BUSCANDO UN MÉTODO PARA DETERMINAR LA CALIDAD DE UN VINO A PARTIR DE SUS PROPIEDADES USANDO TÉCNICAS ESTADÍSTICAS - Memoria y Anexos - TRABAJO DE ...
←
→
Transcripción del contenido de la página
Si su navegador no muestra la página correctamente, lea el contenido de la página a continuación
TRABAJO DE FINAL DE GRADO Grado en Ingeniería Química BUSCANDO UN MÉTODO PARA DETERMINAR LA CALIDAD DE UN VINO A PARTIR DE SUS PROPIEDADES USANDO TÉCNICAS ESTADÍSTICAS Memoria y Anexos Autor/a: Caballé Llufriu, Carles Convocatoria: Mayo 2021
Buscando un Método para Determinar la Calidad de un Vino a Partir de sus Propiedades usando Técnicas Estadísticas Resumen En este trabajo se han analizado los datos fisicoquímicos de una base de datos de vinos (variedad vinho verde) para clasificarlos en categorías según su calidad (nota de cata) mediante la creación de modelos estadísticos. Para ello, primero se han analizado los datos mediante indicadores estadísticos básicos y se han representado gráficamente. Posteriormente se han entrenado y verificado diferentes modelos estadísticos de clasificación. Los modelos predictivos estudiados son la regresión lineal (simple y múltiple), la distancia de Mahalanobis, los árboles de decisión y las máquinas de soporte de vectores. Los modelos se han verificado utilizando una parte aleatoria de los datos. Como indicadores de la capacidad de clasificación de los modelos se han utilizado indicadores estadísticos asociados a la matriz de confusión y a la curva ROC. Todos los algoritmos desarrollados se han realizado en el código Python. Los resultados muestran que el árbol de decisiones (Random Forest) es el método con mayor capacidad de clasificar los datos correctamente. i
Memoria Resum En aquest treball s’han analitzat les dades fisicoquímiques d’una base de dades de vins (varietat vinho verde) per a classificar-los en categories segons la seva qualitat (nota de tast), mitjançant la creació de models estadístics. Per a fer-ho, primer s’han analitzat les dades mitjançant certs indicadors estadístics bàsics i s’han representat gràficament. Posteriorment s’han entrenat i verificat diferents models estadístics de classificació. Els models predictius estudiats són la regressió lineal (simple i múltiple), la distància de Mahalanobis, els arbres de decisió i les màquines de suport de vectors. Els models s’han verificat utilitzant una part aleatòria de les dades. Com a indicadors de la capacitat de classificació dels models s’han utilitzat indicadors estadístics associats a la matriu de confusió i a la corba ROC. Tots els algoritmes desenvolupats s’han realitzat en codi Python. Els resultats mostren que els arbres de decisions (Random Forest), és el mètode amb la major capacitat de classificar les dades correctament. ii
Buscando un Método para Determinar la Calidad de un Vino a Partir de sus Propiedades usando Técnicas Estadísticas Abstract In the present work, a database of physical and chemical analyses from wines of the vinho verde variety have been analysed, with the aim of developing statistical models that can classify the wines into separate categories based on their quality (testing notes). To achieve that, the first step has been to provide an analysis of the data using basic statistics and graphs. After that, different classification statistical models have been trained and assessed. The statistical models in study have been: linear regression (simple and multiple), Mahalanobis distance, decision trees and support vector machines. The verification of the models has been performed with a random subset of the data. To qualify the performance of the classifier models, statistical parameters related with confusion matrix and ROC curves have been used. All the algorithms have been developed in Python. The results show that the decision tree (Random Forest) model performs the best within the studied models. iii
Memoria Agradecimientos Querría agradecer a Catalina su infinita paciencia y apoyo. iv
Buscando un Método para Determinar la Calidad de un Vino a Partir de sus Propiedades usando Técnicas Estadísticas Índice 1 INTRODUCCIÓN _________________________________________________ 9 2 DESCRIPCIÓN DE LOS MÉTODOS ESTADÍSTICOS _______________________ 11 2.1 Estadísticas básicas ................................................................................................ 11 2.2 Gráficos de probabilidad........................................................................................ 12 2.3 Histogramas y gráficos de barras........................................................................... 13 2.4 Boxplot ................................................................................................................... 14 2.5 Matriz de correlación ............................................................................................. 15 2.6 Regresión Lineal ..................................................................................................... 16 2.7 F-test de significancia global .................................................................................. 17 2.8 Distancia de Mahalanobis ...................................................................................... 18 2.9 Árbol de Decisiones................................................................................................ 19 2.10 Máquinas de vectores de soporte ......................................................................... 20 2.11 Matriz de confusión y curva ROC........................................................................... 21 3 DESCRIPCIÓN DE LAS VARIABLES __________________________________ 23 3.1 pH ........................................................................................................................... 23 3.2 Acidez Volátil .......................................................................................................... 24 3.3 Acidez Fija............................................................................................................... 24 3.4 Ácido Cítrico ........................................................................................................... 24 3.5 Azúcar Residual ...................................................................................................... 24 3.6 Alcohol.................................................................................................................... 