ECLAC approach to poverty mapping - El enfoque de CEPAL en el mapeo de la pobreza
←
→
Transcripción del contenido de la página
Si su navegador no muestra la página correctamente, lea el contenido de la página a continuación
ECLAC approach to poverty mapping
El enfoque de CEPAL en el mapeo de la pobreza
Andrés Gutiérrez
2021
SDG / ODS
2
No Poverty / Poner fin a la pobreza
1.1 By 2030, eradicate extreme poverty for all 1.1. De aquí a 2030, erradicar para todas las
people everywhere. personas y en todo el mundo la pobreza extrema.
1.2 By 2030, reduce at least by half the proportion 1.2. De aquí a 2030, reducir al menos a la mitad la
of men, women and children of all ages living in proporción de hombres, mujeres y niños de todas
poverty in all its dimensions according to national las edades que viven en la pobreza en todas sus
definitions. dimensiones con arreglo a las definiciones
nacionales.
3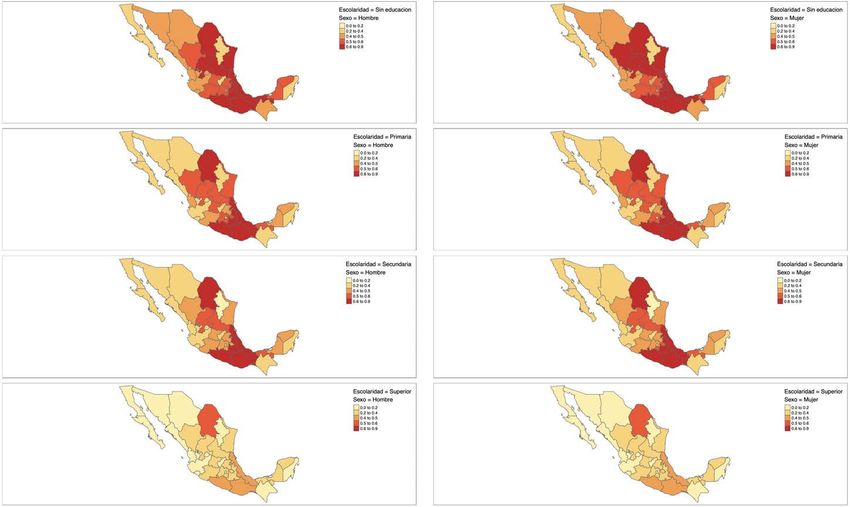
Leave no one behind / No dejar a nadie atrás
Sustainable Development Goal indicators should be Desglosar los ODS por ingreso, sexo, edad, raza,
disaggregated, where relevant, by income, sex, age, etnicidad, estado migratorio, discapacidad y ubicación
race, ethnicity, migratory status, disability and geográfica, de conformidad con los Principios
geographic location, or other characteristics, in Fundamentales de las Estadísticas Oficiales.
accordance with the Fundamental Principles of Official
Statistics. Marco de indicadores globales para los Objetivos
de Desarrollo Sostenible (A/RES/71/313).
Global indicator framework for the Sustainable
Development Goals (A/RES/71/313).
5
Household surveys limitations and the use of auxiliary
information
Limitaciones de las encuestas de hogares y el uso de información auxiliar
6
¿What is it all about? / ¿De qué se trata?
Surveys that depend on a large sample size and a Las encuestas que dependen de un buen tamaño de
proper sampling strategy rely on a robust inferential muestra y una estrategia de muestreo adecuada se
system that provides precise and exact estimation in basan en un sistema inferencial sólido que
planned domains. proporciona una estimación precisa y exacta en los
dominios planificados.
When the sample size of the survey is not enough, it is
necessary to resort to external auxiliary information Cuando el tamaño muestral de la encuesta no es
(censuses, administrative records, satellite images) so suficiente para sustentar la inferencia estadística
that a precise and exact inferential system can be requerida para algunos subgrupos de interés, es
built. necesario recurrir a información auxiliar externa para
que en conjunto se puede construir un sistema
inferencial preciso y exacto.
