Predicción de la Demanda de un Nuevo Producto para una Empresa Importadora, usando Series de Tiempo - MTI
←
→
Transcripción del contenido de la página
Si su navegador no muestra la página correctamente, lea el contenido de la página a continuación
Universidad Técnica Federico Santa María
Departamento de Informática
Magíster en Tecnologías de la Información
Predicción de la Demanda de un Nuevo Producto para una Empresa
Importadora, usando Series de Tiempo.
José Ignacio Uribe Mujica
jose.uribem@sansano.usm.cl
Resumen: La habilidad para crear pronósticos y descubrir tendencias es una fuerte ventaja en cualquier
industria. Este proyecto considera el problema de una empresa importadora que está frente al desafío de
comercializar un nuevo producto, el cual tiene como referencia las ventas pasadas de uno de similares
características. Para esto se lleva a cabo una investigación mediante series de tiempo, utilizando la
metodología CRISP-DM, que intenta encontrar un modelo que permita realizar pronósticos sobre la
tendencia y estacionalidad de las ventas de este nuevo producto. El desarrollo central del trabajo incluye
secciones de análisis del negocio y de datos, las que permiten tener una base sólida de conocimiento para
enfrentar la tarea. Luego, se realizan varias iteraciones que van intentando mejorar la precisión predictiva
a través de distintos métodos como la descomposición, ARIMA, suavizamiento exponencial, árbol de
decisión y redes neuronales. Posteriormente se ejecuta una técnica llamada stacking¸ la que propone
utilizar más de un método para la obtención de un modelo de pronósticos, permitiendo mejorar de manera
considerable la precisión de los resultados obtenidos.
Palabras Clave: minería de datos, series de tiempo, CRISP-DM, pronósticos.
1 Introducción
1.1 Contexto
La Empresa Las Hermanas (ELH) es una fabricadora e importadora de productos para la industria gastronómica,
con presencia en el mercado chileno desde 1980. Desde su creación ha sido un actor importante en su industria,
siendo reconocida por sus clientes como una compañía seria, responsable y que ofrece productos de calidad,
junto a un servicio técnico personalizado. En sus inicios se dedicaba exclusivamente a la fabricación de
máquinas, pero luego la industria y el mercado fueron evolucionando, lo que obligó a ELH a comenzar a
importar algunos de sus productos, así como a incorporar otros nuevos a su gama. Junto con este cambio, la
empresa también comenzó a incursionar en el mercado de los insumos para la industria en cuestión, abriendo
más opciones a la oferta entregada a sus clientes.
En el año 2009 se adjudica la representación de una marca de bases para la fabricación de helados QH. Durante
nueve años la empresa fue el representante exclusivo de esta marca en el país, hasta que el año 2018 ésta decide
instalarse de manera independiente en Chile. Luego de varios meses de investigación, análisis y negociaciones,
ELH se adjudicó una nueva representación de otra marca del mismo tipo de producto, llamada MT.
1.2 Definición del Problema
MT es un nuevo producto para la empresa ELH; por lo tanto, se ha solicitado hacer una estimación de las ventas
que podría tener este nuevo producto. Para hacer este pronóstico de demanda se propone realizar un estudio
basado en series de tiempo. Se pretende que este análisis entregue un resultado con mayor precisión que una
proyección simple de las ventas actuales, que podrían ser obtenidas, por ejemplo, con modelos de regresión
lineal o promedios móviles simples.
1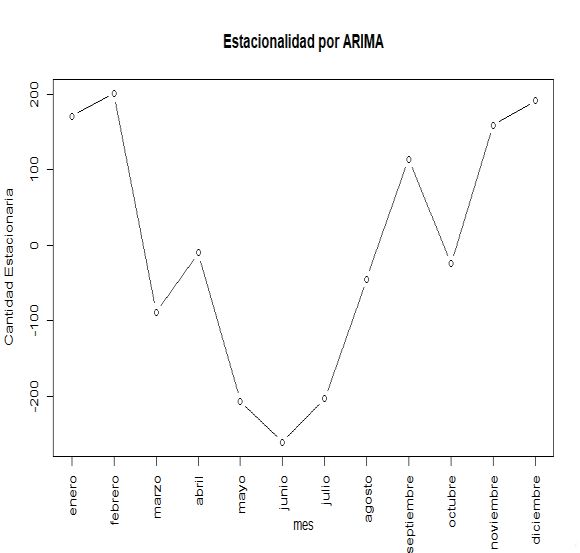
Universidad Técnica Federico Santa María
Departamento de Informática
Magíster en Tecnologías de la Información
Con los resultados de este ejercicio, ELH podrá hacer estimaciones de ventas para su nuevo producto, el cual
se cree que podría tener estacionalidad, ya que los helados se consumen mayormente en verano, como una
medida para combatir la sensación de calor. Al finalizar el estudio, se entregará a ELH un patrón de pronóstico
que permitirá a la compañía estar un paso adelante al momento de estimar las ventas, a través de un modelo
encontrado luego de un minucioso trabajo de investigación.
La anticipación a los hechos, sobre todo en materia de estimación de ventas, es un área que comparten
probablemente todas las empresas de las distintas industrias, tanto productivas como de servicios, por lo que el
problema planteado para el estudio de la presente tesina podría ser de utilidad para otras compañías, realizando
los ajustes correspondientes y proponiendo y estudiando las condiciones necesarias para cada una en particular.
1.3 Hipótesis y Metodología de Validación
El problema planteado supone estudiar y analizar los datos de ventas actuales y con ellos intentar predecir las
ventas futuras del nuevo producto. Por lo tanto, la hipótesis que se plantea validar es la siguiente:
“Utilizando análisis de series de tiempo es posible predecir, con un nivel de confianza superior al 75%, la
demanda de un nuevo producto, conociendo el comportamiento anterior de uno similar”.
Las variables a considerar en el presente estudio serán el agregado de ventas mensuales y la fecha (mes-año).
El valor a predecir será la cantidad de producto a vender para uno o más meses en el futuro, dependiendo los
resultados que se obtengan en el ejercicio.
La metodología seleccionada para enfrentar el problema es CRISP-DM, la cual, como se detalla en el marco
teórico, es la que mejor permite ir perfeccionando el modelo, intentando encontrar la solución que de mejor
manera permita encontrar una solución satisfactoria al problema, manteniendo el enfoque en el negocio, tanto
en sus primeras etapas como en la final.
