DETECCIÓN DE TENDENCIAS BURSÁTILES EN TWITTER EN RELACIÓN CON LOS MERCADOS
←
→
Transcripción del contenido de la página
Si su navegador no muestra la página correctamente, lea el contenido de la página a continuación
DETECCIÓN DE TENDENCIAS BURSÁTILES EN TWITTER EN RELACIÓN CON LOS MERCADOS Daniel Sánchez Louzán Trabajo de fin de grado Escuela de Ingeniería de Telecomunicación Grado en Ingeniería de Tecnologías de Telecomunicación Tutores Silvia García Méndez Francisco de Arriba Pérez Curso 2020/2021
Índice I. Introducción 4 A. Machine learning 4 B. Natural language processing 4 II. Objetivos 6 III. Metodología 6 A. Elaboración y preparación del dataset 6 B. Clasificación 7 C. Entrenamiento 10 D. Evaluación 10 IV. Resultados 12 V. Conclusiones 16 VI. Líneas futuras 16 VII. Bibliografía 17 VIII. Anexos 19 A. Estado del arte 19 B. Procedimiento para la consulta y extracción de los precios del activo 20
I. Introducción Twitter se define como una plataforma social de microblogueo en la que más de 350 millones de adeptos mensualmente activos comparten pensamientos e inquietudes de forma instantánea, se promocionan y mantienen actualizados diariamente con las noticias más recientes. Cada día se intercambian más de 500 millones de mensajes de diversa índole en todo el mundo, lo que convierte a Twitter en un vasto banco de datos heterogéneo, fiable (ya que en numerosas ocasiones la información es fácilmente contrastable o procede de fuentes oficiales y validadas por el resto de la comunidad) y actualizado, propiedad de vital importancia en un mundo que varía constantemente y en el que es necesario combatir la obsolescencia. Como ya se ha mencionado, la diversidad en la temática de estos tweets es muy amplia, pero existen algunos temas que presentan una mayor relevancia determinada por la novedad, controversia u originalidad del mismo, el número de veces que se comparte el mensaje o quien lo comparte. Estos son los trending topics o tendencias. Las tendencias de interés para la realización del presente estudio serán todas aquellas relacionadas con el mercado bursátil, en el que individuos e instituciones tienen la posibilidad de invertir a través de la compra de activos. Idealmente, el máximo beneficio se obtiene adquiriendo acciones al menor precio posible y vendiéndolas en el momento en el que alcanzan el máximo precio antes de que descienda, pero realizar la transacción perfecta no es sencillo y requiere de conocimiento y experiencia, la cual no garantiza que tenga lugar, debido a la complejidad de detección de tendencias alcistas para venta y tendencias bajistas para compra. Teniendo en cuenta esta situación podría surgir la siguiente cuestión: ¿Es realmente posible identificar prematuramente estas tendencias, de forma fiable, y obtener el consiguiente beneficio? La respuesta es afirmativa y la solución obtenida para este problema se presenta en este informe. Existen dos conceptos clave que son la base para el desarrollo del estudio: machine learning [1] y natural language processing [2]. A. Machine learning El aprendizaje automático es un ámbito de la inteligencia artificial que dota a un sistema con la capacidad de identificar patrones, mediante algún algoritmo, para realizar predicciones y automatizar tareas de forma autónoma. Los distintos algoritmos se pueden agrupar en función de su naturalidad como: algoritmos de aprendizaje no supervisado, de aprendizaje por refuerzo y de aprendizaje supervisado. Los algoritmos empleados y evaluados para esta solución se corresponden con la última de las familias de algoritmos mencionada, cada uno de los integrantes de esta familia cuenta con un aprendizaje basado en experiencias previas, estructuradas como datos etiquetados, a partir de las cuales es posible realizar predicciones y tomar decisiones. El conjunto de datos empleado contiene una serie de tweets compartidos por los usuarios y determinadas propiedades que lo definen, haciendo posible la identificación de tendencias. B. Natural language processing El NLP es un campo de estudio que combina la informática, la inteligencia artificial y la lingüística, a través del cual un ordenador es capaz de interpretar, comprender y procesar el lenguaje humano. Para llevar a cabo esta tarea las máquinas son programadas para identificar patrones y realizar inferencias estadísticas a partir del texto. Estas predicciones también se pueden realizar a partir del reconocimiento de voz realizando un procesado de la señal de audio y convirtiéndola al texto sobre el que se aplicarán las reglas del NLP. La mayor parte de las tareas involucradas en el proceso del NLP se basan en extraer significado de las propiedades del texto: 4
