FACULTAD DE ESTUDIOS ESTADÍSTICOS MÁSTER EN MINERÍA DE DATOS E INTELIGENCIA DE NEGOCIOS - E-Prints Complutense
←
→
Transcripción del contenido de la página
Si su navegador no muestra la página correctamente, lea el contenido de la página a continuación

FACULTAD DE ESTUDIOS ESTADÍSTICOS MÁSTER EN MINERÍA DE DATOS E INTELIGENCIA DE NEGOCIOS Curso 2020/2021 Trabajo de Fin de Máster TITULO: ANÁLISIS DE LAS INSPECCIONES EN LOS RESTAURANTES DE NUEVA YORK. ALUMNO: JUAN IGNACIO LÓPEZ CELESTER TUTOR: ANTONIO SARASA CABEZUELO Septiembre de 2021
ÍNDICE 1.- INTRODUCCIÓN 4 1.1- ANTECEDENTES, ESTADO ACTUAL Y JUSTIFICACIÓN DE LA PROPUESTA 4 1.2- MOTIVACIÓN 4 2.- OBJETIVOS 5 3.- ESTADO DEL ARTE 5 4.- METODOLOGÍA EMPLEADA 7 4.1- METODOLOGÍA SEMMA 7 4.2- ALGORITMOS DE MACHINE LEARNING 8 4.2.1- REGRESIÓN LOGÍSTICA 8 4.2.2- REDES NEURONALES 8 4.2.3- BAGGING Y RANDOM FOREST 9 4.2.4- GRADIENT BOOSTING Y EXTREME GRADIENT BOOSTING 10 4.2.5- SUPPORT VECTOR MACHINES 11 4.2.6- ENSAMBLADO 11 4.3- EVALUACIÓN DE MODELOS DE MACHINE LEARNING 12 5.- DESARROLLO DEL TRABAJO Y PRINCIPALES RESULTADOS 13 5.1.- PREPARACIÓN Y DEPURACIÓN DE LOS DATOS 13 5.1.1- FUENTE DE DATOS Y TRATAMIENTO PRELIMINAR 13 5.1.2- DEPURACIÓN DE LOS DATOS 15 5.1.3- SELECCIÓN DE VARIABLES 19 5.2- MODELIZACIÓN 21 5.2.1- REGRESIÓN LOGÍSTICA Y REDES NEURONALES 21 5.2.2- BAGGING 25 5.2.3- RANDOM FOREST 30 5.2.4- GRADIENT BOOSTING 35 5.2.5- EXTREME GRADIENT BOOSTING 41 5.2.6- SUPPORT VECTOR MACHINES 48 5.2.7- ENSAMBLADO 60 5.3- COMPARACIÓN Y EVALUACIÓN DE MODELOS 62 6.- CONCLUSIONES 64
RESUMEN Las inspecciones en los restaurantes de la ciudad de Nueva York son actualizadas periódicamente en el portal de la ciudad de Nueva York, para ofrecer transparencia a los ciudadanos. Estas inspecciones se rigen por un sistema de calificaciones implantado recientemente. En este trabajo de fin de máster se determinará si este sistema de calificaciones es eficaz y genera los resultados que se esperaban. El objetivo del estudio es predecir los parámetros que influyen en los resultados de las calificaciones de las inspecciones de los restaurantes de la ciudad de Nueva York. También, se especificará si el sistema de calificaciones es eficaz, se determinará el mejor modelo y se expondrá la variable que más influye en el modelo ganador. El estudio se basará en una muestra de 11.682 inspecciones en los restaurantes de la ciudad de Nueva York; Se pretenderá mediante la metodología SEMMA, realizar un proceso de depuración preciso. Se utilizará el lenguaje de programación SAS 9.4, el lenguaje de programación R y la aplicación SAS Enterprise Miner Workstation 14.1, para realizar el análisis de datos. ABSTRACT Inspections at New York City restaurants are regularly updated on the New York City portal, to provide transparency to citizens. These inspections are governed by a recently introduced ratings system. This end-of-master's work will determine whether this grading system is effective and produces the results that were expected. The goal of the study is to predict the parameters that influence the ratings results of inspections of New York City restaurants. It will also specify whether the rating system is effective, determine the best model and present the variable that most influences the winning model. The study will be based on a sample of 11,682 inspections at restaurants in New York City; The aim of the SEMMA methodology is to perform a precise debugging process. The SAS 9.4 programming language, the R programming language, and the SAS Enterprise Miner Workstation 14.1 application will be used for data analysis.

1.- INTRODUCCIÓN 1.1- ANTECEDENTES, ESTADO ACTUAL Y JUSTIFICACIÓN DE LA PROPUESTA Desde el año 2012, la legislación de la ciudad de Nueva York permite ofrecer conjuntos de datos de acceso público, para que puedan ser utilizadas por otros entes con una finalidad práctica y se mejore de esta forma la transparencia en la ciudad. Entre estos conjuntos de datos, se encuentran el de los resultados de las inspecciones de los restaurantes de la ciudad de Nueva York. (Nicosia, G. et al., 2020). En los últimos años, los negocios de comida del estado de Nueva York han sido inspeccionados en numerosas ocasiones; En el año 2017, por ejemplo, han sido 40.700 inspecciones totales para un total de 26.101 restaurantes sujetos a inspección. Los resultados de estas inspecciones fueron 22.185 restaurantes con nota A, 1.256 con nota B, 315 con nota C, 1.019 restaurantes cerraron por malas condiciones sanitarias y el resto de restaurantes quedan pendientes de calificación. (The New York Times, 2018). Las inspecciones de negocios en Nueva York recibirán tres calificaciones en el proceso de inspección: ➢ A; Será la mejor de las calificaciones y estarán exentas de multas desde el 19 de enero de 2011. (NYC, 2012). ➢ B; Esta calificación indicará que el restaurante cometerá infracciones y tendrá que pagar la correspondiente multa. ➢ C; Será la peor de las calificaciones e indicará que las infracciones cometidas serán un riesgo para la salud pública, por lo que estos restaurantes recibirán multas considerables o podrán ser objeto de cierre del negocio. Actualmente, el departamento de salud del estado de Nueva York publicará en su web una serie de recomendaciones, en diversos idiomas, para que todos los restaurantes tengan claro como obtendrán una A. (NYC, 2020). En el presente trabajo se pretende aplicar la minería de datos y la inteligencia de negocios a las inspecciones de los restuarantes, para examinar si el sistema de calificaciones implantado en el estado de Nueva York es eficaz y si ha producido resultados positivos desde su implantación. 1.2- MOTIVACIÓN Los brotes de enfermedades transmitidas por alimentos es una cuestión de salud pública que se repite año tras año y que se ha intentado paliar en la ciudad de Nueva York mediante la implantación de un sistema de calificaciones público. En este trabajo de fin de máster se pretende exponer el problema y ver si el sistema de calificaciones en los 10 años que va a cumplir en 2022 es eficaz o no ha generado los resultados que se esperaban de esta propuesta para acabar con el problema de los brotes de enfermedades transmitidas por alimentos en la ciudad de Nueva York. En el presente trabajo se pretende aplicar la minería de datos y la inteligencia de negocios a las inspecciones de los restaurantes, para hallar un modelo en el que se