Para construir y validar un modelo de predicción basado en series de tiempo es necesario, en primer lugar,
reunir los datos que están almacenados actualmente en la base de datos de la compañía. Luego, con los datos
normalizados y preparados para el estudio, se realiza el análisis, para lo cual se considera una porción de los
datos existentes, con los cuales se van creando modelos que luego son evaluados y comparados contra los
restantes datos reales [1]. De esta forma se va encontrando evidencia de cuál modelo es el que entrega mayor
confianza y menor error al momento de hacer la predicción; entre las métricas existentes para medir la confianza
se encuentran la correlación, el error relativo, error cuadrático medio y la raíz del error cuadrático medio. Cabe
destacar que, en el presente proyecto, se considera que un modelo es exitoso al entregar la predicción con un
nivel de confianza superior al 75% [2].
1.4 Objetivos
El objetivo general del presente estudio es utilizar una metodología aceptada ampliamente por la industria, para
crear un modelo de predicción de ventas que permita hacer pronósticos confiables, basados en análisis de series
de tiempo.
Para lograr el objetivo planteado, se establecen los siguientes objetivos específicos:
• Entender en su totalidad el negocio general de la empresa ELH y en particular el del nuevo producto MT,
con el fin de contar con una base sólida que permita mantener claro el objetivo general de la tesina y
trabajar en dirección a éste.
• Recolectar, entender y preparar los datos disponibles, para disponer de la mayor y mejor cantidad de
información posible en la etapa de desarrollo.
• Diseñar y Construir los data mart necesarios, para llevar a cabo la etapa de modelado y descubrimiento
de patrones temporales.
• Usar los datos ya refinados para encontrar un modelo que permita predecir, con una confianza superior al
75%, la demanda del producto MT.
• Entregar el modelo a la Empresa para su uso en un ambiente real, aplicando lo aprendido durante el
Magíster a un entorno profesional real de trabajo.
2Universidad Técnica Federico Santa María
Departamento de Informática
Magíster en Tecnologías de la Información
1.5 Estructura de la Tesina
El proyecto de Tesina está compuesto por 6 capítulos:
• Introducción: se explica de manera general el problema planteado, hipótesis, metodología de solución
propuesta, objetivos y estructura de la tesina.
• Marco Teórico: se muestra la base teórica relacionada con el tema en estudio, con explicación sobre la
minería de datos, series de tiempo, modelos y métricas.
• Estado del Arte: se presenta algunos estudios publicados por académicos, mostrando distintas visiones,
enfoques, resultados y conclusiones sobre los métodos aplicados.
• Desarrollo: se llevan a cabo las distintas etapas de la metodología CRISP-DM aplicadas al problema en
cuestión.
• Validación de Hipótesis: se analizan los resultados obtenidos de la etapa de desarrollo y su aporte hacia
la validación de la hipótesis.
• Conclusiones: se discuten los resultados de las distintas etapas, evalúan los objetivos, y se presentan
consideraciones y sugerencias para futuros estudios similares.
2 Marco Teórico
2.1 Minería de Datos
De acuerdo a la Enciclopedia Británica, la minería de datos (MD) es el proceso de descubrir patrones y
relaciones útiles e interesantes a partir de grandes volúmenes de datos [w-1]. Este campo combina herramientas
de la estadística e inteligencia artificial, con bases de datos, para analizar enormes colecciones de datos en
formato digital, también conocidos como data sets.
A medida que la capacidad de almacenamiento de los sistemas computacionales comenzó a aumentar
drásticamente en la década de 1980, muchas compañías comenzaron a guardar cada vez mayor cantidad de
datos de sus transacciones. Pero las colecciones resultantes, llamados data warehouse, resultaron ser muy
grandes para ser analizados con herramientas estadísticas tradicionales. Después de un largo tiempo donde se
llevaron a cabo conferencias y workshops, en 1997 se lanzó el documento “Minería de Datos y Descubrimiento
del Conocimiento” [w-1].
2.1.1 Modelos y Métodos
Existen 2 tipos de análisis que se pueden llevar a cabo en la MD [3]:
• Modelos Predictivos: se usan cuando la finalidad del estudio es estimar el valor de un atributo en
particular, donde existen datos que son usados como entrenamiento para el modelo y los restantes que
sirven para la validación del mismo. Los modelos predictivos son de clasificación, de regresión o de
pronóstico, estos últimos también conocidos como series de tiempo.
• Modelos Descriptivos: la finalidad es entender y describir los datos disponibles, para formar grupos que
sean homogéneos entre sí. Los modelos descriptivos son de visualización, asociación, correlaciones y
dependencias, segmentación o detección de anomalías.
En cuanto a los métodos utilizados en minería de datos, algunos de ellos son [4]:
• Clasificación: los datos son divididos en clases-objetivo. Las técnicas de clasificación predicen la clase-
objetivo para cada dato. Algunos de los algoritmos de clasificación son: K-Nearest Neighbour (KNN),
Árbol de Decisión, Máquina de Soporte Vectorial, Red Neuronal Artificial y Métodos Bayesianos.
• Regresión: es utilizada para encontrar funciones que sean capaces de explicar la correlación entre
diferentes variables. Se construye un modelo matemático usando grupos de datos para entrenamiento. Se
3Universidad Técnica Federico Santa María
Departamento de Informática
Magíster en Tecnologías de la Información
requiere una variable dependiente y al menos una variable independiente. La regresión es un método
estadístico que estudia la relación entre estas variables. Estas regresiones pueden ser lineales, para el caso
en que el resultado pueda ser representado como una línea en un gráfico, o lógica, la cual permite predecir
cuando existen datos en categorías. A su vez, la regresión lógica puede ser binominal, donde el resultado
esperado tiene solo dos opciones posibles, o multinominal, donde existen tres o más resultados posibles.
• Agrupamiento: es un método de aprendizaje no-supervisado diferente a la clasificación, ya que no cuenta
con clases predefinidas. Bases de datos de gran tamaño son separadas en pequeños grupos de datos. Este
método es utilizado para identificar similitudes entre distintos éstos. Algunas técnicas de agrupamiento
son: partición (se define el número de grupos a priori), jerárquica (no hay grupos predefinidos, los datos
se separan por jerarquía en el algoritmo), basado en densidad (para manejar datos más dispersos y difíciles
de agrupar) y asociación (para encontrar patrones frecuentes y relaciones).