Tokenization, stop words y stemming La primera tarea en el procesado es la tokenization que fragmenta el texto u oración en segmentos, estos segmentos son oraciones en un texto o palabras en una oración. Posteriormente, se produce la eliminación de todas aquellas palabras gramaticales que carecen de significado léxico, las stop words. Finalmente, con el stemming se extrae el lexema de cada uno de los fragmentos del proceso anterior para reducir la redundancia. Análisis del sentimiento El sentimiento [3] es una disposición emocional de la que se tiene que extraer un valor numérico o puntuación que determine el grado de ese sentimiento. Este análisis determina la tendencia emocional a la que se le asigna un valor que refleja la positividad, negatividad o neutralidad de la misma. $WTI Los 55 son claves para pensar en una salida alcista. Débil https://t.co/6biM0k2M9D Tokenization Eliminación de stop words Stemming Figura 1:Diagrama de flujo del NLP con el análisis del sentimiento para uno de los tweets del dataset 5
II. Objetivos El objetivo principal del estudio es el desarrollo de un sistema de detección de tendencias en el mercado bursátil [4] mediante el análisis de mensajes de texto emitidos en la plataforma social Twitter, aplicando un modelo de machine learning. Para ello se han evaluado distintos clasificadores a fin de obtener la mayor exactitud para la predicción de oportunidades de inversión. Para la consecución de este objetivo se han alcanzado una serie de hitos intermedios que contribuyen en el proceso de obtención del resultado final: El primero se basa en obtener un banco de datos completo, a partir de los tweets publicados, que será el empleado para entrenamiento y prueba. Una vez obtenido es necesario elegir el modelo que mejor se ajusta al problema en cuestión. Este objetivo se alcanza gracias a la comprensión, análisis, evaluación y aplicación de los diferentes clasificadores sobre el banco de datos conformado previamente. Por último, se establece como hito final la obtención e interpretación de los resultados conseguidos que permiten conocer la exactitud del sistema frente a la problemática planteada. III. Metodología A. Elaboración y preparación del dataset El conjunto de datos inicial se compone de 2,337 tweets relacionados con el ámbito financiero, donde cada entrada contiene el texto del tweet, la fecha en la que se comparte, el análisis del sentimiento del escritor (‘neutro’, ‘positivo’ o ‘negativo’) y la variable objetiva ‘Emotion’ que etiqueta el mensaje como ‘oportunidad’ o ‘precaución’. Este dataset está incompleto y es necesario adecuarlo al problema de clasificación que se presenta. Tabla I: Extracto del dataset inicial ‘Text’ ‘Polarity’ ‘Emotion’ ‘Date’ El #Ibex35 reduce sus subidas del 1% ‘positivo’ ‘precaución’ Mon Jul 01 11:07:08 2019 al 0,3% #Preapertura: El #Ibex35, pendiente de EEUU para reforzar el 2% de ‘neutro’ ‘oportunidad’ Fri Jul 05 08:38:11 2019 subida semanal. Entramos en periodo estacional bajista ‘negativo’ ‘precaución’ Wed Oct 09 18:26:04 2019 en #SP500 El proceso de elaboración y preparación del dataset sobre el que se realizan las pruebas se puede dividir en tres etapas: Identificación de los tickers La primera etapa del proceso consiste en identificar los tweets que mencionan un único ticker [5] (código alfanumérico único que identifica a un activo financiero en el mercado bursátil). Para ello se han empleado patrones de búsqueda para localizar los códigos en el texto (precedidos, en su mayoría, por los símbolos ‘$’ o ‘#’) de forma automática. Aquellos códigos no localizados de este modo se han identificado manualmente. 6
Obtención del precio del activo Una vez identificados todos los tickers se ha realizado la búsqueda del precio del activo en la fecha de emisión del tweet, en el día anterior y en el día posterior mediante consultas GET a uk.finance.yahoo.com, ya que dispone de datos históricos de precios, indicando el ticker y el rango de fechas de interés. Con la información obtenida se actualiza el dataset incluyendo, además de los precios diarios, la propiedad ‘Variación precio’ que refleja la diferencia de precio del activo entre el día de la emisión y el anterior, además de la columna ‘Estado’ que indica si el precio se ‘mantuvo’, se produjo una ‘subida’ o una ‘bajada’. En este apartado surge la problemática de no disponer de información sobre los precios durante el fin de semana, la cual se ha resuelto teniendo en cuenta las siguientes consideraciones: para los tweets compartidos el viernes, sábado o domingo se considera como día anterior el jueves y como día posterior el lunes de la siguiente semana; para los compartidos el lunes se considera como día posterior el martes y como día anterior el viernes de la semana previa. Toda la información se ha obtenido del código HTML de la página web empleando técnicas de web scraping [6] y las consultas se han realizado de forma concurrente empleando un hilo para cada petición. Preparación para la