permita predecir si un restaurante obtendrá una determinada calificación al momento de la inspección. 2.- OBJETIVOS El objetivo principal del estudio es predecir los parámetros que influyen en los resultados de las calificaciones de las inspecciones de los restaurantes de la ciudad de Nueva York. Este objetivo se puede desagregar en objetivos secundarios: ➢ Determinar si el sistema de calificaciones implantado en la ciudad de Nueva York es una herramienta eficaz de control de enfermedades transmitidas por alimentos. ➢ Realizar varios modelos, para proceder a su comparación y obtener el mejor. Analizar los resultados del mejor modelo y obtener conclusiones precisas. ➢ Proporcionar la variable que más influye en el mejor modelo. 3.- ESTADO DEL ARTE En este trabajo de fin de máster se han examinado los diversos trabajos, artículos e investigaciones que previamente se han hecho sobre el tema del que trata este trabajo de fin de máster. En mayo del año 2014, se publicó el artículo “Using Online Reviews by Restaurant Patrons to Identify Unreported Cases of Foodborne Illness”. Este artículo pretendía estudiar si las reseñas online podrían ayudar a identificar casos no informados de enfermedades transmitidas por alimentos. Las conclusiones a las que se llegaron, indican que se detectaron tres brotes no informados de enfermedades transmitidas por alimentos con la ayuda de 468 quejas online revisadas por epidemiólogos. (Harrison et al., 2014). En marzo del año 2015, se publicó el artículo “Impact of a Letter-Grade Program on Restaurant Sanitary Conditions and Diner Behavior in New York City”. Este artículo pretendía estudiar los resultados que se obtendrían mediante el programa de calificación mediante letras. Las conclusiones a las que se llegaron, indican que el programa ha sido eficaz y produjo un impacto positivo en la higiene, las prácticas de seguridad alimentaria y sensibilización pública. (Wong et al., 2015). En marzo del año 2016, se publicó el artículo “Supplementing Public Health Inspection via Social Media”. Este artículo pretendía crear un modelo predictivo a partir de las reseñas online publicadas en la página web Yelp.com. Las conclusiones a las que se llegaron, indican que los datos recogidos de las redes sociales complementan y mejoran la detección de restaurantes que presentan prácticas que pueden suponer un riesgo para la salud pública. (Schomberg et al., 2016).
En octubre del año 2016, se publicó el artículo “Understanding the Relationships Between Inspection Results and Risk of Foodborne Illness in Restaurants”. Este artículo pretendía estudiar la relación entre las calificaciones de las inspecciones sanitarias y el riesgo de brotes de enfermedades transmitidas por alimentos. Las conclusiones a las que se llegaron, indican que es poco probable que las inspecciones sanitarias detecten o predigan un brote de enfermedad transmitida por alimentos. (Lee et al., 2016). En noviembre del año 2018, se publicó el artículo “The Impact of Customer Loyalty and Restaurant Sanitation Grades on Revisit Intention and the Importance of Narrative Information: The Case of New York Restaurant Sanitation Grading System”. Este artículo pretendía estudiar el impacto del programa de calificaciones sobre la lealtad de los clientes y su predisposición a acudir al mismo restaurante tras la calificación proporcionada por los inspectores de sanidad del estado de Nueva York. Las conclusiones a las que se llegaron, indican que los clientes leales se muestran menos sensibles a las calificaciones obtenidas de los restaurantes independientemente de la puntuación que obtengan, mientras que, los clientes no leales se muestran considerablemente sensibles a las bajas calificaciones sanitarias de los restaurantes frente a los clientes leales. (Kim et al., 2018). En junio del año 2019, se aplicaron técnicas de machine learning, para identificar a aquellos restaurantes, de la ciudad de Chicago, que tenían una mayor propensión a obtener un resultado favorable o no en las inspecciones que realiza sanidad. Este trabajo de fin de máster denominado “Minería de datos para la mejora de la gestión de las inspecciones de sanidad en restaurantes de la ciudad de Chicago”, obtuvo que gradient boosting era el mejor modelo predictivo entre los diversos modelos comparados. (Ramírez, 2019). En agosto del año 2019, se publicó el artículo “Scores on doors: restaurant hygiene ratings and public health policy”. Este artículo pretendía estudiar el alcance de las inspecciones sanitarias respecto a las enfermedades transmitidas por alimentos. Las conclusiones a las que se llegaron, indican que un sistema de calificaciones eficaz y transparente podría reducir las enfermedades transmitidas por alimentos. (Fleetwood, 2019). En diciembre del año 2019, se publicó el artículo “A for Effort? Using the Crowd to Identify Moral Hazard in New York City Restaurant Hygiene Inspections”. Este artículo pretendía estudiar las reseñas en línea que publican los usuarios cuando se encuentran en un intervalo de tiempo en el que no está programada la inspección sanitaria de los restaurantes. Las conclusiones a las que se llegaron, indican que el programa de inspecciones de salud no es tan eficaz y que, por lo tanto, se requiere de un sistema de control continuo de la higiene de los restaurantes que garantice unas condiciones mínimas sanitarias. (Mejia et al., 2019). En mayo del año 2020, se publicó el artículo “Grade pending: the effect of the New York City restaurant sanitary grades inspection program on Salmonellosis”. Este artículo pretendía estudiar el impacto del programa de calificaciones sobre las enfermedades transmitidas por alimentos, y más concretamente sobre la salmonelosis. Las conclusiones a las que se llegaron, indican que el programa de calificaciones tuvo poco impacto sobre la sanidad pública del estado de Nueva York y no se redujo la incidencia de salmonelosis. (Krinsky et al., 2020).