25 3.7 Cloruros .................................................................................................................. 25 3.8 Dióxido de Azufre Libre .......................................................................................... 25 3.9 Dióxido de Azufre Total.......................................................................................... 26 3.10 Sulfatos ................................................................................................................... 26 3.11 Densidad................................................................................................................. 26 3.12 Calidad (variable respuesta) .................................................................................. 26 4 EXPLORACIÓN ESTADÍSTICA DE LOS DATOS __________________________ 27 4.1 Estadísticas básicas ................................................................................................ 27 4.2 Histogramas y gráfico de probabilidad .................................................................. 28 4.2.1 pH.......................................................................................................................... 28 4.2.2 Acidez volátil ......................................................................................................... 29 v
Memoria 4.2.3 Acidez fija ..............................................................................................................30 4.2.4 Ácido cítrico...........................................................................................................30 4.2.5 Azúcar residual ......................................................................................................31 4.2.6 Alcohol...................................................................................................................31 4.2.7 Cloruros .................................................................................................................32 4.2.8 Dióxido de azufre libre ..........................................................................................32 4.2.9 Dióxido de azufre total..........................................................................................33 4.2.10 Sulfatos ..................................................................................................................33 4.2.11 Densidad................................................................................................................34 4.3 Boxplot ................................................................................................................... 35 4.4 Conclusiones de la exploración estadística de las variables fisicoquímicas ......... 36 4.5 Exploración y categorización del parámetro respuesta........................................ 37 5 ANÁLISIS DE LOS DATOS _________________________________________ 39 5.1 Matriz de correlación............................................................................................. 39 6 MODELOS PREDICTIVOS _________________________________________ 43 6.1 Regresión Lineal Simple ......................................................................................... 43 6.1.1 Vino blanco............................................................................................................44 6.1.2 Vino tinto...............................................................................................................45 6.2 Regresión Lineal Múltiple ...................................................................................... 46 6.2.1 Vino blanco............................................................................................................47 6.2.2 Vino tinto...............................................................................................................51 6.3 Clasificación de Mahalanobis ................................................................................ 55 6.3.1 Vino blanco............................................................................................................55 6.3.2 Vino tinto...............................................................................................................57 6.4 Árbol de decisiones................................................................................................ 58 6.4.1 Vino blanco............................................................................................................58 6.4.2 Vino tinto...............................................................................................................60 6.5 Máquinas de soporte de vectores......................................................................... 66 6.5.1 Vino blanco............................................................................................................66 6.5.2 Vino tinto...............................................................................................................67 7 ANÁLISIS DEL IMPACTO AMBIENTAL _______________________________ 69 8 CONCLUSIONES ________________________________________________ 71 9 PRESUPUESTO _________________________________________________ 73 vi
Buscando un Método para Determinar la Calidad de un Vino a Partir de sus Propiedades usando Técnicas Estadísticas 10 PLANIFICACIÓN ________________________________________________ 75 11 BIBLIOGRAFÍA__________________________________________________ 77 ANEXO A – PROGRAMA ______________________________________________ 79 A1. Importación de librerías......................................................................................... 79 A2. Lectura de las bases de datos y asignación de nombres....................................... 79 A3. Datos estadísticos básicos ..................................................................................... 80 A3. Gráficas de probabilidad ........................................................................................ 81 A4. Histogramas ........................................................................................................... 82 A5. Boxplot ................................................................................................................... 83 A6. Gráfico de barras de calidad .................................................................................. 84 A7. Gráfico de barras de calidad por categorías.......................................................... 