predicción Por último, y una vez completado el dataset con toda la información, se descartan todas las entradas que no contengan un único ticker, resultando en 1,427 muestras sobre las que actuarán los distintos clasificadores. Tabla II: Extracto del dataset completo ‘Text’ ‘Polarity’ ‘Emotion’ ‘Date’ El #Ibex35 reduce sus subidas del 1% ‘positivo’ ‘precaución’ Mon Jul 01 11:07:08 2019 al 0,3% #Preapertura: El #Ibex35, pendiente de EEUU para reforzar el 2% de ‘neutro’ ‘oportunidad’ Fri Jul 05 08:38:11 2019 subida semanal. Entramos en periodo estacional bajista ‘negativo’ ‘precaución’ Wed Oct 09 18:26:04 2019 en #SP500 ‘Precio día ‘Precio en el ‘Precio el día ‘Variación ‘Ticker’ ‘Estado’ anterior’ instante del tweet’ posterior’ precio’ IBEX35 9,198.80 9,264.60 9,281.50 65.8 ‘subida’ IBEX35 9,401.00 9,335.00 9,284.70 -66 ‘bajada’ SP500 2,893.06 2,919.40 2,938.13 26.34 ‘subida’ La divisa en la que se encuentran los valores sobre el precio del activo en los distintos instantes y su variación, mostrados en la Tabla II, es el dólar estadounidense (USD). B. Clasificación Un clasificador [7] es un algoritmo que ordena los datos en categorías o clases etiquetadas atendiendo a distintas reglas. Por lo tanto, los clasificadores son las herramientas empleadas para entrenar los modelos y los modelos el resultado final de la clasificación. A continuación, se detallan los clasificadores empleados para el entrenamiento: 7
Ada Boost (Adaptive Boosting) El objetivo de este algoritmo es convertir un weak learner, incapaz de realizar clasificaciones acertadas, en un strong learner. El funcionamiento se basa en realizar una predicción del conjunto de datos original, por parte de una secuencia de weak learners, y asignar un peso a cada observación. Si la predicción no es correcta se le asigna un peso mayor y se añade un nuevo weak learner. Este proceso se repite de forma iterativa. Decision Tree Este algoritmo pertenece a la familia de algoritmos de aprendizaje supervisado y se puede emplear tanto en problemas de regresión como en problemas de clasificación. El objetivo de este algoritmo es predecir el valor de la variable objetiva mediante un esquema de árbol en el que se selecciona un atributo como nodo raíz, empleando la ganancia de información o el coeficiente de Gini, que se dividirá en sucesivos subconjunto o ramas. Cada una de estas ramas debe contener el mismo valor para un mismo atributo. El cálculo finaliza cuando se encuentren nodos hoja en cada una de las ramas o hasta que se alcance el límite de expansión configurado, por lo tanto, un nodo hoja se alcanza cuando no es posible efectuar división alguna en ese nodo. Linear SVC Este método consiste en una implementación del algoritmo Support vector machine que establece dos categorías para la variable objetiva y construye el modelo que predice si las muestras que se están entrenando se incluyen en una u otra categoría. Concretamente, Linear SVC es un clasificador lineal cuyo objetivo es maximizar la distancia entre el punto más cercano de cada una de las categorías hasta el hiperplano, entendiendo como punto la representación gráfica, en un eje de coordenadas bidimensional, de una muestra clasificada en una de las dos categorías y como hiperplano la recta afín que actúa como frontera entre ambas categorías. Random Forest El algoritmo Random Forest es también un algoritmo de clasificación supervisado que crea un bosque con varios árboles de decisión. El funcionamiento se basa en crear un número determinado de árboles que proporcionarán, cada uno de ellos, una predicción para la variable objetiva. Debido a que existen varias predicciones, el algoritmo almacenará cada una de ellas y seleccionará la más votada como resultado final. SGD Clasificador lineal que emplea el optimizador Stochastic Gradient Descent que maximiza o minimiza la función de pérdidas del algoritmo de clasificación. El término estocástico hace referencia a la forma de selección de muestras para cada iteración, ya que esta se realiza de forma aleatoria en vez de emplear el conjunto de datos completo. Este algoritmo parte de un punto aleatorio en una función y desciende hasta el valor más bajo. Todos ellos pueden ajustarse para obtener mejores resultados. Los parámetros de ajuste reciben el nombre de hiperparámetros y permiten adaptar el clasificador al problema que se esté tratando. Algunos de los parámetros empleados cuyos valores han sido modificados respecto a la configuración por defecto, además de otros considerados de interés, se detallan a continuación: 8