En septiembre del año 2020, se presentó el trabajo de fin de máster “Una herramienta para mejorar la jerarquización de las inspecciones de sanidad en restaurantes de la ciudad Nueva York”. El trabajo de fin de máster en cuestión tuvo como principal objetivo, predecir si un restaurante de la ciudad de Nueva York pasaría una inspección de sanidad o no, a partir, de diversos algoritmos de machine learning. El mejor modelo de este trabajo de fin de máster, fue el de regresión logística que tenía como variables más relevantes la interacción entre la variable total inspecciones y tipo de inspección, el mes, las inspecciones con calificación A y la descripción de las inspecciones (Olivera, 2020). 4.- METODOLOGÍA EMPLEADA 4.1- METODOLOGÍA SEMMA Los objetivos se cumplirán mediante el uso del lenguaje de programación SAS 9.4. Se utilizará la metodología SEMMA, mediante la aplicación SAS Enterprise Miner Workstation 14.1, para depurar, tratar, modificar y analizar los datos. La metodología SEMMA que se utilizará, está compuesta por 5 fases; Sample, Explore, Modify, Model y Asses. (Azevedo et al., 2008). ➢ Fase de Muestreo (Sample): Se seleccionará una muestra de los 419.516 datos totales, para preparar los datos para la fase de exploración. ➢ Fase de Exploración (Explore): Se hará una exploración mediante gráficos para detectar los datos anómalos. ➢ Fase de Modificación (Modify): Se crearán, seleccionarán y transformarán las variables, a la vez que se tratarán los valores faltantes y atípicos para concluir con la depuración de los datos. ➢ Fase de Modelización (Model): Se generarán varios modelos para predecir los resultados que se pretenderán obtener. ➢ Fase de Evaluación (Asses): Se compararán los modelos obtenidos para seleccionar el mejor modelo. Se analizará el mejor modelo para obtener las conclusiones del estudio.
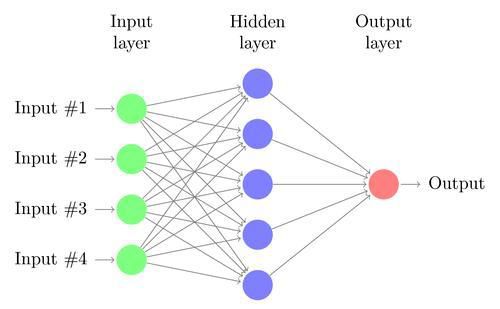
4.2- ALGORITMOS DE MACHINE LEARNING Machine learning o aprendizaje automático es una rama de la informática y de la inteligencia artificial, que pretende imitar y mejorar el aprendizaje humano mediante algoritmos y la utilización de datos. La rama estadística participa, permitiendo que los algoritmos se entrenen, para obtener información relevante en el campo de la minería de datos. (IBM, 2020). En machine learning existen 2 tipos principales de modelos; Por una parte, están los modelos de aprendizaje supervisado, y por otra, los modelos de aprendizaje no supervisado. (González, 2015). En el presente trabajo de fin de máster, se utilizarán algoritmos de aprendizaje supervisado. 4.2.1- REGRESIÓN LOGÍSTICA La regresión logística es un método donde la variable dicotómica dependiente es cualitativa o categórica. El modelo está compuesto por diversas variables cuantitativas o cualitativas independientes que permiten predecir la variable dependiente. (Midi et al., 2010). log(p/(1-p)) = b0+b1x1+b2x2+e Este tipo de algoritmos clásicos permiten predecir (presentan robustez), pero se ven limitados por la excesiva rigidez en los planteamientos y la complejidad que presentan los datos actualmente. (Portela, 2021). 4.2.2- REDES NEURONALES Las redes neuronales artificiales (RNA) pretenden imitar los sistemas nerviosos de los seres vivos. Las redes neuronales artificiales son sistemas de procesamiento que se componen principalmente de una gran cantidad de nodos interrelacionados que permiten optimizar y resolver cuestiones de aprendizaje. (O'Shea et al., 2015). Tal como se muestra en la figura 1, se observan 3 elementos (nodos input, nodo output y capa oculta). Los nodos input son las variables independientes del modelo; Los nodos output son las variables dependientes del modelo y la capa oculta está compuesta por los nodos ocultos, que son variables artificiales que no existen en los datos. (Portela, 2021).
Figura 1. Arquitectura de una red neuronal artificial. (Portela, 2021). En la red neuronal artificial que se observa en la figura 1, la función de combinación (Σ) permite que la capa input se una a la capa oculta, donde los pesos ( ) son los parámetros a valorar. La función de activación ( ) es aplicada a cada nodo oculto, donde la función tangente hiperbólica es la más empleada. Para finalizar, a la capa output se le aplican las funciones de activación y de combinación de la capa oculta. (Portela, 2021). 4.2.3- BAGGING Y RANDOM FOREST Bagging es un método que pretende minimizar las desventajas que posee un árbol de decisión. (Breiman, 1996). Este algoritmo se caracteriza por generar independencia de los datos y aportar una mayor estabilidad que un árbol de decisión. Se realiza el proceso siguiente en paralelo varias veces: ➢ “Repetir 1 y 2 m veces: 1) Sortear observaciones. 2) Realizar un árbol y obtener predicciones. ➢ Promediar las predicciones.” (Portela, 2021). Random Forest es un método que utiliza una considerable cantidad de árboles de decisión. Este algoritmo se caracteriza por utilizar dos parámetros (número de predictores y número de árboles). La principal ventaja de este algoritmo, es que se obtienen mejores resultados con las combinaciones de resultados de los árboles, frente a los resultados de los árboles de forma individualizada. (Cánovas-García et al., 2016). Según Qi (2012), tres son las características principales de random forest: ➢ Genera predicciones concisas en una gran variedad de aplicaciones. ➢ Permite cuantificar la importancia de cada característica con el entrenamiento de modelos. ➢ La proximidad por pares entre muestras, puede ser medida en el modelo entrenado.
Bagging y Random Forest son dos algoritmos que funcionan de una forma similar, con la única diferencia de que en Random Forest existe la incorporación de la aleatoriedad. “Los principales parámetros de estos dos algoritmos son: ➢ Mtry = Número de variables a sortear en cada nodo. A mayor mtry, menor sesgo y a menor mtry, se hace frente al sobreajuste. ➢ Nodesize = Tamaño mínimo de los nodos finales. Refleja la complejidad del árbol, si el número es bajo, se reduce el sesgo y si se aumenta el número, se produce una bajada de la varianza. ➢ Ntree = El número de iteraciones (árboles). ➢ Sampsize = El tamaño de cada muestra. A mayor tamaño, se reduce el sesgo y si se reduce el tamaño, se produce una bajada de la varianza. ➢ Replace = True (reemplazamiento) o False (sin reemplazamiento).” (Portela, 2021). 4.2.4- GRADIENT BOOSTING Y EXTREME GRADIENT BOOSTING Gradient Boosting es un método que intenta minimizar los residuos en la dirección de decremento mediante la repetición de la construcción de árboles de decisión transformando levemente las predicciones preliminares. (Natekin et al., 2013). “Los principales parámetros de este algoritmo son: ➢ V = Parámetro de regularización o shrinkage. ➢ Ntree = El número de iteraciones (árboles). ➢ Nodesize = Tamaño mínimo de los nodos finales. Refleja la complejidad del árbol, si el número es bajo, se reduce el sesgo y si se aumenta el número, se produce una bajada de la varianza. ➢ Sampsize = El tamaño de cada muestra. A mayor tamaño, se reduce el sesgo y si se reduce el tamaño, se produce una bajada de la varianza.” (Portela, 2021). Extreme Gradient Boosting es una modificación del método Gradient Boosting. Este paquete se utiliza con frecuencia en machine learning, debido a su velocidad de cálculo y la capacidad de interpretación de los resultados. (Sudakov et al., 2019).