85 A8. Función para eliminación de valores atípicos ....................................................... 86 A9. Matriz de correlación de Pearson.......................................................................... 87 A10. Matriz de confusión ............................................................................................... 88 A11. Curva ROC .............................................................................................................. 89 A12. Separación de los datos en Test y Train ................................................................ 90 A13. Regresión Lineal Simple ......................................................................................... 90 A14. F-test....................................................................................................................... 91 A15. Regresión Lineal Múltiple ...................................................................................... 92 A16. Distancia de Mahalanobis ...................................................................................... 93 A17. Árbol de decisión.................................................................................................... 94 A18. SVM ........................................................................................................................ 95 vii
Buscando un Método para Determinar la Calidad de un Vino a Partir de sus Propiedades usando Técnicas Estadísticas 1 Introducción Todos hemos oído la frase: “Todos los vinos son iguales”. Esta opinión tan extendida (aunque no por ello cierta) sirve para poner de manifiesto la gran dificultad que entraña la cata de un vino para evaluar su calidad y características organolépticas. De hecho, incluso para el catador, a pesar del gran entrenamiento y su experiencia, es difícil evitar que sus valoraciones tengan cierto componente subjetivo, debido a la naturaleza humana del catador. Para superar esta subjetividad, ¿no sería posible que un ordenador evaluara la calidad de un vino? Si además se utilizasen los datos de los análisis fisicoquímicos que se realizan rutinariamente en los vinos como parte del control de calidad, se podría tener una indicación de la calidad de un vino sin necesidad de análisis adicionales a los que se realizan actualmente. Este trabajo pretende estudiar el desarrollo de modelos de clasificación a los datos de una variedad de vino portuguesa, el vinho verde. Estos datos son de acceso público en la web de la University of California Irvine (UCI), la cual dispone de un importante repositorio de bases de datos de acceso libre. Estos modelos estadísticos predictivos forman parte del campo conocido como machine learning. El machine learning consiste en el desarrollo de algoritmos en base a muestras de datos, para que estos algoritmos puedan tomar decisiones (regresiones, clasificaciones, etc) con datos que no ha analizado previamente. El machine learning son un campo desarrollado y en constante innovación, ya que es útil en muchas ciencias e ingenierías. Sus aplicaciones en el tratamiento de imágenes y bases de datos hacen que estos modelos puedan ser desarrollados por profesionales de muy diferentes ámbitos, permitiendo crear sinergias entre diferentes campos científicos. Los modelos predictivos que se han desarrollado en esta memoria tienen el objetivo de discernir los vinos entre dos categorías de calidad, partiendo de sus propiedades fisicoquímicas. Para la aplicación de estos modelos predictivos, primero se han explorado los datos mediante estadísticas descriptivas. Posteriormente, se han desarrollado y verificado los modelos estadísticos predictivos. Todos los algoritmos desarrollados para la descripción, análisis y modelado de los datos se han llevado a cabo mediante el código Python. El trabajo incluye un estudio de impacto ambiental, un presupuesto y una planificación. 9
Memoria 10
Buscando un Método para Determinar la Calidad de un Vino a Partir de sus Propiedades usando Técnicas Estadísticas 2 Descripción de los métodos estadísticos En el presente trabajo se han utilizado diferentes técnicas estadísticas. En esta sección se describen las técnicas usadas (descriptivas, de tratamiento, de clasificación, y de evaluación de los modelos). 2.1 Estadísticas básicas La desviación estándar (Ecuación 1) es un indicador estadístico que se expresa en las unidades de la variable, y que se define como la raíz cuadrada de la varianza. La desviación estándar nos da una indicación de cómo de cerca están agrupados los datos alrededor de la media. En una distribución normal, aproximadamente 2/3 (68,2%) de los datos se encuentran a ±1 StD de distancia de la media, y el 95,4% a ±2 StD de distancia de la media (Streiner 1996). ∑n (xi − x̅) = √ i=1 (1) StD: desviación estándar x1 , … , xn : n puntos de la variable x̅: media de la variable N: puntos del conjunto de datos Sin embargo, nuestros datos pueden no seguir una distribución normal. Los indicadores estadísticos curtosis (Ecuación 3) y skewness (Ecuación 2) pueden ser de ayuda para dirimir si los datos siguen o no esta distribución. La curtosis nos da una indicación de cómo son las colas de la campana de Gauss (normal). Una curtosis mayor que 0 significa que hay una mayor concentración de valores en las colas de la campana, respecto a una distribución normal. Por otro lado, la skewness indica si la distribución es o no simétrica. Una skewness mayor que 0 indica que los datos están distribuidos asimétricamente hacia la derecha, y una skewness menor que 0 indica asimetría hacia la izquierda (Croarkin and Tobias 2005). El umbral a partir del cual la curtosis o la skewness significan que la distribución de los datos no sigue la normal depende del tamaño de la muestra. De hecho, en bases de datos de gran tamaño, como es el caso, la utilidad de estos indicadores es limitada (Ghasemi and Zahediasl 2012), por lo que solamente se tendrán en cuenta como una indicación orientativa de la posible normalidad de los datos. ̅)3 n (xi − x √N(N − 1) ∑i=1 N ske = (2) N−2 StD3 (x − x̅)4 ∑ni=1 i kur = N −3 (3) StD 4 ske: skewness kur: curtosis 11