n_estimators = 224 y learning_rate = 1.0 para el clasificador Ada Boost El primero se corresponde con el número máximo de weak learnes que se van a emplear hasta obtener un ajuste óptimo, si este se produce antes de que se hayan empleado los n_estimators el proceso finaliza. El segundo se corresponde con el peso asignado a cada clasificador y que contribuye al error estimado en cada iteración. Cuanto mayor sea este valor mayor será la contribución del clasificador. max_depth = 37, random_state = 0 y criterion = gini para el clasificador Decision Tree El hiperparámetro modificado ha sido max_depth que establece la profundidad máxima del árbol, entendiendo como profundidad el número de nodos que se han dividido partiendo de una de las ramas del nodo raíz. El segundo parámetro, criterion, se corresponde con la forma en la que se va a medir la calidad de una división, para ello se ha configurado el valor por defecto gini. C = 0.2, loss = squared_hinge, max_iter = 703, random_state = 0 y tol = 0.008 para el clasificador Linear SVC C es el coeficiente de regularización y se emplea para contrarrestar los efectos del ruido en los datos, max_iter se corresponde, simplemente, con el número máximo de iteraciones y tol con el criterio de fin de búsqueda cuando el valor buscado se encuentra en un margen tolerable. Por último, cabe mencionar la función de pérdidas squared_hinge [8] configurada por defecto para el hiperparámetro loss. Cuando el valor predicho coincide con el valor real la función de pérdidas es cero, de lo contrario aumenta cuadráticamente con el error atendiendo a la siguiente fórmula: ( , ̂) = ∑( (0,1 − ∙ ̂ )2 ) =0 Donde es un valor binario (+1 o -1) e ̂ el valor predicho. Esta función se emplea en problemas que implican decisiones binarias en las que el interés reside únicamente en maximizar el valor de accuracy. class_weight = balanced, bootstrap = False, max_depth = 150, criterion = gini, random_state = 0 y n_estimators = 400 para el clasificador Random Forest Los hiperparámetros max_depth y n_estimators, explicados previamente, se emplean para configurar los árboles de decisión que conforman el bosque. Por otra parte, class_weight asigna un peso a cada clase inversamente proporcional a la frecuencia de aparición y bootstrap establece la cantidad de datos utilizada para construir el árbol. l1_ratio = 0.4, n_iter_no_change = 20, max_iter = 100, penalty = elasticnet, random_state = 1 y loss = log para el clasificador SGD l1_ratio es el parámetro de mezcla Elastic Net, el cual únicamente tiene efecto cuando penalty, coeficiente de regularización, se configura como elasticnet, n_iter_no_change establece el límite de iteraciones en las que no se produce mejora antes de finalizar el ajuste y la función de pérdidas configurada para loss es una implementación de la regresión logística [9]. Este método se trata de una red neuronal con una sola neurona que aúna combinación lineal y aplicación de la función logística o sigmoidea que se puede expresar matemáticamente como: 1 ( ) = 1 + − 9
C. Entrenamiento El entrenamiento del modelo se lleva a cabo mediante validación cruzada de k-folds empleando alguno de los algoritmos descritos en la sección anterior. El concepto de validación cruzada de k-folds [10] se basa en dividir el conjunto de datos en subconjuntos separados de entrenamiento y prueba. El número de subconjuntos está determinado por el parámetro k, por lo tanto, se conformarán k subconjuntos compuestos, cada uno, por k-1 grupos de entrenamiento y un grupo de prueba. El modelo será entrenado por los k-1 subconjuntos de entrenamiento y validado por el subconjunto de prueba generando, cada subconjunto, una estimación que se emplea para elaborar el promedio cuando finalicen las k iteraciones. El valor de k seleccionado para este propósito ha sido k = 10. Conjunto de entrenamiento Conjunto de validación Iteración 1 Iteración 2 Iteración 3 Iteración 4 Iteración 5 Iteración 6 Iteración 7 Iteración 8 Iteración 9 Iteración 10 Figura 2:Proceso de validación cruzada con 10 folds D. Evaluación El desempeño o habilidad de un modelo se puede cuantificar y evaluar, para ello se han empleado las métricas precision, recall y accuracy. La métrica precision mide la calidad de la clasificación, indicando qué porcentaje de los tweets etiquetados como ‘oportunidad’ o ‘precaución’ lo son realmente, recall informa sobre la cantidad de tweets de cada categoría que el modelo ha identificado y accuracy se define como el número de predicciones acertadas del total de predicciones realizadas. Para el cálculo de las métricas se emplean las siguientes fórmulas: + = + + + 10
Para la etiqueta ‘oportunidad’: = = + + Para la etiqueta ‘precaución’: = = + + Donde VP se corresponde con verdaderos positivos, VN con verdaderos negativos, FP hace referencia a falsos positivos y FN a falsos negativos. 11