2.1.2 Metodologías de Trabajo
A continuación, se muestran las metodologías más comunes para llevar a cabo un proyecto de MD, las cuales
son KDD, SEMMA y CRISP-DM [5].
KDD (Knowledge Discovery in Databases)
Un proceso KDD usa
métodos de minería de datos
para extraer lo que se supone
es conocimiento de acuerdo a
las especificaciones de
medidas y límites, usando
una base de datos junto a
cualquier pre-proceso
requerido, submuestreo y/o
transformación de datos. Se
consideran cinco etapas en
KDD (mostradas en la figura
2.1), las cuales son: Figura 2.1: Etapas del proceso de KDD. Fuente [A].
• Selección: esta etapa consiste en crear un conjunto de datos objetivo o enfocarse en un subconjunto de
variables donde el descubrimiento será llevado a cabo.
• Procesado: esta etapa se encarga de la limpieza de los datos y de un orden de los mismos con el fin de
tener datos consistentes.
• Transformación: en esta etapa se transforman los datos usando reducción de dimensiones o métodos de
transformación.
• Minería de datos: esta etapa consiste en la búsqueda de patrones de interés, dependiendo del objetivo o
técnica utilizada.
• Interpretación/evaluación: la etapa final del proceso KDD consiste en la interpretación y evaluación de
los patrones encontrados.
4Universidad Técnica Federico Santa María
Departamento de Informática
Magíster en Tecnologías de la Información
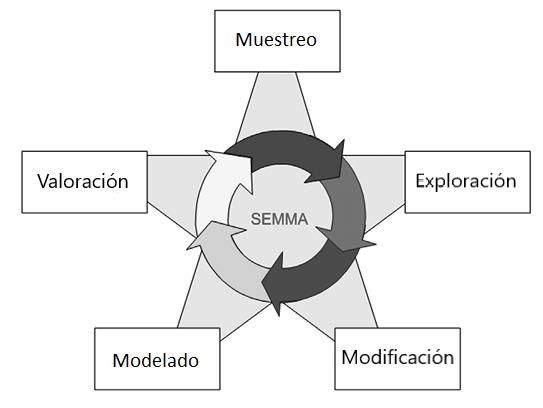
SEMMA (Sample, Explore, Modify, Model, Assess)
SEMMA se enfoca en el proceso de conducir un
proceso de MD. El Instituto SAS1 considera un ciclo
de cinco etapas para el proceso SEMMA (las que se
muestran en la Figura 2.2):
• Muestreo: se selecciona una muestra de los
datos, extrayendo una porción de los datos
originales, de un tamaño lo suficientemente
grande para contener información significante y
a la vez lo suficientemente pequeña para que sea
fácil de manipular.
• Exploración: esta etapa consiste en la
exploración de los datos, por medio de la
búsqueda de tendencias y anomalías no
Figura 2.2: Etapas del proceso de SEMMA. Fuente: [B].
anticipadas para tener mayor entendimiento de
los datos.
• Modificación: en esta etapa se modifican los datos por medio de la creación, selección y transformación
de variables para enfocar el proceso de selección del modelo.
• Modelado: esta etapa consiste en modelar los datos permitiendo a un software buscar de manera
automática una combinación de datos capaz de predecir de manera confiable un resultado deseado.
• Valoración: finalmente, se valorar los datos por medio de la evaluación de la usabilidad y confiabilidad
de los descubrimientos realizados por medio del proceso de minería de datos y la estimación de su
rendimiento.
CRISP-DM (Cross-Industry Standard Process for Data Mining)
CRISP-DM [6] es un modelo no-propietario, documentado y de libre disponibilidad de MD. Fue desarrollado
por líderes de la industria con información de más de 200 usuarios, herramientas y proveedores de servicios de
minería de datos. CRISP-DM fomenta las buenas prácticas y ofrece a las organizaciones la estructura necesaria
para obtener mejores resultados en poco tiempo, al usar MD.
CRISP-DM consiste en un ciclo de seis etapas, las que son
representadas en la Figura 2.3:
• Comprensión del Negocio: esta fase inicial se enfoca
en el entendimiento y comprensión de los objetivos y
requerimientos del proyecto desde una perspectiva de
negocios, convirtiendo luego este conocimiento en una
definición de problema de MD, junto a un plan
preliminar diseñado para alcanzar dichos objetivos.
• Comprensión de los Datos: esta fase comienza con
una colección inicial de datos y luego procede con
actividades con el fin de familiarizarse con los datos,
identificar problemas en la calidad de éstos, descubrir
algunos primeros indicios sobre los datos o identificar
subconjuntos interesantes para formar pequeñas Figura 2.3: Etapas del proceso CRISP-DM.
hipótesis sobre la información oculta. Fuente: [C].
1
https://www.sas.com/en_us/home.html
5Universidad Técnica Federico Santa María
Departamento de Informática
Magíster en Tecnologías de la Información
• Preparación de los Datos: en esta etapa se desarrollan todas aquellas actividades involucradas en la
construcción de un conjunto final de datos, a partir de los datos originales.
• Modelado: en esta fase, varias técnicas de modelado son seleccionadas y aplicadas; además los parámetros
de las mismas son probados y calibrados para intentar acercarse a resultados con valores óptimos.
• Evaluación: ya con uno o más modelos obtenidos en la fase anterior, éstos son evaluados de manera más
exhaustiva, y los pasos empleados para construir el modelo son revisados para tener certeza que éste
satisface los objetivos de negocios.
• Despliegue: la creación de un modelo no es el necesariamente el fin del proyecto. Aun cuando el propósito
sea aumentar el conocimiento a partir de los datos, el mismo debe ser organizado y presentado de manera
que permita ser útilmente utilizado.
La metodología CRISP-DM es extremadamente completa y documentada. Todas sus etapas están debidamente
organizadas, estructuradas y definidas, permitiendo que un proyecto sea fácilmente entendido y realizado.
Comparación y Elección
En la figura 2.4 se muestra un
cuadro que compara las etapas de
las tres metodologías presentadas
anteriormente.
CRISP-DM es una herramienta
abierta, de libre disposición, usada
ampliamente por la industria, que
cuenta con una gran
documentación y está ampliamente Figura 2.4: Resumen comparativo de las etapas de las metodologías. Fuente:
aceptada. También es la única de elaboración propia a partir de [5].
las tres que se preocupa tanto del
negocio como de la aplicación de los resultados. Por estas razones, para el desarrollo de la presente tesina se ha
optado por la metodología CRISP-DM para encontrar un modelo que pronostique las ventas futuras del
producto MT, además de validar la hipótesis planteada.