Memoria 2.2 Gráficos de probabilidad Los gráficos de probabilidad son un método visual para evaluar si una base de datos sigue una determinada distribución, como la normal. Los datos se representan versus la distribución teórica, de tal manera que los puntos deben formar una línea recta. La línea recta corresponde a una regresión lineal mediante el método de los mínimos cuadrados (Ecuación 9). Los puntos que no siguen dicha línea son puntos que no siguen la distribución. (Croarkin and Tobias 2005). Para construir los gráficos de probabilidad se representan los datos en el eje y, mientras que en el eje x se representan las medianas estadísticas de la distribución normal. Las medianas estadísticas (m) son estimadas mediante la aproximación de Filliben (Vogel 1986) (Ecuación 4). mi = 1 − mn para i = 1 mi = (i − 0,3175)⁄(n + 0,365) para i = 2, 3, … , n − 1 (4) mi = 0,5(1⁄n) para i = n Figura 1. Ejemplos de gráfico de probabilidad. En el ejemplo de la izquierda, los datos se alinean a la línea de referencia, mientras que en el ejemplo de la derecha los datos se desvían de la recta en el centro y en los extremos. Fuente: (Ghasemi and Zahediasl 2012) 12
Buscando un Método para Determinar la Calidad de un Vino a Partir de sus Propiedades usando Técnicas Estadísticas 2.3 Histogramas y gráficos de barras Los histogramas son representaciones gráficas utilizados para resumir la distribución de un conjunto de datos continuos. Para representar los datos, se divide el rango de datos en una serie de subgrupos del mismo tamaño y se representa la cantidad de veces que ese rango aparece en los datos. Mediante histogramas se pueden obtener indicaciones de la distribución de los datos. Por ejemplo, de un histograma podemos observar la ubicación y la escala de los datos, si existe simetría alrededor de su centro, etc. (Croarkin and Tobias 2005). Los gráficos de barras son muy similares a los histogramas. La diferencia es que los gráficos de barras se utilizan para datos no continuos, por lo que no es necesario dividir el rango de datos en subgrupos. Figura 2. Ejemplo de histograma (izquierda) y de gráfico de barras (derecha). Fuente: (Severino 2019). 13
Memoria 2.4 Boxplot Los gráficos de tipo boxplot (o gráfico de cajas) son una herramienta gráfica que sirve para mostrar la ubicación y variación de los datos. Son especialmente útiles si se utilizan comparativamente, ya que permiten mostrar las diferencias entre grupos de forma muy clara. El diagrama boxplot divide los datos en cuatro cuartiles con el mismo número de datos en cada uno. La “caja” del boxplot comprende los datos del segundo y tercer cuartiles, separados por la mediana. Es decir, el 50% de los datos se incluye en el interior de la caja, por lo que el 50% restante se encuentra fuera de ella. La distancia entre los límites de la “caja” se denomina distancia intercuartiles (IQR). Este parámetro permite definir los “bigotes” del diagrama, los cuales corresponden a 1,5·IQR desde los límites inferior y superior de la “caja”. Los datos fuera de los “bigotes” se consideran datos atípicos (outliers) (Severino 2019). Figura 3. Ejemplo de boxplot. Fuente: Elaboración propia. Para representar todas las variables en un único boxplot se pueden normalizar las variables, utilizando el escalado min-max (Ecuación 5) (Jain, Nandakumar, and Ross 2005). Esta normalización permite mostrar todas las variables en único gráfico de rango [0,1] sin afectar a la distribución de los datos. X − X min X′ = (5) X max − X min 14
Buscando un Método para Determinar la Calidad de un Vino a Partir de sus Propiedades usando Técnicas Estadísticas 2.5 Matriz de correlación La correlación es la relación estadística entre dos variables. Esta relación puede ser lineal o no lineal. Para indicar el grado de relación entre dos variables, se utiliza un indicador llamado coeficiente de correlación. Existen múltiples coeficientes de correlación, dependiendo del tipo de relación entre ellos. Para el caso de nuestra base de datos utilizamos el coeficiente de correlación de Pearson (r), el cual es útil para detectar relaciones lineales para variables continuas (Vinet and Zhedanov 2011) (Ecuación 6). ∑ni=1(xi − x̅)(yi − y̅) r= (6) √∑ni=1(xi − x̅)2 √∑ni=1(yi − y̅)2 r: coeficiente de correlación de Pearson (x1 , y1 ), … , (xn , yn ): n puntos de las dos variables y̅, x̅: medias de las variables Los coeficientes de correlación tienen un rango [-1,1], en el que 1 y -1 indican total correlación (positiva y negativa, respectivamente), y 0 indica que no hay ninguna correlación. 15
Memoria 2.6 Regresión Lineal La regresión lineal, o regresión de mínimos cuadrados, es el método de modelado más ampliamente utilizado. La regresión lineal se utiliza para ajustar los datos con una función de la forma expresada en la Ecuación 7. En el caso del presente trabajo las variables fisicoquímicas son las variables independientes y la calidad como variable dependiente (respuesta). La regresión lineal puede aplicarse tanto en casos multivariables como en casos con una única variable independiente (regresión lineal simple) (Croarkin and Tobias 2005). y = β1 x1 + ⋯ + βn xn + β0 + (7) y: variable dependiente x1 … xn : variables β0 … βn : coeficientes : error Se puede representar la ecuación de la regresión de forma matricial (Ecuación 8). A continuación, los parámetros βn que multiplican las variables independientes se obtienen mediante el método de los mínimos cuadrados (Ecuación 9), mediante el cual se minimiza la suma de las desviaciones cuadráticas entre los datos y el modelo. Y = βX + E (8) β = ( ′ )−1 y (9) Y: matriz de variable dependiente X: matriz de variables β: matriz de coeficientes : matriz de errores La regresión lineal es un modelo que presenta importantes limitaciones, entre ellas la poca capacidad de extrapolación hacia regiones de las cuales no se disponen datos, y su alta sensibilidad a la presencia de outliers (puntos atípicos), los cuales pueden afectar de manera importante al modelo (Croarkin and Tobias 2005). La regresión lineal proporciona un resultado en forma de datos continuos. Tras su implementación es necesario clasificar los resultados en las categorías de calidad del vino definidas. 16