4.2.5- SUPPORT VECTOR MACHINES Support Vector Machines es un algoritmo en el que se pretende utilizar un hiperplano de separación que permita resolver el problema de separación lineal de clases. El problema planteado presenta tres ideas principales: (Portela, 2021). 1. Maximal Margin, el planteamiento tiene como premisa que las clases están perfectamente separadas y se necesita encontrar el hiperplano que permite dejar el máximo margen. (Vapnik et al., 1995). 2. Soft Margin, el planteamiento tiene como premisa que las clases no están perfectamente separadas y se necesita encontrar el hiperplano que permite dejar el máximo margen aceptando que existen observaciones erróneamente separadas. (Fletcher, 2009). 3. Kernel, el planteamiento tiene como premisa que existen casos en los que no existe separación y se necesita generar nuevas dimensiones que permitan encontrar separaciones lineales. (Steinwart, 2001). 4.2.6- ENSAMBLADO En los métodos de ensamblado se pretende que a partir de la combinación de modelos se construyan predicciones. Los principales planteamientos de este algoritmo son: 1. El promedio de predicciones de diferentes algoritmos. 2. Uso de la predicción de un algoritmo como variable input de otro algoritmo. Las principales ventajas del ensamblado son: ➢ La eficacia que proporciona, ya que hay técnicas como Gradient Boosting o Random Forest que son técnicas de ensamblado. ➢ Al reducir la varianza es difícil que empeore modelos con sesgo similar. Las principales desventajas del ensamblado son: ➢ La interpretación es inexistente. ➢ Mayor complejidad y posibilidad de combinación. (Portela, 2021).
4.3- EVALUACIÓN DE MODELOS DE MACHINE LEARNING Se realizarán varios modelos para cada algoritmo explicado en el apartado 4.2 y seleccionará el mejor modelo. La forma de comparar estos será mediante: ➢ Área bajo la curva (AUC). Se pretenden comparar los modelos mediante esta métrica por la eficiencia que proporciona y la capacidad de clasificación que posee. ➢ Tasa de fallos. Se puede definir como el número de predicciones erróneas en porcentaje. A mayor tasa de fallos, peor resultado proporcionará el modelo en cuestión. + = + + + Una vez se ha obtenido el modelo ganador de cada algoritmo, se utilizará la matriz de confusión, tal y como se muestra en la figura 2, para generar diversas técnicas a estudiar. Figura 2. Matriz de confusión. (Calviño, 2020). Valores reales VN FP Valores de predicción FN VP = + = + = + = +
5.- DESARROLLO DEL TRABAJO Y PRINCIPALES RESULTADOS 5.1.- PREPARACIÓN Y DEPURACIÓN DE LOS DATOS 5.1.1- FUENTE DE DATOS Y TRATAMIENTO PRELIMINAR Los datos se encuentran en el portal de datos abiertos de la ciudad de Nueva York (NYC Open Data) (https://data.cityofnewyork.us/Health/DOHMH-New-York-City-Restaurant- Inspection-Results/43nn-pn8j) en el que se pueden obtener archivos de distintos ámbitos de la sociedad para realizar análisis de los mismos. La web open data de la ciudad de Nueva York, se caracteriza por actualizar los conjuntos de datos diariamente, como se puede apreciar en el data set de las inspecciones de los restaurantes de la ciudad de Nueva York. Los datos que ofrece esta web se han complementado con los datos que ofrece el portal del censo de la ciudad de Nueva York (https://www.census.gov/quickfacts/fact/table/queenscountynewyork,kingscountyne wyork,bronxcountynewyork,newyorkcountynewyork,richmondcountynewyork,newyor kcitynewyork/INC110219) (U.S. Census, 2021) que contiene información sobre los 5 distritos de Nueva York y permitirán crear variables en el apartado del tratamiento preliminar. El conjunto de datos de la web open data de la ciudad de Nueva York, contiene 26 variables y 419.516 observaciones. (NYC OpenData, 2021). Una vez se ha explicado el origen de los datos, se procederá a explicar en la figura 3, las variables originales del conjunto de datos y las variables que se crearán para complementar al conjunto de datos original. Figura 3. Variables originales y creadas. Variable Original/Creada Modificación Valores CAMIS Original Eliminada DBA Original Eliminada BORO Original Eliminada BUILDING Original Eliminada STREET Original Eliminada ZIPCODE Original Eliminada PHONE Original Eliminada CUISINE 0 Resto de tipos de comida Original Transformada DESCRIPTION 1 Tipo de comida norteamericana INSPECTION Original Eliminada DATE ACTION Original Eliminada VIOLATION Original Eliminada CODE
VIOLATION Original Eliminada DESCRIPTION 0 G CRITICAL FLAG Original Transformada 1 C SCORE Original Eliminada 0 A GRADE Original Transformada 1 B C GRADE DATE Original Eliminada RECORD DATE Original Eliminada INSPECTION 0 Cycle Inspection / Re-inspection Original Transformada TYPE 1 Cycle Inspection / Initial Inspection Latitude Original Original Longitude Original Original Community Original Eliminada Board Council District Original Eliminada Census Tract Original Eliminada BIN Original Eliminada BBL Original Eliminada NTA Original Eliminada 0 Norte Este Cardinalidad Creada Transformada 1 Sur Oeste Renta per Creada Original cápita 0 01 – 03 1 04 – 06 Mes Creada Transformada 2 07 – 09 3 10 – 12 0 Resto de razas/etnias Raza/Etnia Creada Transformada 1 Raza blanca Se puede observar como las variables transformadas se modificaron para que se convirtiesen en dummies y se hizo un trabajo previo de eliminación de variables que no iban a ser útiles para la predicción en Excel, antes de comenzar la fase de depuración en SAS Enterprise Miner Workstation 14.1.