2.2 Series de Tiempo
Desde la publicación de Fayyad en 1996 [7], el área de MD ha generado mucho interés, y hoy en día puede ser
considerado un campo de estudio como tal. Las aplicaciones de MD pueden ser encontradas en un diverso
campo de aplicaciones. Un importante dominio de la aplicación de MD es el de las series de tiempo [8]. El
análisis con series de tiempo provee una solución ideal al problema de correlacionar datos de manera serial [9].
Una serie de tiempo es una colección o conjunto de mediciones de cierto fenómeno o experimento registrados
en el tiempo, en forma equiespaciada (a intervalos de tiempos iguales). Las observaciones de una serie de tiempo
son denotadas por [10]:
x(t1), x(t2), x(t3), …, x(tn)
donde x(ti) es el valor tomado por el proceso en el instante de tiempo i.
Algunos tipos de series de tiempo que son posibles de analizar son las económicas, meteorológicas, geofísicas,
químicas, demográficas, medicas, marketing, telecomunicaciones y transporte.
El primer paso en una serie de tiempo consiste en graficar la serie. Una de las razones más importantes e
influyentes para representar gráficamente una serie de tiempo es para reducir la dimensión visual de los datos
originales [11]. El gráfico de la serie permitirá detectar los siguientes elementos [10]:
6Universidad Técnica Federico Santa María
Departamento de Informática
Magíster en Tecnologías de la Información
• Tendencia: representa el comportamiento de la serie. Esta puede ser definida como el cambio de la media
a lo largo de un extenso período de tiempo.
• Variación cíclica o estacional: representa un movimiento periódico de la serie de tiempo. La duración
del período puede ser un año, un trimestre, un mes, un día, etc. Se suele hacer una distinción entre cíclica
y estacional; estas últimas ocurren con períodos identificables, como la estacionalidad del empleo, o de la
venta de ciertos productos, cuyo período es un año, mientras que variación cíclica se suele referir a ciclos
grandes, cuyo período no es atribuible a alguna causa; como por ejemplo, fenómenos climáticos que tienen
ciclos que duran varios años.
• Variaciones aleatorias: los movimientos irregulares (al azar) representan todos los tipos de movimientos
de una serie de tiempo que no sean tendencia, variaciones cíclicas o estacionales.
• Outliers: se refiere a puntos de la serie que escapan de lo normal. Si se sospecha que una observación es
un outlier, se debe reunir información adicional sobre posibles factores que afectaron el proceso y
determinar si ésta debe removerse o recalcularse.
Los modelos clásicos de series de tiempo suponen
que la serie puede ser expresada como suma o
producto de las tres componentes; tendencia,
variación cíclica o estacional y variaciones aleatorias.
La figura 2.5 muestra un ejemplo genérico (sin
escala) de una serie de tiempo con modelo aditivo.
También existe la descomposición STL (Seasonal
and Trend decomposition using Loess), la que se
separa en los mismos tres componentes, pero luego
hace una interpolación de Loess (interpolación
estacionaria) suavizando el ciclo y con esto
encontrando el componente estacional. Figura 2.5: Serie aditiva y sus componentes. Fuente:
Posteriormente se aplica una nueva interpolación para elaboración propia a partir de [10].
suavizar el componente estacional; y, finalmente, una
tercera interpolación para encontrar una estimación de la tendencia. El proceso se repite en varias iteraciones
para mejorar la precisión de las estimaciones. En este caso, el período de la estacionalidad debe ser previamente
conocido [12].
Existen varias técnicas estadísticas para la predicción con series de tiempo. A continuación, se presentan
aquellas que se consideran más efectivas [w-2][13]:
• Promedio Móvil Simple (SMA): es la
técnica más simple para predicciones.
Básicamente, el promedio móvil se calcula
al sumar los últimos ‘n’ períodos y luego
dividiendo el valor por ‘n’. De esta manera,
el promedio encontrado se considera como
el valor del siguiente período. Estos
promedios pueden ser usados para
identificar de manera rápida si es que, por
ejemplo, una venta está con una tendencia al
alza o a la baja dependiendo del patrón
encontrado por el promedio móvil. Figura 2.6: Promedio móvil simple. Fuente: [w-2].
7Universidad Técnica Federico Santa María
Departamento de Informática
Magíster en Tecnologías de la Información
• Suavizamiento Exponencial (SE): a
diferencia del SMA, esta técnica asigna
valores exponencialmente decrecientes a los
valores más antiguos de la muestra. Con
frecuencia, el modelo es apropiado para los
datos que no tienen una tendencia
predecible al alza o a la baja. Con el
suavizamiento exponencial se reduce el
impacto de las variaciones aleatorias,
entregando un mejor pronóstico. Para su
uso, se utiliza una constante Alpha la cual, a
mayor valor, menor suavizamiento entrega.
• Suavizamiento Exponencial Ajustado a la Figura 2.7: Suavizamiento exponencial. Fuente: [w-2].
Tendencia (Holt): existen series de tiempo que pueden cambiar de nivel ocasionalmente y el SE no es
capaz de captar estos cambios. Este método se utiliza para muestras de datos que muestran tendencias
lineales locales que evolucionan con el tiempo. El suavizamiento exponencial de Holt incorpora una nueva
constante Beta la cual representa el suavizamiento para la estimación de la tendencia.
• Suavizamiento Exponencial Ajustado para Variaciones de Tendencia y Estacionales (Holt-Winters):
este método se utiliza cuando una serie de tiempo aparenta tener un patrón estacional. Es una extensión
del método anterior pero que incorpora un nuevo parámetro Gamma para suavizar la estacionalidad.
• Modelos Autorregresivos (AR): un modelo AR implica que los valores de la variable analizada están
relacionados con los mismos valores de períodos anteriores. Así, los valores anteriores al estudiado se
consideran variables independentes del valor en cuestión. Un modelo AR expresa un pronóstico como una
función de los valores previos de una serie de tiempo.
• Promedio Móvil (MA): los modelos de MA proporcionan pronósticos en base a una combinación lineal
de un número finito de errores pasados. Cada período pasado tendrá un peso en el modelo para intentar
pronosticar el siguiente.
• Promedios Móviles Autorregresivos (ARMA): este modelo utiliza los modelos AR y MA de manera
combinada. Los modelos ARMA pueden describir una amplia variedad de comportamientos de las series
de tiempo. Los pronósticos generados dependerán de los valores reales actuales y anteriores, así como de
los errores encontrados.