Buscando un Método para Determinar la Calidad de un Vino a Partir de sus Propiedades usando Técnicas Estadísticas 2.7 F-test de significancia global El F-test de significancia global sirve para evaluar si un modelo predictivo basado en la regresión lineal proporciona un ajuste mejor que un modelo que no contenga variables independientes. Para ello, el test usa el valor F (Ecuación 10) para comprobar la validez de unas hipótesis: - La hipótesis nula (H0) afirma que un modelo sin variables independientes se ajusta tan bien como el modelo con variables independientes. - La hipótesis alternativa (H1) afirma que el modelo con variables independientes se ajusta mejor que el modelo sin variables independientes. RSS1 − RSS2 k 2 − k1 F= (10) RSS2 n − k2 F: valor F RSSi: suma cuadrática de los errores residuales de dos modelos diferentes, tras ajustarlos a los mismos datos k i : número de variables de cada modelo n: número de observaciones Para rechazar la H0, se debe comparar el p-valor del test con un nivel de significancia. Si el p-valor es inferior al nivel de significancia, el modelo de regresión se ajusta mejor los datos que el modelos sin variables independientes (Frost 2017). El test de significancia global se utiliza para analizar las variables que pueden formar parte de un modelo de regresión lineal múltiple (Ecuación 7), y descartar aquellas que no aporten significado al modelo predictivo. 17
Memoria 2.8 Distancia de Mahalanobis La distancia de Mahalanobis (Ecuación 11) es una medida de la distancia entre dos variables que utiliza la matriz de covarianza (Croarkin and Tobias 2005). La distancia de Mahalanobis permite crear modelos de clasificación binarios (Verdadero o Falso). ⃗ )′S −1 (x⃗ − y DM = √(x⃗ − y ⃗) (11) DM: distancia de Mahalanobis ⃗x, y ⃗ : variable vectorial S: matriz de covarianza La matriz de covarianza (Ecuaciones 12 y 13) es una matriz cuadrada que contiene la varianza de las variables en la diagonal y las covarianzas entre pares de variables (Croarkin and Tobias 2005). ∑ni=1(x⃗ − x̅)(y ⃗ − y̅) Cov = (12) n−1 Cov(x1 ) Cov(x1 , x2 ) ⋯ Cov(x1 , xn ) Cov(x2 , x1 ) Cov(x2 ) ⋯ Cov(x2 , xn ) S=[ ] (13) ⋮ ⋮ ⋱ ⋮ Cov(xn , x1 ) Cov(xn , x2 ) ⋯ Cov(xn ) Cov: covarianza ⃗x, ⃗y: variable vectorial (x1 , y1 ), … , (xn , yn ): n puntos de las dos variables y̅, x̅: medias de las variables S: matriz de covarianza La distancia de Mahalanobis es una versión mejorada de la distancia euclídea (Ecuación 14). Representa una ventaja respecto a ésta debido a que la distancia de Mahalanobis tiene en cuenta la covarianza de los datos, y a que las variables están escaladas y son adimensionales. Por ello, no es necesario seleccionar las variables para crear un modelo predictivo, ya que el peso de cada variable en la varianza es representado mediante la matriz de covarianza, ni tampoco es necesario normalizar los datos (Croarkin and Tobias 2005). n DE = √∑ ⃗ )2 (x⃗ − y (14) i=1 DE: distancia euclídea ⃗x, y ⃗ : observaciones individuales (puntos de datos) de dos variables i … n: número de observaciones 18
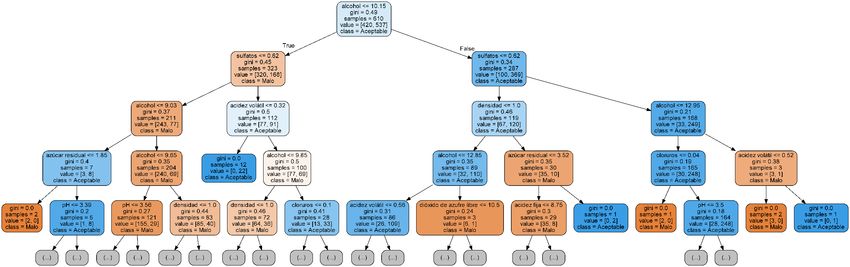
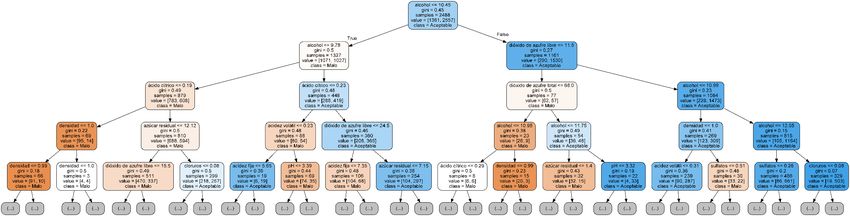
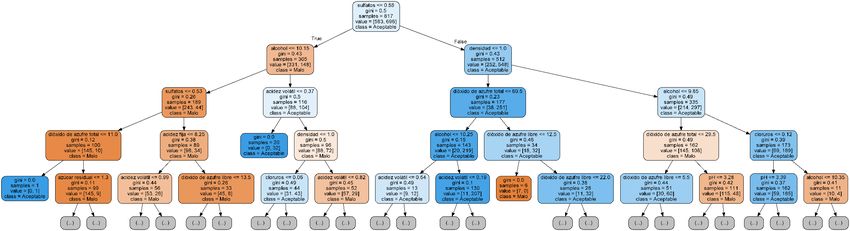
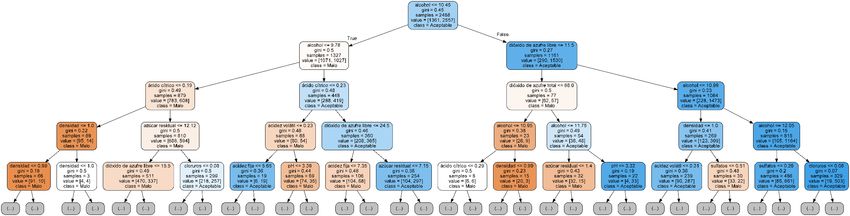
Buscando un Método para Determinar la Calidad de un Vino a Partir de sus Propiedades usando Técnicas Estadísticas 2.9 Árbol de Decisiones Los árboles de decisiones (Decision Tree) son una manera de mostrar las relaciones y clasificar datos, mostrando estas relaciones en forma de árbol filogénico. Las estructuras en forma de árbol proporcionan una representación jerárquica de las relaciones que se establecen entre los daos. Las hojas de los árboles (que representan los datos individuales) se distinguen por sus atributos. Estos atributos son características que determinan qué camino realizarán a través de las ramas de los árboles, que es dónde se realizan las decisiones. Normalmente, los árboles de decisiones se representan de arriba hacia abajo (al contrario que los árboles reales), ya que en la parte superior del árbol se ubica la base de datos completa, que se irá dividiendo mediante las decisiones codificadas en el árbol (Brown and Myles 2009). Las decisiones de división se realizan en los nodos. Las divisiones son siempre en dos subgrupos, uno para cada categoría. Para dividir una muestra que llega a un nodo, el algoritmo tiene en cuenta los inputs de varias variables. La “bondad” de la división viene indicada por el índice de Gini, el cual indica el grado de “impureza” de una distribución. El coeficiente de Gini tiene un rango de [0,1], en el que el 0 indica la total igualdad de la muestra, y el 1 la total desigualdad (Brown and Myles 2009). El tipo de árbol de decisiones utilizado se denomina Random Forest. Este método se caracteriza por: - Realizar varios árboles de decisiones a la vez. Los árboles “votan” por una u otra categoría, y la categoría con más votos es la elegida. - En cada árbol los datos son re-muestreados, con lo que le mismo dato puede ser utilizado en diversos árboles. Figura 4. Ejemplo de representación gráfica de árbol de decisión para la identificación de vidrio forénsico. Fuente: (Brown and Myles 2009) 19
Memoria 2.10 Máquinas de vectores de soporte Las máquinas de vectores de soporte (SVM, de support vector machines), son algoritmos de clasificación y regresión. El algoritmo consiste en la asignación sucesiva de cada punto de datos a una de las categorías de clasificación. Desde el punto de vista geométrico, el algoritmo busca encontrar la ecuación para una superficie multidimensional (hiperplano) que separe de la mejor manera las diferentes categorías (Awad and Khanna 2015). Las SVM generan, a partir de los puntos más cercanos al hiperplano, vectores (llamados “de soporte”), que se van a utilizar para las futuras predicciones. De todos los datos utilizados para “entrenar” al modelo, solamente los vectores de soporte vana seguir utilizándose, por lo que el resto de datos de entrenamiento quedan liberados. Estos vectores de soporte, que se utilizan para generar el hiperplano, deben cumplir la condición de estar lo más alejados posible de cada una de las categorías. Esto permite que cuando se utiliza el algoritmo sobre los datos reales, se reduzca la probabilidad de mal clasificar datos (Awad and Khanna 2015). Figura 5. Hiperplano (línea punteada) separando dos categorías de datos. El hiperplano está separado lo máximo posible de los datos (distancia 1/w). Fuente: (Awad and Khanna 2015) 20