7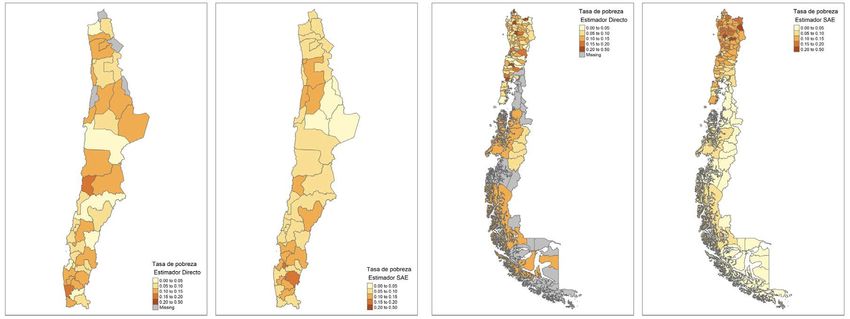
Solutions / Soluciones
When the sample size does not allow obtaining Cuando el tamaño de la muestra no permite obtener
reliable direct estimates for some domains of interest, estimaciones directas confiables para algunos
the following options can be addressed: dominios de interés, se pueden abordar las siguientes
opciones:
1. Increase the sample size: this option raises costs,
and it is unfeasible. 1. Incrementar el tamaño de la muestra: esta opción
2. Use statistical methodologies that involve eleva los costos y es inviable.
external auxiliary information to obtain reliable 2. Utilizar metodologías estadísticas que involucren
estimates (not direct) in the subgroups of información auxiliar externa para obtener
interest, while keeping the survey sample size. estimaciones confiables (no directas) en los
subgrupos de interés, mientras se mantiene el
tamaño de la muestra de la encuesta.
8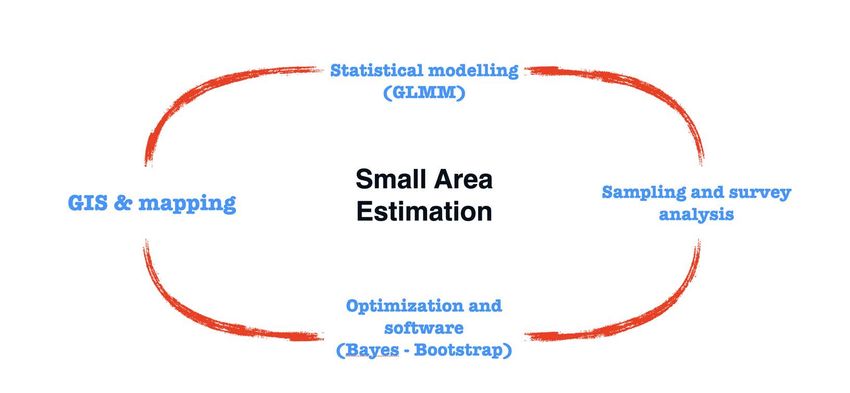
Borrowing strength / Tomando fuerza prestada
Source: Methodology of Modern Business Statistics (2014).
9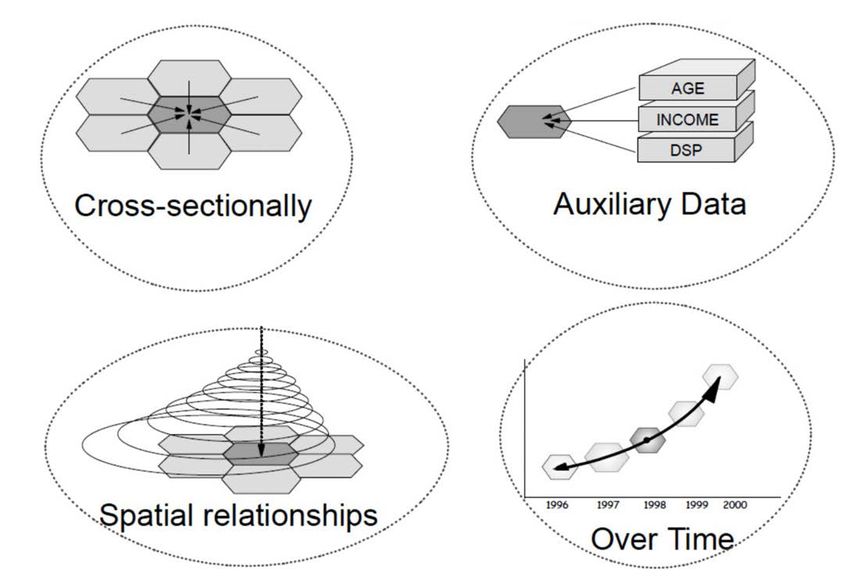
SAE methodologies in ECLAC
Metodologías SAE en la CEPAL
10
SAE methodologies / Metodologías SAE
Source: adaptation from Rahman (2008).