5.1.2- DEPURACIÓN DE LOS DATOS En el proceso de depuración, se observa el conjunto de datos y se selecciona la variable objetivo (Grade), se procede a importar los datos en SAS Enterprise Miner Workstation 14.1. Figura 4. Variables dependientes y variable objetivo. En la figura 4 se observa el rol y la modalidad de las 10 variables. En la figura 5 que trata sobre la fase de detección de errores, no se encontró ningún error en las variables de intervalo y de clase, ya que se realizó este trabajo en Excel en el apartado de tratamiento preliminar de los datos. Figura 5. Detección de errores. En la detección y gestión de datos atípicos, se observa en la figura 6, que las variables latitude y longitude son asimétricas porque sus coeficientes de asimetría son superiores a 1 o inferiores a -1; Las medianas son distintas de 0, por lo que se les asignará el método de límite desviación absoluta. Sin embargo, la variable renta per cápita si es simétrica porque su coeficiente de asimetría se encuentra entre -1 y 1, por lo que el método de límite es desviación estándar.
Figura 6. Detección y gestión de datos atípicos. En la figura 7 que trata sobre el nodo de reemplazo, se observa que las variables a modificar por el método de límite son las variables input; Las variables input latitude y longitude se les asigna el método de límite desviación absoluta, mientras que, se asignará el método de desviación estándar para la variable renta per cápita. Figura 7. Asignación método de límite en la detección y gestión de datos atípicos. Para finalizar el apartado de detección y gestión de datos atípicos, se verifica en la figura 8, si en este conjunto de datos se debería realizar alguna modificación. En este caso, se detecta que las variables latitude y longitude si superan el 5% del total de observaciones (0,70*8176=5.723,2*0,05=286,16), por lo que se tendrá que volver al nodo reemplazo y poner en el método de límite ninguno tal y como se observa en la figura 9. Figura 8. Verificación de variables la detección y gestión de datos atípicos.
Figura 9. Verificación de variables en la detección y gestión de datos atípicos. En el apartado de tratamiento de datos faltantes, se utilizará un nodo de código SAS. Se ha utilizado el código que aparece en la Figura 10, para generar la variable numMissing. La variable numMissing funcionará como variable input y se verá si a alguna fila le faltan más del 50% de los datos. (Calviño, 2020). Figura 10. Código SAS tratamiento datos faltantes.
Figura 11. Verificación tratamiento datos faltantes. Se observa en la figura 11, que el máximo de la variable numMissing es 0, por lo que se puede asegurar que no supera el 50% de las variables totales. No hay datos ausentes ni en las variables de clase ni en las variables de intervalo, por lo que no se tienen que realizar más modificaciones. Por último, para concluir el proceso de depuración, se procederá a realizar la transformación de variables de clase. En esta fase se generarán dos variables aleatorias a partir de un nodo de código SAS, tal y como aparece en el código de la figura 12. (Calviño, 2020). Figura 12. Generación de variables aleatorias. Tras utilizar el nodo de código SAS, se utilizará un nodo de explorador de estadísticos para observar los diferentes gráficos con las variables aleatorias. En la preselección de
variables que ha realizado SAS Enterprise Miner Workstation 14.1, se rechazarán aquellas variables que tengan un valor igual o por debajo de las variables aleatorias. Figura 13. V de Cramer. En la figura 13, se puede observar que las variables con escaso poder predictivo son latitude, longitude, renta per cápita, raza/etnia y cardinalidad. Las variables latitude, longitude, renta per cápita, raza/etnia y cardinalidad serán rechazadas por SAS Enterprise Miner Workstation 14.1 en la preselección de variables, ya que se encuentran por debajo de las dos variables aleatorias. 5.1.3- SELECCIÓN DE VARIABLES Para realizar la selección de variables en SAS, se utilizará el código de “todas macros logistica v 6.0” (Portela, 2021) y se realizará la selección de variables. En los resultados se obtiene que hay un conjunto de variables de 3 variables, que coinciden con el que se proponía en la preselección de Miner, hasta un conjunto de variables de 7 variables. En SAS se obtiene que mediante el método de selección stepwise no se obtiene ninguna variable, por el método de selección de backward se obtienen las variables Cuisine_Description y Critical_Flag y, por último, se obtienen mediante el método de selección forward, las variables Cuisine_Description, Critical_Flag e Inspection_Type. Por otra parte, se utilizará el paquete logistic y la macro ramdomselect, para obtener varios modelos posibles. En la figura 14, se puede observar que se obtienen 4 modelos con los resultados que más se repiten para compararlos: Figura 14. Posibles modelos a comparar en la selección de variables. Modelo Método de selección Variables 1 Forward, preselección Miner y paquete Logistic Cuisine_Description, Critical_Flag e Inspection_Type 2 Backward Cuisine_Description y Critical_Flag 3 Paquete Logistic Raza_Etnia, Cuisine_Description, Critical_Flag, Inspection_Type y REP_Renta_per_c_pita 4 Paquete Logistic Cardinalidad, Cuisine_Description, Critical_Flag e Inspection_Type
Se comparan los modelos expuestos en la figura 14 y se obtiene que de los 4 hay dos que son los mejores (modelo 1 y modelo 3), tal y como se puede observar en la figura 15. Figura 15. Potenciales conjuntos de variables. Los resultados que se obtienen, indican que los mejores conjuntos de variables son el de 3 variables (Cuisine_Description Critical_Flag Inspection_Type) y el de 5 variables (Raza_Etnia Cuisine_Description Critical_Flag Inspection_Type REP_Renta_per_c_pita) tras haberlos comparado, por lo que se seleccionará el set de variables compuesto por las variables Cuisine_Description Critical_Flag Inspection_Type que se indicaba en la preselección de Miner, el método de selección Forward y el paquete Logistic.
5.2- MODELIZACIÓN 5.2.1- REGRESIÓN LOGÍSTICA Y REDES NEURONALES En las redes neuronales se trabajará con el software R para generar los mejores modelos. En primer lugar, se crea un vector de variables continuas y otro vector de variables categóricas. Se obtiene el archivo GRADEbis que tiene las variables continúas estandarizadas y las variables categóricas en dummies. Se convierten los datos “0” y “1” de la variable objetivo Grade en “No” y “Yes”. En segundo lugar, lo que se hará será obtener el número de nodos que permita obtener el mejor modelo. La fórmula que se utilizará es h(k+1) + h+1 y un mínimo de 30 observaciones por parámetro, por lo que se obtiene que como máximo se podrán poner 54 nodos, todo esto teniendo en cuenta las 3 variables input que tiene el mejor set de variables. Por último, se establece un grid en avnnet, porque es más sólido que nnet, con número de nodos (3,6,9,12,15,20,25,30,35,40,45,50) y learning rate de (0.01,0.02, 0.5, 0.1,0.001). Figura 16. Resultados grid avnnet. Se puede observar en la figura 16, que se obtiene una tasa de aciertos por encima de 0.80 en el grid de avnnet. Se observa también, que existe un patrón respecto al learning rate 0.001 en el que se obtienen mejores resultados que para valores altos de learning rate y que el número de nodos óptimo es cercano a los 20. Para comprobar esto último, se decide realizar un nuevo grid con learning rate de 0.001 y 0.0005, con número de nodos de 10, 15, 20, 25, 30, 35 y 40.