Buscando un Método para Determinar la Calidad de un Vino a Partir de sus Propiedades usando Técnicas Estadísticas 2.11 Matriz de confusión y curva ROC La matriz de confusión y la curva ROC son los métodos elegidos para visualizar y comparar el desmpeño de los diversos modelos predictivos desarrollados (Castrounis 2021): regresión lineal simple y múltiple, distancia de Mahalanobis, árboles de decisión y SVM. Todas las clasificaciones que conforman el presente trabajo son en dos categorías: “Aceptable” (A) y “Malo” (M) (Figura 26). Se considerará la categoría A como la clase positiva, y la categoría M como la clase negativa. En la matriz de confusión se incluyen los 4 posibles resultados de cada modelo: muestra de A asignada a A (positivo real), muestra de M asignada a M (negativo real), muestra de A asignada a M (falso positivo) y muestra de M asignada a A (falso negativo). Clase M (real) Clase A (real) Clase A (asignada por el modelo) b a Clase M (asignada por el modelo) d c Figura 6. Matriz de confusión. Fuente: Elaboración propia. A partir de estos datos se pueden definir los indicadores del desempeño siguientes (Lavine 2009): - Exactitud: a+d acc = (15) a+b+c+d - Ratio de positivos reales: a tpr = (16) a+c - Ratio de negativos reales: d tnr = (17) b+d - Ratio de falsos positivos: b fpr = (18) b+d - Ratio de falsos negativos: c fnr = (19) a+c 21
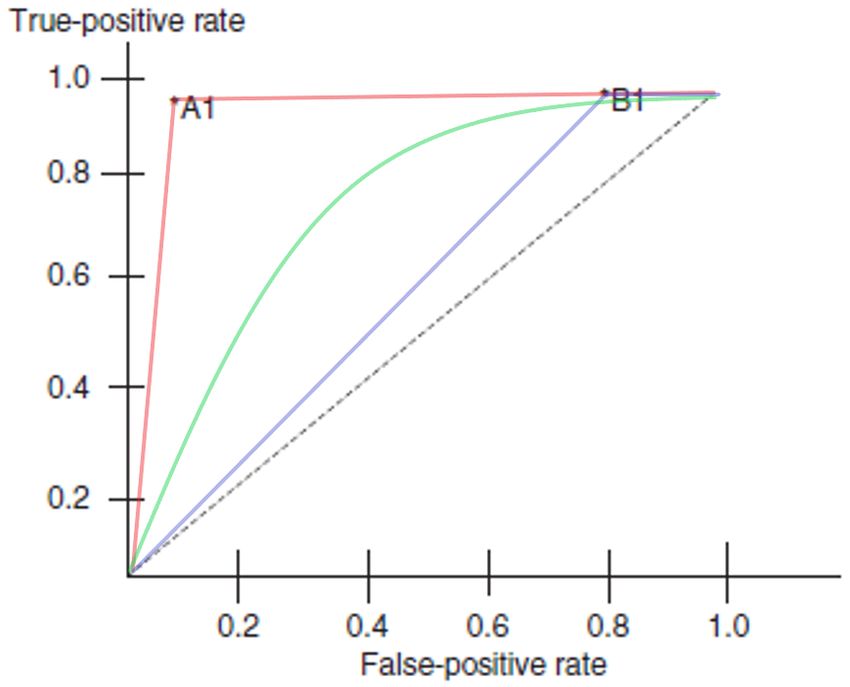
Memoria La curva ROC (de Receiver Operating Characteristic) se desarrolla a partir de la matriz de confusión. La curva (Figura 7) representa la ratio de positivos reales versus la ratio de falsos positivos. El punto (0,1) del gráfico representa un modelo predictivo 100% exacto, mientras que la línea diagonal punteada representa un modelo de clasificación aleatorio (Lavine 2009). En el caso de modelos continuos no es evidente cuál es el punto de la curva ROC que debe considerarse para calcular la exactitud del modelo. Por ello, como indicación de la exactitud de los modelos se utiliza el parámetro AUC (Area Under the Curve), que constituye el área bajo la curva ROC, y que tiene un rango [0,1]. Un valor de 0,5 representa la clasificación aleatoria, y un valor de 1 representa un modelo 100% exacto (Cerda and Cifuentes 2012). Figura 7. Ejemplo de curva ROC, con dos variables discretas representadas (A1, rojo; y B1, verde). Se puede observar que A1 representa un modelo muy exacto, mientras que B1 representa un modelo casi aleatorio. También se representa una curva ROC de una variable continua (verde). Fuente: (Lavine 2009), con modificaciones de elaboración propia. En la se establece un criterio de evaluación de la capacidad de clasificación de los modelos según su puntuación AUC (Mandrekar 2010). Tabla 1. Criterio de interpretación de los valores de AUC. Fuente: (Mandrekar 2010) 0,6≥AUC>0,5 Clasificación muy pobre 0,7≥AUC>0,6 Clasificación pobre 0,8≥AUC>0,7 Clasificación aceptable 0,9≥AUC>0,8 Clasificación excelente AUC>0,9 Clasificación sobresaliente 22
Buscando un Método para Determinar la Calidad de un Vino a Partir de sus Propiedades usando Técnicas Estadísticas 3 Descripción de las variables Para la realización del presente trabajo se ha dispuesto de dos bases de datos de calidad de vinos blancos y tintos, respectivamente. Los datos corresponden a vinos de la variedad Vinho Verde, proveniente de la región de Minho, en Portugal. La base de datos del vino blanco está compuesta por 4898 vinos, mientras que la base de datos del vino tinto contiene 1599 vinos. Los datos incluyen parámetros fisicoquímicos y un parámetro de calidad sensorial (cata). Los datos fueron recogidos entre Mayo de 2004 y Febrero de 2007 y analizados por la entidad certificada CVRVV (Comissão de Viticultura da Região dos Vinhos Verdes) (Cortez et al. 2009). Los parámetros fisicoquímicos de un vino deben seleccionarse para que sean útiles para definir la composición química de un vino, el cual puede contener varios centenares de sustancias químicas. La composición química de un vino es la que determinará sus atributos sensoriales (aroma, sabor, color, etc.). Sin embargo, puede resultar extraordinariamente complejo relacionar la composición química con los menciona dos atributos sensoriales. Por ejemplo, raramente se puede adscribir un aroma particular a unos pocos compuestos volátiles, sino que normalmente las fragancias distintivas se deben a la combinación de muchos compuestos volátiles orgánicos (Jackson 2008). Los parámetros fisicoquímicos que componen los conjuntos de datos son: 3.1 pH El pH es una indicación de la acidez o alcalinidad de una solución. Se trata de una escala logarítmica, en la que los valores por encima de 7 corresponden a soluciones alcalinas, y los valores por debajo corresponden a soluciones ácidas. En el caso del vino, el pH viene determinado por la presencia de un amplio abanico de sustancias, en especial por los ácidos. Es deseable mantener un pH bajo (entre 3.1 y 3,4 en vinos blancos, y entre 3.3 y 3.6 en vinos tintos). Un bajo pH permite evitar la oxidación de ciertos compuestos del vino, como las antocianinas y los compuestos fenólicos. Además, un bajo pH tiene efectos antimicrobianos, ya que la mayoría de las bacterias no prolifera en estas condiciones (Jackson 2008). R − COOH ⇋ R − COO− + H + ácido radical ion orgánico carboxilo hidrógeno Figura 8. Los ácidos orgánicos se caracterizan por la presencia del grupo ácido (-COOH). Este grupo tiene la capacidad de liberar iones H+, los cuales son el principal contribuyente a la acidificación de una solución acuosa. Fuente: (Jackson 2008). 23
Memoria 3.2 Acidez Volátil La acidez volátil se refiere a los ácidos orgánicos que se pueden eliminar mediante destilación por arrastre de vapor. El ácido acético es el principal responsable de la acidez volátil, aunque otros ácidos (fórmico, butírico, propiónico) también juegan un papel. Su presencia en el vino proviene principalmente del metabolismo de bacterias y levaduras (Jackson 2008). 3.3 Acidez Fija La acidez fija se refiere a los ácidos orgánicos que no se incluyen en la categoría de volátiles. Son cuantitativamente más abundantes que los ácidos volátiles, con lo que controlan el pH del vino. Los principales ácidos que contribuyen a la acidez fija son: tartárico, málico, y ácidos tri-carboxílicos (cítrico, isocítrico, fumárico, α-cetoglutárico) (Jackson 2008). 3.4 Ácido Cítrico El ácido cítrico es uno de los compuestos que contribuyen a la acidez fija. La presencia de este ácido en el vino puede deberse al metabolismo de la levadura, o bien a la adición artificial para rebajar el pH del vino (Jackson 2008). Figura 9. Fórmula estructural del ácido cítrico. Fuente: (Fidber, Graule, and Gouckler 1996). 3.5 Azúcar Residual La fermentación de los azúcares (principalmente glucosa y fructosa) es la principal fuente de obtención de alcohol (Figura 10). Los azúcares no fermentados conforman los azúcares residuales, los cuales están principalmente formados por pentosas (e.g. arabinosa, ramnosa y xilosa). El contenido en azúcares residuales puede variar mucho entre las distintas variedades de vino, siendo especialmente importante en los vinos dulces (Jackson 2008). 24