IV. Resultados El paso previo a la presentación de resultados será la descripción de cada una de las features seleccionadas para las pruebas. 1. ‘Text’: Esta feature contiene el texto del tweet. 2. ‘Polarity’: Contiene el resultado del análisis del sentimiento. Los posibles valores textuales que pueden aparecer en esta columna del dataset son ‘positivo’, ‘negativo’ o ‘neutro’. 3. ‘Variación precio’: Valor numérico que refleja la diferencia entre el valor del activo en el día de emisión del tweet y el día anterior. 4. ‘Estado’: Representa en formato textual la tendencia que sigue el precio del activo desde el día previo a la emisión hasta que es compartido, reflejando la ‘subida’, ‘bajada’ o mantenimiento del precio (‘mantuvo’). La primera de las features (‘Text’) es la única empleada en la primera de las pruebas, conformando el conjunto de features básico. El resto serán incorporadas en la segunda de las pruebas en la que se emplea el conjunto extendido. Los valores en las columnas precision y recall de las Tablas III y IV reflejan los resultados para la variable objetivo, ‘Emotion’, etiquetada como ‘oportunidad’ y como ‘precaución’. Tabla III: Conjunto de features básico Precision Recall Clasificador Features Accuracy ‘oportunidad’ ‘precaución’ ‘oportunidad’ ‘precaución’ Conjunto Ada Boost 64.50% 71.35% 65.00% 70.90% 68.25% básico Conjunto Decision Tree 51.07% 63.95% 66.71% 48.03% 56.41% básico Conjunto Linear SVC 70.92% 76.96% 72.03% 75.98% 74.21% básico Conjunto Random Forest 69.42% 69.80% 57.81% 79.29% 69.66% básico Conjunto SGD 73.96% 75.09% 67.03% 80.81% 74.63% básico En la Tabla III se presentan los resultados obtenidos para distintos clasificadores, empleando un conjunto de features compuesto por el texto del tweet, char grams y word grams. La agrupación a nivel de palabra se ha realizado individualmente (unigram) y en grupos de dos consecutivas (bigram). A nivel de carácter se ha empleado, únicamente, la agrupación individual. Los mejores resultados se han obtenido con los clasificadores Linear SVC y SGD. 12
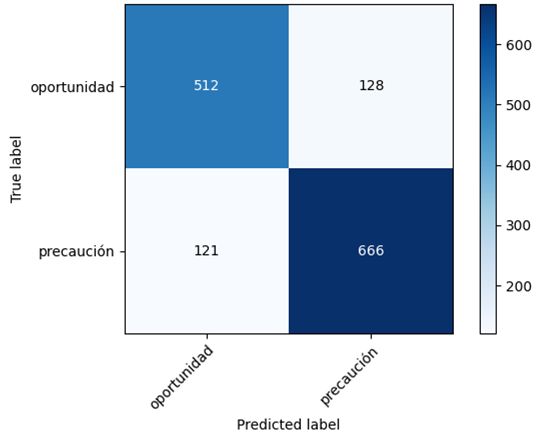
Tabla IV: Conjunto de features extendido Precision Recall Clasificador Features Accuracy ‘oportunidad’ ‘precaución’ ‘oportunidad’ ‘precaución’ Conjunto Ada Boost 77.33% 82.56% 78.91% 81.20% 80.17% extendido Conjunto Decision Tree 76.99% 82.19% 78.43% 80.94% 79.81% extendido Conjunto Linear SVC 80.88% 83.87% 80.00% 84.62% 82.55% extendido Conjunto Random Forest 77.85% 81.38% 76.87% 82.21% 79.82% extendido Conjunto SGD 75.45% 81.78% 78.28% 79.29% 78.84% extendido En la Tabla IV se presentan los resultados obtenidos para distintos clasificadores, añadiendo las columnas ‘Polarity’, ‘Variación precio’ y ‘Estado’ del dataset al conjunto de features anterior. Además, para Random Forest y SGD se han empleado los cuartiles para mapear los valores correspondientes a la columna ‘Variación precio’ a un número entero entre cero y tres, correspondiente a cada uno de los rangos creados. Con este nuevo conjunto de features el porcentaje de accuracy se incrementa entre un ~4 % (SGD) y un ~23 % (Decision tree) respecto a la configuración previa. Linear SVC se mantiene como el método de clasificación que proporciona mejores resultados, mientras que el clasificador SGD ofrece, en esta ocasión, el menor valor de accuracy. El resto de clasificadores evaluados proporcionan unos resultados similares. A continuación, se muestran las matrices de confusión de cada clasificador para cada una de las configuraciones, donde cada una de ellas representa el número de falsos negativos (cuadrante I), verdaderos positivos (cuadrante II), falsos positivos (cuadrante III) y verdaderos negativos (cuadrante IV) de un total de 1,427 muestras. Para cada clasificador se observa el incremento de verdaderos positivos y verdaderos negativos (con la consiguiente disminución de falsos positivos y falsos negativos) con la configuración extendida frente a la básica, salvo en el caso del SGD en el que se ve reducido el número de verdaderos negativos. Esta situación se debe a que la configuración extendida proporciona un mayor equilibrio entre la cantidad de tweets identificados de cada categoría. En el caso particular del SGD, la diferencia en el valor de recall entre una categoría y otra es del ~14% con la configuración básica mientras que con la extendida es de solo ~1% además, al haberse incrementado también el valor de precision, se obtiene como resultado el incremento en el valor de accuracy a pesar de verse reducidos los verdaderos negativos. 13
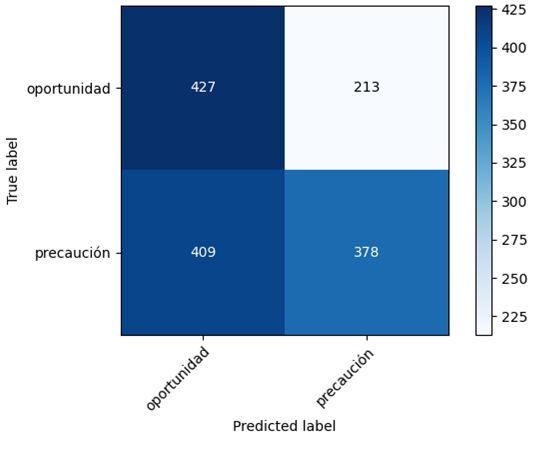
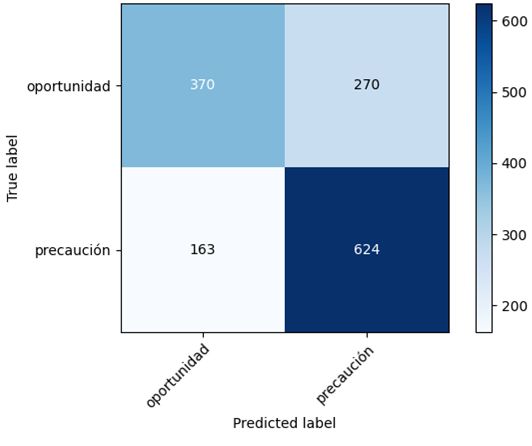
Figura 3: Matriz de confusión Ada Boost Figura 4: Matriz de confusión Ada Boost con el conjunto extendido con el conjunto básico Figura 5: Matriz de confusión Decision Figura 6: Matriz de confusión Decision Tree con el conjunto extendido Tree con el conjunto básico Figura 7: Matriz de confusión Linear Figura 8: Matriz de confusión Linear SVC con el conjunto extendido SVC con el conjunto básico 14
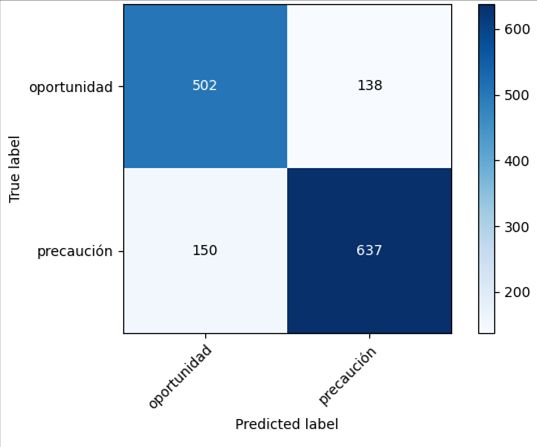