11Two types of methods / Dos clases de métodos
SAE estimators used in ECLAC could be divided into Los estimadores de SAE se dividen en dos tipos
two main types: principales:
1. Estimators based on area models 1. Estimadores basados en modelos de área
2. Estimators based on unit models 2. Estimadores basados en modelos de unidad
The choice of the method that should be used in the La escogencia del método que se debe utilizar en la
estimation of the domains of interest is made estimación de los dominios de interés se realiza
depending on the level at which the auxiliary dependiendo del nivel en el que se encuentre la
information is found (at the domain or aggregation información auxiliar (a nivel de dominio o agregación
level - at the household or person level) - a nivel de hogar o persona)
12Area-level models
Modelos de áreas
13Direct estimators / Estimadores directos
∑ s d wk y k
ˆ θ^d ) = ∑ ∑
^ Dir Dir ∆kl ek el
θd = AV(
∑ s d wk s s πkl πk πl
The sample size in each area is not planned in El tamaño de muestra en cada área difícilmente
advance (since the sampling scheme follows a es planificado de antemano (pues el esquema de
two-stage sampling). muestreo es bietápico: UPM - Vivienda).
Any estimation of relative indicators (means and Cualquier estimación de indicadores relativos
proportions) will have to make use of a ratio-type (medias, proporciones) tendrá que usar un
estimator: random numerator and random estimador de razón: numerador y denominador
denominator. aleatorios.
When the sample size nd = #(sd ) is not large Cuando el tamaño de muestra nd = #(sd ) no es lo
enough, none of the above estimators will be precise suficientemente grande, entonces ninguno de los
neither consistent. anteriores estimadores será preciso, ni consistente.
16Direct estimators / Estimadores directos
We will model the Direct Estimator so that in the areas Vamos a modelar el indicador directo para que en las
where there is not enough sample, strength will be áreas en las que no haya suficiente muestra se tome
borrowed from the other areas. fuerza prestada de las otras áreas.
Dir Dir
^
θ d = θd + εd εd ∼ N(0, Var(θ^d ))
θd = x′d β + ud ud ∼ N(0, σu2 )
Dir
^
θ d = x′d β + ud + εd
Following (some) Bayes rule, we have that: De la regla de Bayes, se tiene que:
Dir
θd |θ^d ∼ N (θFH
d , σdFH )
2
Dir
θFH ^
= E(θd |θ d ) = γd θDir + (1 − )x ′
d d γd dβ
Dir
σd2F H = V ar(θ^d )γd
19We like the Bayesian way / Nos gusta el enfoque bayesiano
20We like the Bayesian way / Nos gusta el enfoque bayesiano
21Beta-logistic model for poverty / Modelo beta-logístico para la pobreza
22And, we like STAN / Nos gusta STAN
parameters { model {
vector[p] beta; vector[N1] a;
real sigma2_v; vector[N1] b;
vector[N1] v; for (i in 1:N1) {
} a[i] = theta[i] * phi[i];
b[i] = (1 - theta[i]) * phi[i];
transformed parameters{ }
vector[N1] LP; // priors
real sigma_v; beta ~ normal(0, 100);
vector[N1] theta; sigma2_v ~ inv_gamma(0.0001, 0.0001);
LP = X * beta + v; // likelihood
sigma_v = sqrt(sigma2_v); y ~ beta(a, b);
for (i in 1:N1) { v ~ normal(0, sigma_v);
theta[i] = inv_logit(LP[i]); }
}
} generated quantities {
vector[N2] y_pred;
vector[N2] thetapred;
for (i in 1:N2) {
y_pred[i] = normal_rng(Xs[i] * beta,
sigma_v);
thetapred[i] = inv_logit(y_pred[i]);
} 23Unit-level models
Modelo de unidades
24The GMR model / El modelo GMR
ECLAC uses a unit-level model with adjustment to La CEPAL utiliza un modelo de nivel de unidad con
the complex sampling design for the estimation ajuste al diseño complejo de muestreo para la
of average income. estimación del ingreso promedio.
This model was first proposed by Guadarrama, Este modelo fue propuesto por Guadarrama,
Molina, and Rao (2018) and it induces an Molina y Rao (2018) e induce una aproximación
approximation of the best empirical predictor del mejor predictor empírico (Pseudo-EBP)
(Pseudo-EBP) based on the model with nested basado en el modelo con errores anidados
errors (Molina and Rao, 2010). (Molina y Rao, 2010).