Buscando un Método para Determinar la Calidad de un Vino a Partir de sus Propiedades usando Técnicas Estadísticas 3.6 Alcohol El vino, como bebida alcohólica, tiene un contenido en alcohol del 10-15% en la mayoría de los vinos. El alcohol etílico constituye la inmensa mayoría de alcoholes presentes, obtenido mediante destilación alcohólica de los azúcares (Figura 10). El resto de los alcoholes presentes (metanol, alcoholes de fusel, glicerol, dioles, etc.) se encuentran en el vino de forma residual y no tienen impacto significativo en las propiedades organolépticas del vino (Jackson 2008). 3.7 Cloruros Los cloritos (principalmente cloruro de sodio, NaCl) forman parte de los múltiples minerales que forman el vino, los cuales provienen de la absorción del suelo por las raíces de la vid. El cloruro de sodio puede tener un impacto significativo en las propiedades organolépticas del vino, debido a su sabor salado (Coli et al. 2015). Figura 10. Fermentación alcohólica por la vía glicolítica. 3.8 Dióxido de Azufre Libre Obsérvese el producto de partida (glucosa) y el producto final (etanol). Fuente: (Jackson 2008). El dióxido de azufre (SO2) es un componente de gran relevancia en la fabricación del vino. Se produce naturalmente durante la fermentación, y posteriormente se añade más de manera artificial. Es de gran importancia por sus propiedades antimicrobianas y antioxidantes, así como por su capacidad para blanquear pigmentos y eliminar olores oxidados. El dióxido de azufre puede encontrarse en su forma libre como gas disuelto (SO2), como ion sulfito (SO32-) o como ion bisulfito (HSO3-) (Jackson 2008). SO2 +H2 O ⇋ H + + HSO− + 2− 3 ⇋ 2H + SO3 dióxido de ion ion azufre bisulfito sulfito molecular Figura 11. Equilibrio entre la forma molecular del dióxido de azufre y los iones sulfito y bisulfito. Fuente: (Scrimgeour et al. 2015). 25
Memoria 3.9 Dióxido de Azufre Total El dióxido de azufre se encuentra en parte ligado a moléculas orgánicas (antocianinas, α-cetoglutarato, acetaldehído, etc.). Mediante estas asociaciones, el dióxido de azufre desactiva pigmentos y aromas indeseados. El dióxido de azufre libre sumado al dióxido de azufre ligado conforman el dióxido de azufre total (Jurd 1964)(Jackson 2008). CH3 CHO +H2 O + SO2 ⇋ CH3 CHOH − HSO3 acetaldehído dióxido acetaldehído de azufre hidroxisulfonato Figura 12. Reacción de neutralización del acetaldehído con dióxido de azufre. Fuente: (Jackson 2008). 3.10 Sulfatos Los sulfatos (en concreto el sulfato de potasio) forman parte de los múltiples minerales que forman el vino, los cuales provienen de la absorción del suelo por las raíces de la vid (el sulfato de potasio se añade al suelo como fertilizante). También pueden aparecer sulfatos en el vino una vez embotellado, por la oxidación de los sulfitos en sulfatos. 3.11 Densidad La densidad (relación peso/volumen) del vino viene determinada principalmente por sus constituyentes más abundantes (agua y alcohol), los cuales tienen densidades diferentes. 3.12 Calidad (variable respuesta) La calidad del vino se determina mediante la evaluación sensorial del mismo (cata). Los vinos de las bases de datos han sido catados por, al menos, tres catadores que los han puntuado en una escala entre 0 (muy malo) y 10 (excelente). La calidad final de cada vino es dada por la mediana de las puntuaciones (Cortez et al. 2009). 26
Buscando un Método para Determinar la Calidad de un Vino a Partir de sus Propiedades usando Técnicas Estadísticas 4 Exploración estadística de los datos El objetivo del presente trabajo es utilizar modelos predictivos para, partiendo de las variables fisicoquímicas, poder estimar la calidad de los vinos. Para ello, en los siguientes apartados se empieza por explorar las bases de datos mediante parámetros y gráficos estadísticos básicos, con el objetivo de tener una visión general de los mismos y poder empezar a detectar posibles relaciones. 4.1 Estadísticas básicas En la Tabla 2 se muestran, para cada variedad de vino, los siguientes valores relevantes y parámetros estadísticos: máximo (max), mínimo (min), la media (med), desviación estándar (StD), curtosis (kur) y asimetría (ske, de skewness). Tabla 2. Estadísticas básicas de los datos fisicoquímicos y la calidad. Fuente: Elaboración propia. Vino blanco Vino tinto Atributos min max med StD kur ske min max med StD kur ske pH 2,72 3,82 3,19 0,151 0.529 0.458 2,74 4,01 3,31 0,154 0.801 0.193 Acidez volátil (g(ácido 0,08 1,10 0,28 0,101 5.085 1.576 0,12 1,58 0,53 0,179 1.218 0.671 acético)/dm3) Acidez fija (g(ácido 3,8 14,2 6,9 0,842 2.169 0.648 4,6 15,9 8,3 1,741 1.125 0.982 tartárico)/dm3) Ácido cítrico (g/dm3) 0,00 1,66 0,33 0,121 6.167 1.282 0,00 1,00 0,27 0,195 -0.790 0.318 Azúcar residual 0,6 65,8 6,4 5,072 3.465 1.077 0,9 15,5 2,5 1,410 28.52 4.536 (g/dm3) Alcohol (vol.%) 8,0 14,2 10,5 1,230 -0.699 0.487 8,4 14,9 10,4 1,065 0.196 0.860 Cloruros 0,009 0,346 0,046 0,022 37.53 5.022 0,012 0,611 0,087 0,047 41.58 5.675 (g(NaCl)/dm3) Dióxido de azufre 2 289 35 17,01 11.45 1.406 1 72 16 10,46 2.013 1.249 libre (mg/dm3) Dióxido de azufre 9 440 138 42,49 0.570 0.391 6 289 46 32,89 3.794 1.514 total (mg/dm3) Sulfatos 0,22 1,08 0,49 0,114 1.588 0.977 0,33 2,00 0,66 0,170 11.68 2.426 (g(K2SO4)/dm3) Densidad (g/cm3) 0,987 1,039 0,994 0,003 9.783 0.977 0,990 1,004 0,997 0,002 0.927 0.071 Calidad 3 9 5,88 0,886 0.215 0.156 3 8 5,64 0,807 0.292 0.218 27
Memoria 4.2 Histogramas y gráfico de probabilidad Siguiendo con el análisis exploratorio de los datos, se han obtenido los gráficos de probabilidad y los histogramas de los parámetros fisicoquímicos. 4.2.1 pH En los datos del pH de la Tabla 2 observamos que los vinos tintos tienen un pH medio superior a los vinos blancos (es decir, los vinos blancos son más ácidos). Los datos de ambos vinos muestran una distribución similar en el gráfico de probabilidad (Figura 13), con un buen ajuste a la línea de regresión. En los extremos del gráfico de probabilidad se observa la misma desviación respecto a la recta, tanto en vinos blancos como en tintos, lo cual puede indicar un sesgo en la distribución normal de los datos. En el histograma de los vinos blancos se observa cierta asimetría hacia la derecha, cosa que también nos indica la skewness de 0,458. Figura 13. Gráfico de probabilidad e histograma del parámetro pH. Fuente: Elaboración propia. 28