Figura 17. Resultados nuevo grid avnnet. En la figura 17 se puede observar, que se obtiene que los mejores modelos son los de tamaño 10 con un learning rate del 0,0005 y 40 con un learning rate de 0,0005. Tras haber hecho varias pruebas con las semillas 12318 y 12400, se procede a comparar los distintos modelos obtenidos mediante validación cruzada repetida, tal y como se observa en la figura 18. Figura 18. Modelos a comparar de regresión logística y redes neuronales. Modelo Descripción Tamaño Learning rate Logística sin selección de variables Regresión logística Logística con selección de variables Regresión logística Avnnet1 Red neuronal sin selección de variables 20 0.001 Avnnet2 Red neuronal sin selección de variables 40 0.0005 Avnnet3 Red neuronal sin selección de variables 10 0.0005 Avnnet4 Red neuronal sin selección de variables 35 0.001
Figura 19. Box plot tasa de fallos regresión logística y avnnet. En la figura 19, se observa que los resultados que se obtienen, permiten afirmar que redes neuronales como avnnet2 han mejorado la regresión logística sin selección de variables, aunque, cabe resaltar que el mejor modelo es el de regresión logística con selección de variables, por lo que habría que quedarse con este último en términos de tasa de fallos. A destacar de este gráfico, todos los modelos presentan outliers o valores atípicos excepto el de regresión logística con selección de variables.
Figura 20. Box plot AUC regresión logística y avnnet. En la figura 20 se observa, que en términos de AUC la regresión logística con y sin selección de variables ofrecen los mejores resultados, por lo que en este caso habría que quedarse con la regresión logística con selección de variables. A destacar de este gráfico, el modelo de regresión logística sin selección de variables presenta una mejor mediana que el modelo de regresión logística con selección de variables.
El mejor modelo es el de regresión logística con selección de variables, ya que ofrece la menor tasa de fallos y el segundo mejor resultado en términos de AUC (mejor equilibrio entre tasa de fallos/AUC). 5.2.2- BAGGING Se selecciona el set de 10 variables con dummies obtenido del nodo metadatos de Miner y se comienzan a realizar pruebas. Se realiza la personalización con las semillas que se han utilizado a lo largo del trabajo (12318 y 12400) y se fijan los parámetros para mtry (mtry=c(3,4,5,6,7,8,9)). Figura 21. Resultado personalización bagging. Se obtiene como resultado que el mejor accuracy se encuentra en 8 parámetros, tal y como se observa en la figura 21. Tras esto, se procede a estudiar cuando se estabiliza el error como se puede observar en la figura 22. Figura 22. Estudio estabilización del error. En la figura 22, se aprecia que sobre los 800-1000 árboles el error se estabiliza. Por otra parte, se aprecian unas mínimas fluctuaciones, a partir, de los 1000 árboles.
En la figura 23, se procede a realizar la personalización en el tamaño muestral y en el tamaño de hoja. En primer lugar, se procede a modificar el sampsize para encontrar el mejor entre 1000,2000, 4000 y 5000. Figura 23. Estudio hiperparámetro sampsize. 1000 2000 4000 5000 Se comparan los 4 gráficos y se concluye que el sampsize óptimo es el de 4000 porque genera decremento del error y lo estabiliza, tal y como se observa en la figura 23. Por último, en la figura 24 se realiza un estudio del número de nodos o nodesize, para ello se hará pruebas con 5, 10 15, 20 nodos. Figura 24. Estudio hiperparámetro nodesize.
5 10 15 20 En la figura 24, se obtiene como resultado que el tamaño máximo de nodos finales es 10. Por último, en la figura 25 se vuelve a utilizar el grid con los mejores parámetros que se han obtenido en número de árboles, tamaño muestral y el tamaño máximo de nodos finales. Figura 25. Grid mejores modelos bagging. Los resultados obtenidos indican que hay dos modelos que sobresalen que son el de 8 y el de 9 variables, por lo que se procederá a realizar una comparación con los 5 mejores modelos que se han obtenido en el grid, tal y como se observa en la figura 26. Figura 26. Modelos a comparar en bagging. Modelo Mtry Ntree Nodesize Sampsize Bagging1 5 1000 10 4000 Bagging2 6 1000 10 4000 Bagging3 7 1000 10 4000 Bagging4 8 1000 10 4000 Bagging5 9 1000 10 4000
Figura 27. Box plot tasa de fallos bagging. Figura 28. Box plot AUC bagging. En las figuras 27 y 28, se observa que a medida que aumenta el número de variables se obtiene una mejora en AUC, pero no en la tasa de fallos. Se decide seleccionar bagging1
(menor varianza y no tiene outliers como el modelo de bagging 3 en términos de tasa de fallos) porque es el modelo más equilibrado respecto a la tasa de fallos y AUC. Se hace una comparación con los modelos de regresión logística y se obtienen los siguientes resultados. Figura 29. Box plot tasa de fallos de bagging y regresión logística. Figura 30. Box plot AUC de bagging y regresión logística.
En las figuras 29 y 30, se observa como todos los modelos de bagging mejoran a los dos modelos de regresión logística (se produce una mejora respecto a las medianas que ofrecen los modelos de regresión logística, pero los modelos de regresión logística ofrecen mejores resultados en términos de varianza). 5.2.3- RANDOM FOREST Se selecciona el set de 10 variables con dummies obtenido del nodo metadatos de Miner y se comienzan a realizar pruebas. En la figura 31, se observa cómo se realiza la personalización con las semillas que se han utilizado a lo largo del trabajo (12318 y 12400) y se fijan los parámetros para mtry (mtry=c(3,4,5,6,7,8,9)). Figura 31. Resultado personalización Random Forest. En la figura 31, se obtiene que los mejores modelos son el de 6 y el de 9 variables, por lo que ahora lo que se hará será escoger las 6 variables por importancia que me indica R del set de variables que proporcionó Miner para comparar resultados, tal y como muestra la figura 32. Figura 32. Resultado personalización mejores mtry Random Forest. En la figura 32, se observa que el mejor accuracy se obtiene en el modelo de 3 variables. Tras esto, se procede a estudiar cuando se estabiliza el error, tal y como se observa en la figura 33.