25The GMR model / El modelo GMR
26The nested-error model / El modelo de errores anidados
This method assumes that the transformed income Este método asume que la variable de ingresos
variable y∗di = log (ydi + c) follows the model: transformados y∗di = log (ydi + c) sigue el modelo:
y∗di = x′di β + ud + edi ; i = 1, … , Nd , d = 1, … , D,
Where: En donde:
β is the vector of regression coefficients, β es el vector de coeficientes de regresión,
iid iid
ud ∼ N (0, σu2 ) is the area random effect, and ud ∼ N (0, σu2 ) es el efecto de área, y
iid iid
edi ∼ N (0, σe2 ) are the errors for individuals in edi ∼ N (0, σe2 ) son los errores del modelo para
the d-th area and are considered independent los individuos del área d-ésima.
from the random effects.
27Weigthed estimation / Estimación ponderada
Since yd follows a normal distribution, the conditional Dado que yd sigue una distribución normal, la
distribution ydr | yds will also be a normal distribution distribución condicional ydr | yds también será
parameterized as follows: normal parametrizada de la siguiente manera:
ydr |yds ∼ N (µdr|s , Vdr|s ) con d = 1, … , D
To avoid the bias induced by ignoring the sampling Para evitar el sesgo inducido al ignorar el diseño de
design in the model, the parameters of the above muestreo en el modelo, los parámetros de la
distribution may consistently be estimated by distribución anterior se pueden estimar
including the sampling weights wkd . constantemente incluyendo los pesos de muestreo
wkd .
^ N −n
^ dr|s = Xdr β^ + γ^d (ȳ dw − x̄′dw β)1
µ d d
2 2
^ dr|s = (^
V ^u (1 − γ^d ))1Nd −nd 1TNd −nd
σe + σ
29Monte Carlo estimation / Estimación de Monte Carlo
Since it is not possible to identify and link the units of Como no es posible identificar y vincular las unidades
the sample with those of the census, then the de la muestra con las del censo, el enfoque utilizado
approach used is a Census-EB type, as follows: es de tipo Census-EB, de la siguiente manera:
~ 1
θd = ∑ E(I ydiSome maps
Algunos mapas
32Processes in production of SAE / Procesos en la producción SAE
Source: adaptation from Kolenikov (2014).
33Perú
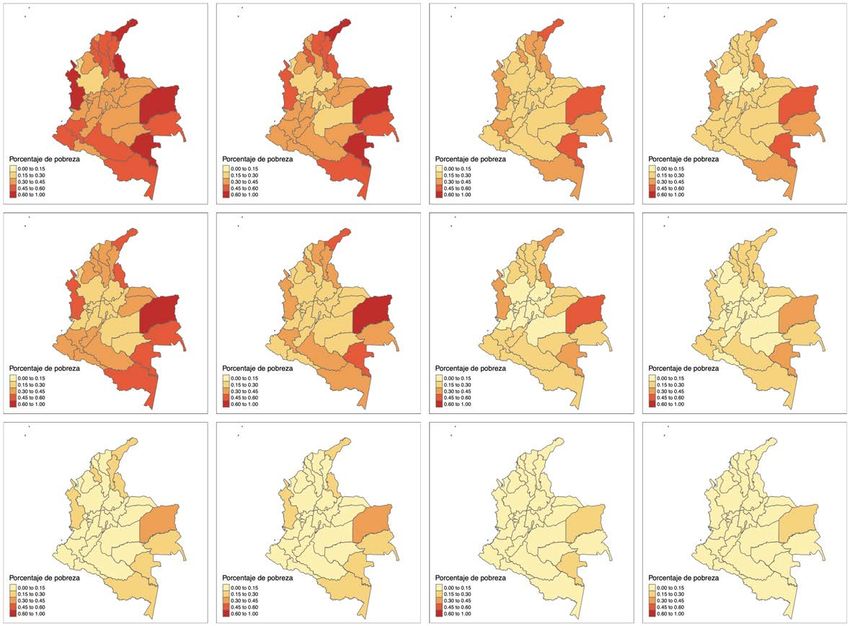
34Colombia
35Chile
36Leaving no one behind
No dejando a nadie detrás
37Colombia: age and education / edad y educación
38México: ethnicity and education / étnia y educación
39México: sex and education / sexo y educación
40Thanks!
rolando.ocampo@un.org
xavier.mancero@un.org
andres.gutierrez@un.org
¡Gracias!
41También puede leer

















