• Promedio Móvil Autorregresivo Integrado (ARIMA): esta técnica utiliza parámetros referidos a la
parte autorregresiva (AR), integrada (I) y promedios móviles (MA) de los datos. El análisis Integrado (I)
toma las diferencias entre las tendencias, para intentar dejarlas estacionarias. El modelo se presenta como
ARIMA(p,d,q), donde ‘p’ representa el número de períodos para el análisis de AR, ‘d’ el número de
análisis integrados y ‘q’ el número de períodos para el análisis MA. El modelado mediante ARIMA puede
analizar las tendencias, estacionalidades, ciclos, errores y aspectos no estacionarios de los datos al hacer
predicciones. La idea detrás de los modelos ARIMA es que el residuo final debiese ser casi imperceptible;
es decir, no hay más información que encontrar. ARIMA busca la estacionalidad de los datos, así como
una tendencia. Esta técnica se usa principalmente para proyectar valores futuros utilizando datos histórica.
• Redes Neuronales Artificiales (RNA): son un tipo de técnica de machine learning que modela de manera
semejante al cerebro humano. Su habilidad para aprender mediante el uso de ejemplos, las hacen muy
flexibles y poderosas. Las RNA tienen la virtud de encontrar significado a partir de datos complejos o
imprecisos, y la mayor parte del tiempo son capaces de identificar patrones y tendencias en los datos, que
no pueden ser percibidos fácilmente por el ojo humano u otras técnicas más simples de predicción.
• Árboles de Decisión: usan una estructura de árbol para representar un cierto número de posibles caminos
de decisiones, cada uno llevando a un resultado específico. El tamaño de éstos depende de la profundidad
del árbol, siendo más complejo al tener mayor profundidad. Son modelos fáciles de entender e interpretar.
Su categorización más general comprende los árboles de clasificación y los de regresión, siendo estos
últimos los que producen resultados numéricos y que son utilizados en el presente estudio [14]. Existen
8Universidad Técnica Federico Santa María
Departamento de Informática
Magíster en Tecnologías de la Información
técnicas que construyen más de un árbol de decisión para el mismo problema; entre ellas se encuentran
Random Forest y Gradient Boosted Trees [w-3].
2.3 Herramientas de Minería de Datos
En esta sección se presentan dos de las herramientas de trabajo más utilizadas en el mundo de MD, así como
dos de los lenguajes de programación disponibles en el área [w-4][w-5].
Herramientas de Trabajo
RapidMiner es un programa de data science que provee un ambiente gráfico e integrado para preparación de
datos, machine learning, deep learning, minería de texto y análisis predictivo [15].
Orange es un programa open source para machine learning y análisis de datos. Cuenta con varias librerías y
utiliza scripts programados en Python [w-6].
Lenguajes de Programación
R es un lenguaje y un ambiente para procesamiento estadístico y gráficos, entre otras funcionalidades. Provee
una amplia variedad de técnicas y es ampliamente extensible. Una de sus fortalezas es la facilidad con la que
gráficas de gran calidad pueden ser creadas, incluyendo símbolos matemáticos y fórmulas. R es un conjunto
integrado de herramientas de software para manipulación y almacenado de datos, cálculos con arreglos y
matrices, análisis de datos y facilidades gráficas para análisis de datos. Es un lenguaje de programación simple
y efectivo, con posibilidad de entrada y salidas de datos [w-16]. Para interactuar con R de una manera más
sencilla, pero aun trabajando con código, existe RStudio que es una IDE diseñada para el lenguaje de
programación R. Incluye una consola, editor de sintaxis y herramientas para gráficos, historia, debugging, entre
otras funciones. Una de las características de interés es la función de ajuste automático de funciones,
permitiendo entregar parámetros para los modelos ARIMA y SE, que pueden ser un punto de partida interesante
para el análisis predictivo [w-7].
Python es un lenguaje de programación interpretativo, interactivo y orientado al objeto. Incorpora módulos,
excepciones, tipificación dinámica, tipos de datos de alto nivel y clases. Python combina potencia con una
sintaxis clara; tiene interfaces para variadas llamadas de sistema y librerías, así como hacia varios sistemas con
‘ventanas’ y es extensible en C o C++. También puede ser usado como una extensión de lenguaje para
aplicaciones que necesitan una interfaz programable, Además, Python es portable; puede ser ejecutado en
sistemas Unix, Mac y Windows. Este lenguaje incluye una gran cantidad de librerías que abarcan áreas como
procesamiento de texto, protocolos de internet, ingeniería de software e interfaces de sistema operativo [w-8].
2.4 Métricas de Evaluación
A continuación, se presentan algunas de las métricas que permiten evaluar la precisión de una serie de datos
estimada, en relación a la serie original:
• Error absoluto: es la diferencia entre un valor medido o estimado y el valor considerado como cierto o
exacto [w-9].
• Error relativo: es el error absoluto dividido por el valor considerado como cierto o exacto [w-9].
• Error absoluto medio: es el promedio de los diferentes errores absolutos encontrados en una serie de
datos [16].
• Error relativo medio: es el promedio de los diferentes errores relativos encontrados en una serie de datos
[16].
• Correlación (de Pearson): es una prueba estadística para analizar la relación entre dos variables medidas
en un nivel por intervalos o de razón. Se calcula a partir de las puntuaciones obtenidas en una muestra de
dos variables. El valor va de –1 a +1, siendo los extremos correlaciones perfectas, y 0 sin correlación. Una
correlación mayor a 0.75 es considerable, mientras que superior a 0.9 es muy fuerte [2].
9Universidad Técnica Federico Santa María
Departamento de Informática
Magíster en Tecnologías de la Información
• Spearman Rho: es una prueba usada para medir la fuerza de asociación entre dos variables. Así como en
la correlación, +1 es un positivo perfecto y -1 es un negativo perfecto. En este caso, una correlación se
denomina fuerte cuando es superior a 0.6 [w-10].
• Kendall Tau: es una medida de la fortaleza y dirección de una asociación entre dos variables. Al igual
que las correlaciones anteriores, sus valores pueden ir de +1 a -1 [w-11].
• Mean Squared Error (MSE): El error cuadrático medio es una media del promedio de las desviaciones
de los valores predichos en relación a los valores reales de una muestra. Al ser cuadrático, suma todos los
errores presentes independiente del signo [16].