Figura 33. Estudio estabilización del error. En la figura 33, se aprecia que sobre los 100 árboles el error se estabiliza. En la figura 34, se procede a realizar la personalización en el tamaño muestral y en el tamaño de hoja. En primer lugar, se procede a modificar el sampsize para encontrar el mejor entre 25,50, 100 y 1000. Figura 34. Estudio hiperparámetro sampsize. 25 50
100 1000 En la figura 34, se comparan los 4 gráficos y se concluye que el sampsize óptimo es el de 50 porque genera decremento del error y lo estabiliza. Por último en la figura 35, se realiza un estudio del número de nodos o nodesize, para ello se harán pruebas con 5, 10, 15 y 20 nodos. Figura 35. Estudio hiperparámetro nodesize. 5 10 15 20 En la figura 35, se obtiene como resultado que el tamaño máximo de nodos finales es 20. Por último, en la figura 36 se vuelve a utilizar el grid con los mejores parámetros que se han obtenido en número de árboles, tamaño muestral y el tamaño máximo de nodos finales.
Figura 36. Resultado grid con los mejores hiperparámetros. Los resultados obtenidos, en la figura 36, indican que el modelo de 6 variables es el mejor, por lo que se procede, en la figura 37, a comparar los modelos de 3,4 y 6 variables con los modelos de bagging y de regresión logística. Figura 37. Mejores modelos Random Forest. Modelo Mtry Ntree Nodesize Sampsize RF1 6 100 10 50 RF2 3 100 10 50 RF3 4 100 10 50 Figura 38. Box plot tasa de fallos Random Forest, bagging y regresión logística.
Figura 39. Box plot tasa de fallos Random Forest, bagging y regresión logística. Figura 40. Box plot AUC Random Forest, bagging y regresión logística.
Figura 41. Box plot AUC Random Forest, bagging y regresión logística. En las figuras 38, 39, 40 y 41, se observa nuevamente como todos los modelos de bagging proporcionan mejores resultados que el mejor modelo de ramdom forest, especialmente en términos de AUC, mientras que en términos de tasa de fallos se obtienen resultados similares. 5.2.4- GRADIENT BOOSTING Se selecciona el set de 10 variables con dummies obtenido del nodo metadatos de Miner y se comienzan a realizar pruebas. En la figura 42, se realizan la personalización con las semillas que se han utilizado a lo largo del trabajo (12318 y 12400) y se fijan los parámetros para shrinkage (shrinkage=c(0.1,0.05,0.03,0.01,0.001,0.005,0.003)), número de observaciones en las hojas finales (n.minobsinnode=c(5,10,15,20)), número de iteraciones o de árboles (n.trees=c(100,300,500,1000,5000)) y la profundidad de iteración (interaction.depth=c(2)).
Figura 42. Resultado personalización gradient boosting.
Figura 43. Resultado personalización gradient boosting. En la figura 43, se observa en el gráfico que aplicar un número de iteraciones de 5000 proporciona mejores resultados que un número de iteraciones inferior, excepto, en n.minobsinnode=20. También, se aprecia que a mayor shrinkage se obtienen mejores resultados, por lo que es preferible utilizar en el parámetro shrinkage el valor 0.1. Por último, en el número de observaciones en las hojas finales se observa que se alcanza un máximo en n.minobsinnode=10. Para completar el análisis, se procede a estudiar el número de iteraciones (n.trees=c(50,100,300,500,800,1000,1200,2000,3000,4000,5000,7000,10000)), manteniendo el resto de parámetros inalterados, tal y como se observa en la figura 44. (shrinkage=0.1, n.minobsinnode=10 y interaction.depth=c(2)).
Figura 44. Early stoping en gradient boosting. En la figura 44, se observa que el número de iteraciones óptimo, tras las pruebas realizadas, es de 5000 árboles, por lo que se procede, en la figura 45, a comparar los 4 modelos más interesantes de este apartado con los resultados de los anteriores apartados. Figura 45. Mejores modelos gradient boosting. Modelo Shrinkage N.minobsinnode N.trees Interaction.depth gbm1 0.1 10 5000 2 gbm2 0.1 15 5000 2 gbm3 0.1 5 5000 2 gbm4 0.05 5 5000 2 Figura 46. Box plot tasa de fallos Gradient boosting respecto a anteriores modelos.
Figura 47. Box plot tasa de fallos Gradient boosting respecto a anteriores modelos. En las figuras 46 y 47, se observa que, entre los 4 modelos, la menor tasa de fallos la obtiene gbm3, aunque tiene un outlier. Si se compara el modelo de gradient boosting 3 con los modelos de los anteriores apartados, se observa que proporciona unos resultados mejores, ya que se obtiene en este modelo una menor tasa de fallos.
Figura 48. Box plot AUC Gradient boosting respecto a anteriores modelos. Figura 49. Box plot AUC Gradient boosting respecto a anteriores modelos. En las figuras 48 y 49, se observa que, entre los 4 modelos el que obtiene un mayor AUC es gbm3. Si se compara el modelo de gradient boosting 3 con los modelos de los anteriores apartados, se observa que proporciona unos resultados mejores, ya que se obtiene en este modelo un mayor AUC.
El modelo gbm3 mejora a todos los modelos, tanto en términos de tasa de fallos, como en términos de AUC. 5.2.5- EXTREME GRADIENT BOOSTING Se selecciona el set de 10 variables con dummies obtenido del nodo metadatos de Miner y se comienzan a realizar pruebas. En la figura 50, se realiza la personalización con las semillas que se han utilizado a lo largo del trabajo (12318 y 12400) y se fijan los parámetros para eta (eta=c(0.1,0.05,0.03,0.01,0.001)), número de observaciones en las hojas finales (min_child_weight=c(5,10,15,20)), número de iteraciones o de árboles (nrounds=c(100,500,1000,5000)) y la profundidad de iteración (max_depth=6). Figura 50. Resultado personalización extreme gradient boosting.
Figura 51. Resultado personalización extreme gradient boosting.
En la figura 51, se observa en el gráfico que aplicar un número de iteraciones de 5000 proporciona mejores resultados que un número de iteraciones inferior. También, se aprecia que, a mayor eta, se obtienen mejores resultados, por lo que es preferible utilizar en el parámetro eta el valor 0.1. Por último, en el número de observaciones en las hojas finales se observa que se alcanza un máximo en min_child_weight =5. Para completar el análisis, en la figura 52, se procede a estudiar el número de iteraciones (nrounds =c(50,100,300,500,800,1000,1200,2000,3000,4000,5000,7000,10000)), manteniendo el resto de parámetros inalterados. (eta=0.1, min_child_weight =5 y max_depth=6). Se probarán varias semillas, para ver si los resultados son precisos. Figura 52. Resultado estudio número de iteraciones. Semilla 12400
Semilla 12300 Semilla 12500 En los resultados obtenidos de la figura 52, se observa que cambiando la semilla no se producen cambios, por lo que el número de iteraciones será 5000. En la figura 53, se realizará un estudio del sorteo de variables (colsample_bytree=c(0.25,0.5,0.75,1)), manteniendo el resto de parámetros inalterados.
