empresariales; las perspectivas de plataforma,
seguridad y operaciones se centran en las habilidades y los procesos técnicos.
Por ejemplo, la perspectiva de las personas se dirige a las partes interesadas
que manejan recursos humanos (RRHH), funciones de dotación de personal y
gestión de personas. Para esta perspectiva,AWSCAF proporciona orientación
para el desarrollo de personas, la formación y las comunicaciones para ayudar a
preparar a la organización para una adopción exitosa de la nube. Para obtener más
información, consulte laAWSSitio web de CAFy laAWSDocumento técnico de CAF.
AWSlanding zone Una landing zone es una cuenta multicuenta bien diseñadaAWSentorno escalable
y seguro. Este es un punto de partida desde el que sus organizaciones pueden
lanzar e implementar rápidamente cargas de trabajo y aplicaciones con confianza
23AWSDirectrices prescriptivas Parches
automatizados para instancias mutables en la
nube híbrida medianteAWS Systems Manager
en su entorno de seguridad e infraestructura. Para obtener más información sobre
las zonas de aterrizaje, consulteConfiguración de una cuenta múltiple segura y
escalableAWSentorno.
AWSMarco de calificación de Herramienta que evalúa las cargas de trabajo de migración de bases de datos,
cargas de trabajo (AWSWQF) recomienda estrategias de migración y proporciona estimaciones de trabajo.AWS
WQF se incluye enAWS Schema Conversion Tool(AWS SCT). Analiza esquemas
de base de datos y objetos de código, código de aplicación, dependencias y
características de rendimiento, y proporciona informes de evaluación.
planificación de la continuidad Un plan que aborda el impacto potencial de un evento disruptivo, como una
del negocio (BCP) migración a gran escala, en las operaciones y permite a una empresa reanudar las
operaciones rápidamente.
Cloud Center of Excellence Un equipo multidisciplinario que impulsa los esfuerzos de adopción de la nube
(CCoE) en toda la organización, incluido el desarrollo de mejores prácticas de nube, la
movilización de recursos, el establecimiento de plazos de migración y la dirección
de la organización a través de transformaciones a gran escala. Para obtener
más información, consulte laPublicaciones del CCoEen elAWSBlog de estrategia
empresarial en la nube.
etapas de adopción en la nube Las cuatro fases por las que suelen pasar las organizaciones cuando migran
alAWSCloud:
• Proyecto: ejecución de algunos proyectos relacionados con la nube con fines de
prueba de concepto y aprendizaje
• Fundación: realizar inversiones fundamentales para escalar la adopción de
la nube (por ejemplo, crear una landing zone, definir un CCoE, establecer un
modelo de operaciones)
• Migración: migración de aplicaciones individuales
• Reinvención: optimización de productos y servicios e innovación en la nube
Estas etapas fueron definidas por Stephen Orban en la entrada del blog.El viaje
hacia la nube primero y las etapas de adopciónen elAWSBlog de estrategia
empresarial en la nube. Para obtener información sobre cómo se relacionan con
laAWSestrategia de migración, consulte laguía de preparación para la migración.
base de datos de Base de datos que contiene información sobre los productos, configuraciones
administración de e interdependencias de hardware y software de una empresa. Normalmente se
configuración (CMDB) utilizan datos de un CMDB en la etapa de detección y análisis de la cartera de
migración.
epopeya En metodologías ágiles, categorías funcionales que ayudan a organizar y priorizar
su trabajo. Epics proporciona una descripción de alto nivel de los requisitos y
las tareas de implementación. Por ejemplo,AWSLas épicas de seguridad de
CAF incluyen administración de identidades y accesos, controles de detectives,
seguridad de infraestructura, protección de datos y respuesta a incidentes. Para
obtener más información acerca de las épicas en laAWSestrategia de migración,
consulte laguía de implementación del programa.
migración de bases de datos Migración de la base de datos de origen a una base de datos de destino que utiliza
heterogénea otro motor de base de datos (por ejemplo, Oracle a Amazon Aurora). La migración
heterogénea suele formar parte de un esfuerzo de reestructuración y convertir el
esquema puede ser una tarea compleja.AWSproporcionaAWS SCTque ayuda con
las conversiones de esquemas.
migración de bases de datos Migración de la base de datos de origen a una base de datos de destino que
homogénea comparte el mismo motor de base de datos (por ejemplo, Microsoft SQL Server
24También puede leer

















