• Root Squared Mean Error (RMSE): Es la raíz cuadrada del MSE, lo que deja este error en las mismas
unidades que aquella de la muestra [16].
2.5 ANOVA
Otra manera de llevar a cabo una comparación entre distintas series de datos es mediante el “Análisis de
Varianza” (ANOVA, por sus siglas en inglés), que es una prueba estadística para analizar si dos o más grupos
difieren significativamente entre sí en cuanto a sus medias y varianzas. Plantea una hipótesis nula que propone
que los grupos no difieren de manera significativa, por lo que la hipótesis de la investigación propone que los
grupos sí difieren. El análisis de varianza produce un valor conocido como F o razón F. Si el valor de F es
significativo implica que los grupos difieren entre sí en sus promedios [2].
3 Estado del Arte
Una aplicación de MD en la vida real se encuentra en la industria de la medicina. En [4] se muestra su uso para
la administración efectiva de los recursos hospitalarios, clasificación de hospitales, mejora de la relación con el
cliente, control de las infecciones hospitalarias, mejores técnicas de tratamiento, mejor cuidado del paciente,
menor fraude en seguros, reconocimiento de pacientes de alto riesgo y planificación de pólizas de salud. El
estudio presenta un resumen de los distintos métodos utilizados en la industria, entre los que destacan los árboles
de decisión y las redes neuronales artificiales.
Otra área en la cual se emplean estas técnicas en la actualidad es en la educación, según lo analizado por [17]
en relación a los datos académicos. La “minería de datos académicos” es un área que está evolucionando y se
asocia de cerca con el análisis del aprendizaje, lo que permite descubrir cómo los estudiantes aprenden y
entienden y cómo los profesores entregan el contenido correcto en vista de los cambios actuales en los métodos
de enseñanza. Además, se presenta el concepto de “minería de datos educacional”, que se encarga de desarrollar
métodos para encontrar conocimiento a partir de los datos proveniente del ambiente educacional. En este caso
también se presenta un resumen de diferentes métodos utilizados en la industria, obteniendo mejores resultados
con los árboles de decisión y las redes neuronales artificiales.
En relación a las series de tiempo, el estudio hecho por [18] intenta aplicar estos modelos para pronosticar
secuencias de inscripción de patentes. En éste, las técnicas seleccionadas son suavizamiento exponencial y
ARIMA, junto a la herramienta RStudio. El estudio comienza con la aplicación de la detección automática de
parámetros entregada por la herramienta, aplicada a cada técnica en particular. Luego, para comparar las series,
utiliza mediciones de precisión de predicción, como la raíz del error cuadrático medio, el error absoluto medio
y el error absoluto medio porcentual. Los resultados muestran que, en este caso, ARIMA muestra resultados
algo mejores, pero no con una ventaja evidente.
Finalmente, un estudio publicado en el año 2019 [19] analiza el uso de modelos de machine-learning para
predecir ventas. En primer lugar, se explica que existen algunas limitantes al usar series de tiempo en predicción
de ventas, entre las cuales destacan: usualmente no se cuenta con datos históricos por un período suficiente para
captar la estacionalidad, pero sí se cuenta con los datos históricos para un producto similar y se puede esperar
que el nuevo se comporte de manera similar; los datos sobre las ventas pueden contar con muchos outliers o
10Universidad Técnica Federico Santa María
Departamento de Informática
Magíster en Tecnologías de la Información
datos faltantes, para lo cual hay que limpiar y extrapolar datos; es necesario tomar en cuenta factores exógenos
que tienen impacto en las ventas. En éste, se consideraron diferentes técnicas de modelado para encontrar
patrones de predicción en el tiempo, entre las que destacan random forest, redes neuronales y stacking (varios
niveles de distintos métodos combinados). Se concluye que el uso de la regresión para predicción de ventas
puede entregar un mejor resultado que un análisis común de series de tiempo. Uno de los principales supuestos
de estos modelos es que el patrón de comportamiento histórico de los datos se repetirá en el futuro.
4 Desarrollo del Trabajo
Como se detalló en el Marco Teórico, la metodología seleccionada para el presente estudio es CRISP-DM. Ésta
cuenta con seis pasos, los que se usarán para presentar las tareas desarrolladas en el trabajo hecho.
4.1 Comprensión del Negocio
La Industria Gastronómica [w-13]
En relación a la industria gastronómica, es posible afirmar que ésta es una de las que más ha crecido en las
últimas dos décadas. La oferta ha ido creciendo, pasando de los restaurantes más clásicos a alternativas más
exóticas, las cuales han proliferado en el último tiempo. Al año 2016, Chile se ubica en el sexto lugar del ranking
latinoamericano en cuanto al movimiento anual de esta industria.
Una de las características que sitúa a Chile bajo sus vecinos de la región en relación a la gastronomía, es el
gasto per cápita estimado, el cual se debe a un acotado presupuesto doméstico. No obstante, se han generado
alternativas a precios razonables, los cuales permiten a una gran parte de la población probar platos y sabores
extranjeros. Los chilenos tenemos cada vez más acceso a alternativas tales como la comida tailandesa, japonesa,
peruana o colombiana, solo por mencionar algunas de las ofertas más exitosas de los últimos tiempos. Cabe
destacar, en este sentido, que Chile ha sido considerado como uno de los tres países en el mundo en los que la
industria gastronómica y alimentaria representa más de un 10 por ciento del PIB2, siendo los otros dos Nueva
Zelanda y Bélgica. En resumen, la industria gastronómica de Chile está en vías a convertirse en una importante
potencia de la región, siguiendo los pasos de líderes en la materia como Perú.
La Industria Gastronómica y Heladera
Enfocándose en la industria heladera como tal, Chile ocupa el primer puesto del ranking latinoamericano de
consumo de helado per cápita por año, con unos impresionantes 8 kilos. Lleva una diferencia de 1 kilo con su
competidor más cercano, que en el caso latinoamericano está disputado entre Costa Rica y Argentina, con más
de 7 kilos en ambas naciones. En Chile el consumo está muy distribuido entre los diversos estratos sociales,
encontrando opciones para todos los bolsillos, lo que favorece (y mucho) el consumo masivo. De acuerdo a
diversas estadísticas, los chilenos gastan cerca de $35.000 al año, mientras que, en términos de ventas globales,
los helados generan un movimiento de 700 millones de dólares [w-14].