Figura 9: Matriz de confusión Random Figura 10: Matriz de confusión Random Forest con el conjunto extendido Forest con el conjunto básico Figura 11: Matriz de confusión SGD con Figura 12: Matriz de confusión SGD con el conjunto extendido el conjunto básico Las matrices de confusión [11] son herramientas útiles que complementan los valores de las métricas y permiten obtener un resumen de todas las observaciones que se han realizado, sobre todo cuando el número de clases a predecir es superior a dos. Con ellas es posible observar si las clases se están prediciendo equilibradamente o si existe cierta descompensación. 15
V. Conclusiones En este informe se ha recogido el procedimiento llevado a cabo y los resultados obtenidos por el sistema para la detección de tendencias bursátiles a partir de mensajes de texto, donde se ha concluido que el clasificador Linear SVC es el algoritmo que ha reflejado un mejor desempeño para el conjunto de pruebas realizado. En la primera de las pruebas ha compartido el mejor resultado y en la segunda se ha destacado definitivamente como la mejor opción. La elaboración de un dataset correcto y consistente, así como la elección del conjunto de features adecuado, es de vital importancia para que el algoritmo empleado pueda funcionar de forma óptima y arroje resultados más exactos. Por último, el empleo de sistemas automáticos de detección de tendencias supone una mayor sofisticación respecto a sistemas tradicionales y es en el ámbito financiero donde estos sistemas pueden proporcionar un potencial mayor. VI. Líneas futuras En este apartado se recogen aquellos aspectos que pueden resultar interesantes para su desarrollo en trabajos complementarios. La limitación computacional ha sido un factor decisivo a la hora de la realización de las evaluaciones de los distintos algoritmos debido al consumo de recursos y a los tiempos de entrenamiento. Con un soporte más potente podrían realizarse pruebas más exigentes, en un tiempo reducido y alcanzando mejores resultados. El siguiente aspecto a tratar consiste en una valoración para la posible implementación de un sistema similar en el ámbito de las apuestas en eventos deportivos, empleando el propio Twitter como fuente de información o valiéndose de la infinidad de datos y estadísticas oficiales disponibles. Cualquiera de los clasificadores empleado en este estudio podría aplicarse a problemas similares con un dataset distinto. Por último, se propone como una vía de desarrollo el enfoque del sistema estudiado hacia la detección de otro tipo de tendencias, en este caso relacionadas con el acoso escolar, enfermedades mentales como la depresión o trastornos alimenticios. Este último punto se fundamenta en que las redes sociales son, definitivamente, un medio eficaz para la detección de las situaciones citadas. El análisis se llevaría a cabo de forma similar a la identificación de la positividad o negatividad de una inversión, realizando el NLP y obteniendo un análisis del sentimiento complementándolo con un procesado de imágenes, ya que un tweet o una publicación en alguna otra red social no siempre está compuesta únicamente por texto. Todo este análisis se puede realizar mediante modelos de machine learning que emplean los algoritmos evaluados en el presente trabajo, además de otros modelos como las redes neuronales para el procesamiento de las imágenes. 16
VII. Bibliografía [1] “What is machine learning?”, ibm.com, Julio 2021. [Online]. Available: https://www.ibm.com/cloud/learn/machine-learning [2] K.R. Chowdhary, “Natural Language Processing”, 2012 [3] Saif M. Mohammad, Felipe Bravo-Marquez. “Emotion Intensities in Tweets”, arXiv:1708.03696v1 [cs.CL], 2017 [4] Francisco de Arriba-Pérez, Silvia García-Méndez, José Ángel Regueiro-Janeiro, and Francisco J. González-Castaño, “Detection of Financial Opportunities in Micro-Blogging Data With a Stacked Classification System”, IEEE Access, vol 8, 2020 [5] Madhuri Thakur, “Ticker symbol”, wallstreetmojo.com, Julio 2021. [Online]. Available: https://www.wallstreetmojo.com/ticker-symbol/ [6] “What is Web Scraping and what is it used for?”, parsehub.com, Julio 2021. [Online]. Available: https://www.parsehub.com/blog/what-is-web-scraping/ [7] “Classifiers”, scikit-learn.org, Julio 2021. [Online]. Available: https://scikit- learn.org/stable/search.html?q=classifier [8] “Squared hinge”, peltarion.com, Julio 2021. [Online]. Available: https://peltarion.com/knowledge- center/documentation/modeling-view/build-an-ai-model/loss-functions/squared-hinge [9] Jill C. Stoltzfus, “Logistic Regression: A Brief Primer”, Academic Emergency Medicine, 2011. [10] Rahil Shaikh, “Cross Validation Explained: Evaluating estimator performance”, towardsdatascience.com, Julio 2021. [Online]. Available: https://towardsdatascience.com/cross-validation- explained-evaluating-estimator-performance-e51e5430ff85 [11] Jason Brownlee, “What