Buscando un Método para Determinar la Calidad de un Vino a Partir de sus Propiedades usando Técnicas Estadísticas 4.2.2 Acidez volátil Esta variable muestra diferencias significativas entre los vinos blancos y tintos. Los vinos tintos muestran una acidez volátil superior respecto a los blancos (0,53 vs 0,28 g(ácido acético)/dm3). (Tabla 2). Tanto en el gráfico de probabilidad como en el histograma (Figura 14), se observa también como los valores del vino tinto son más elevados que los del vino blanco. En el gráfico de probabilidad, podemos observar que los datos se desvían significativamente de la recta, especialmente en el extremo superior del vino blanco. En el histograma, se observa que el vino tinto tiene una distribución de datos de campana aplanada, mientras que el vino blanco muestra una alta frecuencia de datos alrededor de la media. En ambos casos, los histogramas son asimétricos hacia la derecha y con colas largas (skewness positiva). Figura 14. Gráfico de probabilidad e histograma del parámetro acidez volátil. Fuente: Elaboración propia. 29
Memoria 4.2.3 Acidez fija La acidez fija muestra un comportamiento similar a la acidez volátil, con una media de valores más elevados en el caso del vino tinto. En el gráfico de probabilidad se observa una que los datos se desvían de la recta en los extremos. El histograma muestra que los datos del vino blanco están más concentrados alrededor de la media, dando lugar a una campana alta, mientras que en el vino tinto los valores están más repartidos, con una clara asimetría hacia la derecha (skewness positiva). Figura 15. Gráfico de probabilidad e histograma del parámetro acidez fija. Fuente: Elaboración propia. 4.2.4 Ácido cítrico Las medias del ácido cítrico en las dos variedades de vino son muy cercanas. Sin embargo, observando el gráfico de probabilidad y el histograma se observa que los datos están distribuidos de manera desigual. Mientras que en el vino blanco los datos están concentrados alrededor de la media, en el vino tinto están distribuidos. En el caso del vino tinto, los datos están condicionados por la abundancia de vinos con valores de 0 g/dm3. Figura 16. Gráfico de probabilidad e histograma del parámetro ácido cítrico. Fuente: Elaboración propia. 30
Buscando un Método para Determinar la Calidad de un Vino a Partir de sus Propiedades usando Técnicas Estadísticas 4.2.5 Azúcar residual El azúcar residual muestra claras diferencias entre el vino blanco y el tinto. En el caso del vino tinto, cuya media es la más baja de los dos, observamos que hay muchos valores de 0 g/dm3 o muy cercanos. En el caso del vino blanco también se da el caso, pero también hay vinos con valores mucho más elevados. En ambos casos, la gran cantidad de valores cercanos a 0 g/dm3 hace que los histogramas sean claramente asimétricos (skewness positiva). Figura 17. Gráfico de probabilidad e histograma del parámetro azúcar residual. Fuente: Elaboración propia. 4.2.6 Alcohol En este caso, no se observan diferencias significativas en la distribución de los datos en los vinos blancos y tintos. La media y el rango de datos son muy similares, así como los gráficos de probabilidad e histogramas. En el gráfico de probabilidad, observamos que, en los valores bajos, el desvío respecto a la recta es mayor, mientras que en el histograma observamos que la cola derecha es mucho más larga que la cola izquierda, que es precisamente dónde se detecta el desvío en el gráfico de probabilidad (skewness positiva). Figura 18. Gráfico de probabilidad e histograma del parámetro alcohol. Fuente: Elaboración propia. 31
Memoria 4.2.7 Cloruros El nivel de cloruros es más elevado en los vinos tintos que en los blancos. Ambos vinos muestran una distribución de los datos muy similar, en la que la mayoría de los valores se agrupan alrededor de la media, y sin embargo existe alrededor de un 5% de los datos (observable en el gráfico de probabilidad) cuyos valores son mucho más elevados que la mayoría, lo que causa una larga cola hacia la derecha en el histograma (skewness positiva). Figura 19. Gráfico de probabilidad e histograma del parámetro cloruros. Fuente: Elaboración propia. 4.2.8 Dióxido de azufre libre El dióxido de azufre libre tiene una media de valores más elevada en el vino blanco respecto al tinto. Además, la distribución de los datos no es similar. En el caso del vino tinto se observan muchos valores cercanos a 0 g/dm3, lo que causa que la distribución de datos sea asimétrica (skewness positiva). En el caso del vino blanco la distribución es mucho más uniforme alrededor de la media, aunque esta distribución se encuentra truncada por el mínimo (0 g/dm3), por lo que la distribución está sesgada hacia la derecha (skewness positiva). Figura 20. Gráfico de probabilidad e histograma del parámetro dióxido de azufre libre. Fuente: Elaboración propia. 32
Buscando un Método para Determinar la Calidad de un Vino a Partir de sus Propiedades usando Técnicas Estadísticas 4.2.9 Dióxido de azufre total En el caso del dióxido de azufre se observa una situación análoga a la del dióxido de azufre libre, en la que la distribución del vino tinto es muy asimétrica y con muchos valores cercanos a 0 g/dm3, mientras que en el vino blanco la distribución se asemeja mucho a una distribución normal, aunque con cierto sesgo hacia los valores altos (skewness positiva). Figura 21. Gráfico de probabilidad e histograma del parámetro dióxido de azufre total. Fuente: Elaboración propia. 4.2.10 Sulfatos La concentración de sulfatos es más elevada en los vinos tintos que en los vinos blancos. Ambos tipos de vino muestran una gráfica de probabilidad parecida, con un encaje bastante alto con la recta en los valores centrales y una desviación de ella en el 10% más alto y en el 10% más bajo. El histograma muestra que ambos vinos tienen un sesgo importante hacia la derecha (skewness positiva). Figura 22. Gráfico de probabilidad e histograma del parámetro sulfatos. Fuente: Elaboración propia. 33
También puede leer

















