Pero es un mercado en constante evolución; como la mayoría de aquellos negocios que sobreviven en el mundo,
deben adaptarse a los modismos y nuevas tendencias que cobran fuerza entre los consumidores. Ahora es el
turno del “helado gourmet”, un movimiento que celebra los nuevos sabores que escapan a los convencionales
y que utilizan productos más refinados para la producción de helados artesanales. Algunos de estos nuevos
sabores en el mercado son la frambuesa artesanal, en la que lograron preservar algo de fruta fresca para darle
mejor sabor. Otra incorporación significativa, y muy requerida en el país, son la sandía, melón y vainilla de
Madagascar [w-14].
2
Producto Interno Bruto
11Universidad Técnica Federico Santa María
Departamento de Informática
Magíster en Tecnologías de la Información
Una de las razones que ha permitido que las compañías experimenten altas tasas de crecimiento, es que han
sabido combatir la estacionalidad del producto que comercializan. De esta forma, según cuentan desde
‘Palettas’, para la temporada de invierno se esfuerzan en "la producción y venta de todos los sabores altos en
vitamina C". En tanto, desde ‘Grido’ aseguran que para los meses de invierno se enfocan en la venta de postres
envasados y, además, incorporan otros canales de distribución, como el delivery, "donde facilitamos al cliente
la compra de postres helados sin que tengan que salir de su casa". En este mismo contexto, plantean que "el
consumo de helados en los chilenos ha ido cambiando, pues ya no es solo un producto estacional, sino que se
consume todo el año, sobre todo en los centros comerciales cerrados"[w-15].
La Heladería en ELH.
El negocio de la heladería surgió como una opción de nuevo negocio para ELH luego de analizar el mercado
gastronómico y heladero en particular y observar en éste un fuerte potencial de crecimiento. Desde su
incorporación, QH fue incrementando sus ventas, consolidándose como el producto más fuerte de la compañía
luego de algunos años. Esta condición se mantuvo constante, aumentando las ventas por varios años.
Con el problema que significó perder la representación, la compañía emprendió de inmediato la misión de
buscar un nuevo proveedor, ya que no podían perder el impulso existente ni las relaciones con los clientes. Por
esta razón, se incorpora el producto MT y de inmediato se empieza a promocionar entre los clientes, algunos
de los cuales recibieron el cambio sin problema, pero con algunas preocupaciones por parte de otros, quienes
no creen que el producto mantiene la calidad.
Se espera que en dos años, el producto MT pueda superar las ventas registradas en el mejor año de QH y que
se consolide como el producto más fuerte de la compañía.
4.2 Comprensión de los Datos
La información de las ventas está disponible desde el año 2003, varios años antes de la introducción del producto
QH, en noviembre del año 2009. Estos datos son las ventas en cantidad de unidades y cantidad de dinero neto.
Por razones de privacidad de los datos, solo se trabajará con las unidades vendidas.
Los datos provienen de cinco tablas de la base de datos de ventas de la compañía, siendo estas tablas las
siguientes: Productos, Ventas con Factura, Ventas con Boleta, Notas de Crédito y Notas de Débito. La
información útil dentro de la tabla Productos, la cual tiene más de 30 campos, son el código del producto y el
nombre del mismo. El código es necesario porque este es el dato que se usa en cada uno de los registros en las
restantes cuatro tablas; y el nombre es necesario porque aquí se indica la cantidad de kilos de producto que
significa la venta de una unidad de éste. Las cuatro tablas de ventas tienen una composición similar entre ellas,
siendo útil para el presente estudio tres de éstos: un campo para el código del producto, uno para la fecha de la
transacción y un último campo para la cantidad de unidades. En la tabla 4.1 se muestra un resumen con los
siguientes atributos de los datos originales, para cada tabla mencionada:
• Registros: número total de registros existentes.
• Cantidad mínima/máxima: valores mínimo y máximo de ‘cantidad de unidades’ encontrado en los
registros.
• Cantidad media: promedio de ‘cantidad de unidades’ por registro.
• Registros QH: número y porcentaje de registros correspondientes al producto QH, del total de
registros.
• Cantidad mínima/máxima QH: valores mínimo y máximo de ‘cantidad de unidades’ encontrado
entre los registros correspondientes al producto QH.
• Cantidad media QH: promedio de ‘cantidad de unidades’ por registro correspondiente al producto
QH.
12Universidad Técnica Federico Santa María
Departamento de Informática
Magíster en Tecnologías de la Información
Tabla 4.1: Resumen de los datos originales
Cantidad
Cantidad Cantidad Cantidad
Registros Registros QH mínima/máxima
mínima/máxima media media QH
QH
Ventas
con 64693 1 / 80000 462 10151 / 16 % 1 / 1524 3,84
Factura
Ventas
con 1605 1 / 3000 62 71 / 4,4 % 1/3 1,14
Boleta
Notas de
1608 0 / 20000 560 273 / 17 % 0 / 93 2,39
crédito
Notas de
0 - - - - -
débito
En la figura 4.1 se muestra un resumen de las
ventas promedio registradas en cada mes desde
el año 2003. En ella se puede observar que las
ventas muestran una cierta homogeneidad, con
las únicas excepciones de junio y noviembre,
meses que muestran ventas notoriamente más
altas y más bajas que el resto de los meses,
respectivamente.
Con las tablas y datos ya mencionados, es
posible ya tener todos los datos necesarios para
el estudio, pero éstos deben ser analizados,
estudiados y ajustados, ya que no es posible Figura 4.1: Ventas por mes. Fuente: elaboración propia.
utilizarlos de manera directa. Para esto se
procede a la siguiente etapa de CRISP-DM, la cual consiste en preparar los datos y dejarlos listos para el estudio.
4.3 Preparación de los Datos
En primer lugar, es necesario ajustar la tabla Productos, ya que tiene muchos campos que no sirven al estudio,
y hay que crear un nuevo campo ‘Cantidad’ donde se guarde la unidad de venta, en kilos, del producto, dato
que debe ser obtenido del campo ‘Nombre’. Este procedimiento se realiza de manera manual, ya que son solo
305 registros los que corresponden a los productos en estudio, y crear un programa que sea capaz de automatizar
esta tarea podría requerir más tiempo que el necesario al hacer esta acción manualmente. A modo de ejemplo,
para el producto ‘Pasta Chocolate Blanco 1.1Kg”, el campo ‘Cantidad’ asociado es ‘1.1’, que equivale a la
unidad de venta de este producto.