is a Confusion Matrix in Machine Learning”, machinelearningmastery.com, Julio 2021. [Online]. Available: https://machinelearningmastery.com/confusion-matrix-machine-learning/ [12] “¿Qué es Big Data?”, ibm.com, Julio 2021. [Online]. Available: https://www.ibm.com/mx- es/analytics/hadoop/big-data-analytics [13] “Could AI Fully Replace Human Financial Traders?”, medium.datadriveninvestor.com, Julio 2021. [Online]. Available: https://medium.datadriveninvestor.com/could-ai-fully-replace-human-financial- traders-d830fe48201d [14] Tiago Colliri & Liang Zhao, “Stock market trend detection and automatic decision-making through a network-based classification model”, Julio 2021. [Online]. Available: https://link.springer.com/article/10.1007/s11047-020-09829-9 [15] Sai Vikram Kolasani1, Rida Assaf2, “Predicting Stock Movement Using Sentiment Analysis of Twitter Feed with Neural Networks”, vol 8, 2020 [16] Xiongwen Pang, Yanqiang Zhou, Pan Wang, Weiwei Lin & Victor Chang, “An innovative neural network approach for stock market prediction”, 12-Jan-2018. [17] Michał Skuza, Andrzej Romanowski, “Sentiment analysis of Twitter data within big data distributed environment for stock prediction”, 13-16 Sep-2015, IEEE Xplore 17
[18] “What is MapReduce?”, talend.com, Julio 2021. [Online]. Available: https://www.talend.com/resources/what-is-mapreduce/ [19] A. Balahur and J. M. Perea-Ortega, “Sentiment analysis system adaptation for multilingual processing: The case of tweets,” Inf. Process. Manage., vol. 51, no. 4, pp. 547–556, Jul. 2015 18
VIII. Anexos A. Estado del arte La detección de tendencias bursátiles puede llevarse a cabo dos formas: Especulación o inversión. Esta actividad se ha llevado a cabo tradicionalmente por un individuo denominado trader, encargado de identificar las oportunidades de inversión basándose en su conocimiento y experiencia mediante la aplicación de una lógica matemática. El trader se mantiene actualizado e informado con las noticias y eventos diarios, además de conocer al detalle la agenda económica; su objetivo es buscar probabilidades de éxito y fallo, medir la pérdida máxima esperada y buscar un equilibrio óptimo entre riesgo y beneficio. Debido a la limitada cantidad de información que puede manejar una persona, la difícil tarea de predicción a la que se enfrenta y los métodos de cálculo menos sofisticados que emplea, obtiene como resultado un porcentaje de acierto discreto. Detección automática mediante modelos de machine learning. El auge de la inteligencia artificial propiciado por el desarrollo creciente de Big Data [12], la mejora de las capacidades de cómputo de las máquinas actuales y el empleo de técnicas sofisticadas sitúan a los sistemas de detección automática en un nivel superior al método tradicional. Concretamente, el sector financiero es uno de los sectores en los que este auge tiene un mayor impacto y potencial futuro. Actualmente, diversos estudios proponen soluciones para la detección automática, sustituyendo al individuo [13] por un sistema capaz de identificar tendencias con un porcentaje de acierto superior. Estos sistemas emplean algoritmos diversos y complejos que realizan tareas de clasificación basándose en experiencias previas procedentes de vastas cantidades de datos reales a partir de los cuales obtienen los patrones de inversión. Cuanto mayor sea la cantidad de información analizada más exactos serán los resultados. La inclusión de sistemas automáticos de detección de tendencias bursátiles para el mercado de valores genera cierta controversia debido a hipótesis [14] que sostienen la existencia de aleatoriedad en la evolución de los precios. Como contrapunto existen otras que defienden la inclusión de estos sistemas considerando que es posible realizar pronósticos perfectamente basándose en la información histórica de los datos del mercado. A continuación, se enumeran artículos de temática similar con los que establecer el estado del arte: Predicting Stock Movement Using Sentiment Analysis of Twitter Feed with Neural Networks (2020) [15]: En este artículo se emplean también las redes sociales y noticias financieras como fuente de información. Para la realización de las predicciones se efectúa un análisis del sentimiento empleando Support Vector Machines y, posteriormente, se emplean dos modelos, Boosted Regression Trees y Multilayer Perceptron Neural Networks, para la prediccioón del precio de cierre de AAPL y DJIA. An innovative neural network approach for stock market prediction (2018) [16]: Propone un sistema de predicción de valores empleando una red neuronal. Como fuente de información se vale de los datos en vivo del mercado para el análisis en tiempo real y análisis off-line. 19
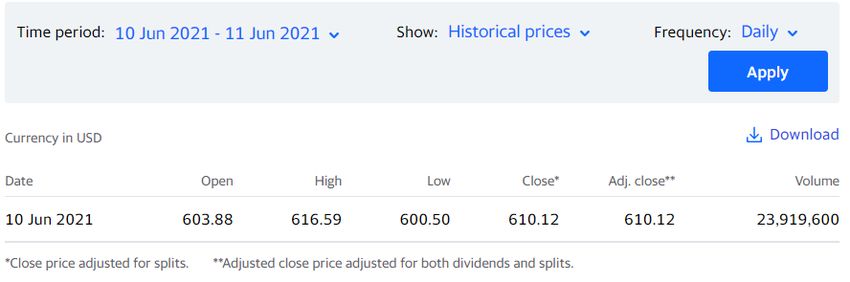