Figura 53. Resultado estudio sorteo de variables. Se obtiene como resultado, que el mejor sorteo de variables u observaciones lo realiza con el valor 1. Por último, en la figura 54 se realizará un análisis del parámetro gamma (c(0,0.25,0.50,0.75,1)). Figura 54. Resultado estudio parámetro gamma.
Se observa que el mejor resultado se obtiene con gamma=0, por lo que se procede, en la figura 55, a comparar los 4 modelos más interesantes de este apartado con los resultados de los anteriores apartados. Figura 55. Mejores modelos extreme gradient boosting. Modelo Eta Min_child_weight Nrounds xgbm1 0.1 5 5000 xgbm2 0.1 10 5000 xgbm3 0.1 15 5000 xgbm4 0.05 20 5000 Figura 56. Box plot tasa de fallos extreme gradient boosting y anteriores modelos.
Figura 57. Box plot tasa de fallos extreme gradient boosting y anteriores modelos. En las figuras 56 y 57, se observa que, entre los 4 modelos, la menor tasa de fallos la obtiene xgbm1. Si se compara el modelo de extreme gradient boosting 1 con los modelos de los anteriores apartados, se observa que proporciona unos resultados mejores, ya que se obtiene en este modelo una menor tasa de fallos. Figura 58. Box plot AUC extreme gradient boosting y anteriores modelos.
Figura 59. Box plot AUC extreme gradient boosting y anteriores modelos. En las figuras 58 y 59, se observa que hay 3 modelos que tienen un AUC similar, pero se seleccionará xgbm1 porque proporciona mínimas mejorías en términos de AUC entre los 3 modelos. Si se compara el modelo de extreme gradient boosting 1 con los modelos de los anteriores apartados, se observa que proporciona unos resultados mejores y similares al modelo gbm3. El modelo xgbm1 mejora a todos los modelos en términos de tasa de fallos, pero en términos de AUC proporciona resultados similares al modelo gbm3. 5.2.6- SUPPORT VECTOR MACHINES SUPPORT VECTOR MACHINES: KERNEL LINEAL Se selecciona el set de 10 variables con dummies obtenido del nodo metadatos de Miner y se comienzan a realizar pruebas. En la figura 60, se realiza la personalización con las semillas que se han utilizado a lo largo del trabajo (12318 y 12400) y se fija el parámetro C(C=c(0.01,0.05,0.1,0.2,0.5,1,2,5,10)), ya que es el único parámetro que se puede modificar.
Figura 60. Resultado estudio parámetro C. Se obtienen resultados similares, por lo que se procede a generar un modelo con una C de 0.01 que se comparará con el resto de modelos de support vector machines y los modelos de los apartados anteriores. Figura 61. Box plot tasa de fallos Kernel Lineal y anteriores modelos.
En la figura 61, se compara el modelo de support vector machines Kernel Lineal con los modelos de los anteriores apartados, se observa que proporciona unos resultados peores, ya que se obtiene la mayor tasa de fallos de todos los modelos comparados. Figura 62. Box plot AUC Kernel Lineal y anteriores modelos. En la figura 62, se compara el modelo de support vector machines Kernel Lineal con los modelos de los anteriores apartados, se observa que proporciona los peores resultados en términos de AUC de todos los modelos comparados. SUPPORT VECTOR MACHINES: KERNEL POLINOMIAL Se selecciona el set de 10 variables con dummies obtenido del nodo metadatos de Miner y se comienzan a realizar pruebas. En la figura 63, se realiza la personalización con las semillas que se han utilizado a lo largo del trabajo (12318 y 12400) y se fija el parámetro C(C=c(0.01,0.05,0.1,0.2,0.5,1,2,5,10)), la escala (scale=c(0.1,0.5,1,2,5))) y el número de grados del polinomio (degree=c(2,3)).
Figura 63. Resultado personalización Kernel Polinomial.
Figura 64. Resultado personalización Kernel Polinomial. En la figura 64, se observa en los resultados obtenidos, que los modelos de grado 2 generan modelos más estables y con un mayor accuracy que los modelos de grado 3, por lo que se generará un gráfico, tal y como se observa en la figura 65, donde sólo aparezcan los resultados de los modelos de grado 2, para proceder a su comparación.
Figura 65. Resultado personalización Kernel Polinomial grado 2. En la figura 65, se observa una mejora mínima en los modelos con C=0.5, scale=1 y con C=1, scale=0.5. En la figura 66, se muestran los modelos más interesantes de este apartado. Figura 66. Mejores modelos Kernel Polinomial. Modelo C Scale Degree SVMPoly1 1 0.5 2 SVMPoly2 0.5 1 2
Figura 67. Box plot tasa de fallos Kernel Polinomial. En la figura 67 se observa que, en términos de tasa de fallos, el modelo support vector machines Kernel Polinomial 1 proporciona mejores resultados que el modelo support vector machines Kernel Polinomial 2. Figura 68. Box plot AUC Kernel Polinomial.
En la figura 68 se observa que en términos de AUC, el modelo support vector machines Kernel Polinomial 1 proporciona mejores resultados que el modelo support vector machines Kernel Polinomial 2. SUPPORT VECTOR MACHINES: KERNEL RBF Se selecciona el set de 10 variables con dummies obtenido del nodo metadatos de Miner y se comienzan a realizar pruebas. En la figura 69, se realiza la personalización con la semilla que se han utilizado a lo largo del trabajo (12318 y 12400) y se fija el parámetro C (C=c(0.01,0.05,0.1,0.2,0.5,1,2,5,10,30)) y el parámetro sigma ( c(0.0001,0.005,0.01,0.05,0.1,0.2,0.5,1,2,5,10,30)). Figura 69. Resultado personalización Kernel RBF.
Figura 70. Resultado personalización Kernel RBF. En la figura 70, se observan mejores resultados en C=0.2 con Sigma=10 y Sigma=30, por lo que se procederán a comparar estos modelos con los de los apartados anteriores. En la figura 71, se muestran los modelos más interesantes de este apartado. Figura 71. Mejores modelos Kernel RBF. Modelo C Sigma SVMRBF1 0.2 30 SVMRBF2 0.2 10
Figura 72. Box plot tasa de fallos Kernel RBF. En la figura 72 se observa que, en términos de tasa de fallos, el modelo support vector machines Kernel RBF 1 proporciona los mismos resultados que el modelo support vector machines Kernel RBF 2. Figura 73. Box plot AUC Kernel RBF.
También puede leer

















