En segundo lugar, se debe eliminar de las cuatro tablas de ventas todos aquellos registros que no tengan relación
con el producto QH. Posteriormente, se crea una tabla auxiliar que agrupará las ventas por período mes-año
desde las cuatro anteriormente nombradas, permitiendo obtener una agrupación final de datos para la venta en
cada período mes-año. Para esto, se suman los valores de las tablas Ventas con Facturas, Ventas con Boleta y
Notas de Débito y se restan las Notas de Crédito. Finalmente, se agregan las ventas de los distintos productos
para cada período mes-año. Para estos procedimientos se realizó un algoritmo en VB.NET que se muestra en el
Anexo 1.
El resultado final en la tabla auxiliar, que se llama “VentasTotales”, representa las ventas netas por kilos de la
marca QH para cada período mes-año del estudio. Este período tiene datos desde noviembre del 2009 hasta
13Universidad Técnica Federico Santa María
Departamento de Informática
Magíster en Tecnologías de la Información
junio del 20193. La última compra del producto QH fue en septiembre del año 2018 y estos productos se
continúan vendiendo hasta acabar el stock o hasta que el producto alcance su fecha de vencimiento. En
consecuencia, el período de estudio será desde noviembre del 2009 hasta junio del 2019; es decir, 115 meses,
cada uno con la cantidad de kilogramos de producto QH vendido.
El siguiente paso consiste en estudiar los nuevos datos para llevar a cabo el entendimiento. En primer lugar, se
muestra en la figura 4.2 un histograma para tener una primera impresión de éstos. Se puede observar un cierto
sesgo hacia la izquierda, con una media bastante menor al mayor valor observado. Así mismo, se observan los
rangos en los cuales existe únicamente un dato, los que habrá que analizar en una siguiente etapa.
De los datos originales se pueden
encontrar algunas mediciones
estadísticas básicas. La media de la
muestra es de 647 Kg, con una
desviación estándar de 424 Kg. El
valor mínimo encontrado es 0, el
cual se repite en dos ocasiones. El
valor máximo encontrado es de
2.354, correspondiente al mes de
octubre del año 2013. En una
siguiente etapa se lleva a cabo el
análisis de estos datos que
corresponden a los extremos de la
muestra, ya que podrían Figura 4.2: Histograma. Fuente: elaboración propia.
corresponder a outliers. En el proceso anterior se encontraron dieciocho registros con errores, los que se
muestran en el Anexo 2. Es posible observar que, de los errores encontrados, el código del producto se repite
en la mayoría de ellos, resumiéndose en que los problemas se generan por dos códigos que no están en la tabla
de productos y otros dos que no tienen información de cantidad en esta tabla. Los códigos de producto con
problemas son: 2003 y 1008 sin registro en tabla, y 5244 y 2515 sin cantidad en tabla. Luego de revisar el
archivo de facturas y de entrevistar al personal encargado del producto, se pudo obtener la cantidad de kilos
que corresponden a los códigos 5244 (1 Kg.) y 2515 (3 Kg.), pero no fue posible encontrar información sobre
los otros productos, por lo que estos datos tendrán que ser desechados. Considerando que son ventas registradas
en el año 2009 y 2010, con solo 1 y 2 unidades vendidas de cada uno, se establece que la pérdida de estos datos
no será perjudicial para el estudio.
En este punto, ya es posible
hacer el primer gráfico
mostrando un correlativo
temporal de los datos de la
serie, el cual, como ha sido
mencionado anteriormente, es
un paso esencial al momento
de trabajar con series de
tiempo. La figura 4.3 muestra
el gráfico con los datos
históricos de ventas.
Figura 4.3: Datos históricos. Fuente: elaboración propia.
3 En julio 2019 comenzó el análisis y modelado de la presente Tesina.
14Universidad Técnica Federico Santa María
Departamento de Informática
Magíster en Tecnologías de la Información
En primer lugar, es posible
observar fácilmente que hay
unos datos que podrían ser
outliers, por lo que se procede
a estudiar más a fondo el dato
de ventas para los meses:
noviembre 2010, octubre
2013 y noviembre 2016. Este
estudio se realiza analizando
los documentos emitidos en
ese período, buscando las
causas de estos valores
extraños y consultando con
los vendedores asignados a
cada cliente involucrado. Para Figura 4.4: Datos históricos corregidos. Fuente: elaboración propia.
los períodos de noviembre
2010 y octubre 2013, se encontraron facturas únicas por valores excesivos. Se consultó con los vendedores
respectivos y se encontró que para ambos casos los casos fueron excepciones y no ventas recurrentes en el
tiempo. Por el contrario, el caso de noviembre 2016 es una suma de una gran cantidad de ventas pequeñas a
varios clientes frecuentes; por esta razón, este dato sí se acepta. En consecuencia, del período noviembre 2010
se restan el total de la suma de dos facturas emitidas el mismo día al mismo cliente, por un total de 1261 Kg.
Así mismo, del período octubre 2013 se resta una factura de un cliente que nunca más compró, por un total de
1.402 Kg. También cabe destacar que hacia fines del 2017 y durante los años 2018 y 2019 hay una baja
considerable en las ventas, registrándose ventas casi nulas en mayo y junio del 2019. Considerando que ya en
estos meses se vendía el nuevo producto, se procede a eliminar de la muestra estos últimos dos datos, para no
interferir en el estudio con valores exagerados a la baja. La figura 4.4 muestra el gráfico con los datos históricos
de ventas luego de las correcciones realizadas a los datos. Habiendo corregidos los datos, se muestra en el
Anexo 3 el registro final de éstos, los que serán utilizados en la siguiente fase.
4.3.1 Detección Automática de Outliers
RStudio incorpora una función que
permite detectar y ajustar en la muestra
los puntos que parecieran estar fuera
de lógica, los llamados outliers. Este
paso permite comprobar que la
detección realizada anteriormente por
intuición y estudio analítico de los
datos también cuente con apoyo
estadístico. La figura 4.5 muestra dos
series de tiempo, la original y la
modificada. En ésta se puede observar
que la herramienta detecta los mismos
puntos como outliers, lo que confirma Figura 4.5: Serie original y corregida. Fuente: RStudio con datos propios.
que el ajuste de estos datos tiene
lógica. En consecuencia, se procede a trabajar con los datos obtenidos luego de la limpieza de la sección
anterior.
15También puede leer

















