Sentiment analysis of Twitter data within big data distributed environment for stock prediction (2015) [17]: Describe un sistema de predicción basado en el análisis de los datos procedentes de las redes sociales, mediante el análisis del sentimiento empleando machine learning y Map Reduce [18] para el cálculo en un entorno distribuido. Sentiment analysis system adaptation for multilingual processing: The case of tweets (2015) [19]: Este documento propone una solución para la creación de un sistema de análisis del sentimiento multilingüe. En él se evidencia que el uso de datos multilingües contribuye a una clasificación más exacta del sentimiento. La mayor parte de los artículos coinciden en que las redes sociales son la mejor fuente de información y establecen la plataforma Twitter como la preferida para el ámbito financiero. Los valores de accuracy reflejan que el análisis del sentimiento previo es fundamental para la obtención de valores más exactos. En los artículos seleccionados los sistemas reducen su ámbito de aplicación a tickers o mercados concretos. B. Procedimiento para la consulta y extracción de los precios del activo El objetivo de este anexo es ampliar la explicación proporcionada en el apartado Elaboración y preparación del dataset referente al proceso de obtención de los precios del activo financiero mediante consultas GET y web scraping. El método GET pertenece al protocolo HTTP y se emplea para realizar peticiones de información a una determinada fuente. La particularidad de este método se fundamenta en enviar los parámetros de consulta en la propia query string de la URL, a simple vista, por lo que no se recomienda su uso cuando los datos que se están tratando son sensibles (por ejemplo, contraseñas). Accediendo a la siguiente URL https://uk.finance.yahoo.com/quote/TSLA/history?period1=1623283200&period2=1623369600&inter val=1d&filter=history&frequency=1d&includeAdjustedClose=true, desde un navegador, se obtienen los siguientes datos: Figura 13: Información sobre los precios del activo TSLA (Tesla, Inc.) Realizar esta maniobra manualmente resulta lento y tedioso por lo que se emplea la librería requests para Python que permite realizar consultas HTTP de forma sencilla y automática; de la URL anterior es 20
posible deducir que los parámetros period1 y period2 de la query string se corresponden con una marca temporal que se puede obtener convirtiendo una cadena en formato fecha en un número entero con el método timestamp () de la librería datetime. De forma general, para cualquier ticker e intervalo de fechas enviados como parámetro, se realiza la consulta automática de la siguiente manera: import requests as req # URL a la que se envía la petición url ='https://uk.finance.yahoo.com/quote/'+ticker+'/history?period1='+str(before)+ '&period2='+str(after)+'&interval=1d&filter=history&frequency=1d&includeAdjustedCl ose=true' # La página HTML obtenida como respuesta se almacena en una variable para su posterior procesado html = req.get(url) Existen algunos tickers con los que no es posible acceder a la información histórica incluyendo el nombre literal, por lo que se emplean otros nombres referentes al mismo ticker, pero con los que sí se consigue obtener la información. Estos son los siguientes: Tabla V: Relación entre el ticker original y el necesario para la consulta ticker original ticker empleado SPX o SP500 %5EGSPC IBEX35 %5EIBEX NASDAQ %5ENDX CAC40 %5EFCHI VIX %5EVIX NZDUSD NZDUSD%3DX USDCAD CAD%3DX USDJPY JPY%3DX USDMXN MXN%3DX ITX ITX.MC CIE CIE.MC XAU XAU.TO REP REP.MC COME COME.BA Una vez realizada la consulta es necesario procesar el contenido HTML de la página para extraer la información y esta se obtiene mediante web scraping, empleando algoritmos de análisis y extracción de datos. La librería empleada para crear y recorrer el árbol DOM (Document Object Model) es BeautifulSoup, gracias a ella es posible navegar por los diferentes nodos y extraer el contenido de interés. A continuación, se muestra un extracto del código fuente de la página HTML con la información sobre los precios (en único día) y un fragmento del programa empleado para extraerlos (muestra la forma de extraer los precios cuando el intervalo de fechas cubre los tres días: instante del tweet, día anterior y día posterior). 21
10 Jun 2021
603.88
616.59
600.50
610.12
610.12
23,919,600
from bs4 import BeautifulSoup
bs = BeautifulSoup(html.text,'html.parser')
try:
# Se recorre el nodo tbody y se obtiene el contenido de las etiquetas span
que se corresponden con el precio en los distintos días.
span = bs.tbody.find_all('span')
price_after = span[4].contents[0]
price_now = span[11].contents[0]
price_before = span[18].contents[0]
except AttributeError:
print(str(position)+' '+ticker+' AttributeError')
return
except IndexError:
print(str(position)+' '+ticker+' IndexError')
return
22También puede leer

















































