Disección y análisis del tráfico de red de Amazon Alexa - Memoria - GRADO EN INGENIERÍA INFORMÁTICA
←
→
Transcripción del contenido de la página
Si su navegador no muestra la página correctamente, lea el contenido de la página a continuación

GRADO EN INGENIERÍA INFORMÁTICA
ESPECIALIDAD EN TECNOLOGÍAS DE LA INFORMACIÓN
Disección y análisis del tráfico de
red de Amazon Alexa
Memoria
Autor: Rubén Barceló Armada
Director: Pere Barlet Ros
Fecha: 21 de abril de 2021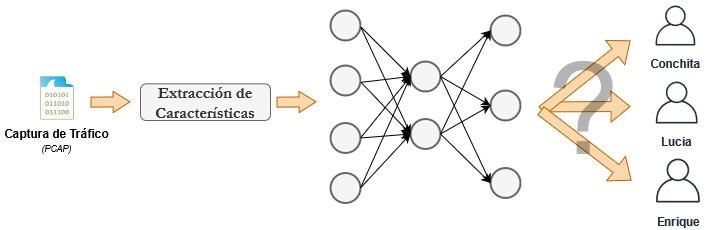
Resumen
El número de dispositivos que conforman el Internet de las Cosas (IoT) no ha
dejado de aumentar año tras año, incluyendo los altavoces inteligentes. En
particular, estos dispositivos han adquirido una gran popularidad en todo el
mundo y se estima que este año habrá 83,1 millones de usuarios con un altavoz
inteligente. Sin embargo, también se ha generado una gran preocupación sobre
cómo pueden llegar a afectar a la privacidad y seguridad de los usuarios. Por
ello, se vuelve imprescindible realizar estudios que arrojen luz sobre esta
incógnita.
Dicho planteamiento es el que se desarrolla en el presente proyecto.
Concretamente, se estudia la posibilidad de detectar la persona que ha ejecutado
un comando de voz a través del análisis del tráfico de red, lo que permitiría
conocer información crítica de los usuarios.
1
Resum
El nombre de dispositius que conformen la Internet de les Coses (IoT) no ha
deixat d'augmentar any rere any, incloent-hi els altaveus intel·ligents. En
particular, aquests dispositius han adquirit una gran popularitat a tot el món i
s'estima que enguany hi haurà 83,1 milions d'usuaris amb un altaveu intel·ligent.
No obstant això, també s'ha generat una gran preocupació sobre com poden
arribar a afectar a la privacitat i seguretat dels usuaris. Per això, es torna
imprescindible realitzar estudis que llancin llum sobre aquesta incògnita.
Aquest plantejament és el que es desenvolupa en el present projecte.
Concretament, s'estudia la possibilitat de detectar l’usuari que ha emès una ordre
de veu a través de l'anàlisi del trànsit de xarxa, la qual cosa permetria conèixer
informació crítica dels usuaris.
2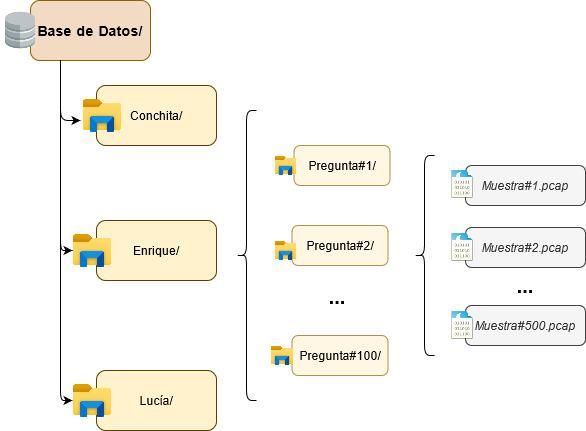
Abstract
The number of devices that make up the Internet of Things (IoT) has been
increasing every year, including smart speakers. These devices have become
very popular around the world, and it is estimated that this year there will be 83.1
million users with a smart speaker. However, there has also been great concern
about how they can affect the privacy and security of users. Therefore, it is
essential to carry out studies that shed light on this unknown.
This approach is the one developed in this project. Specifically, the possibility
to detect the user who has issued a voice command is being studied through the
analysis of network traffic, which would allow knowing critical information
about users.
3
Agradecimientos
Me gustaría agradecer a toda la gente, que directa o indirectamente, se han
implicado en este Trabajo de Fin de Grado.
En primer lugar, a mi director de proyecto (Pere Barlet Ros) y a Ismael Castell
Uroz, por guiarme y ayudarme en la elaboración de este proyecto.
En segundo lugar, me gustaría hacer una mención especial a Guillermo
Bernández Gil que me ayudó a resolver las dudas que me surgieron durante el
desarrollo de las redes neuronales.
Por último, me gustaría dar las gracias a mi familia y pareja por haberme
ayudado, apoyado y motivado en los momentos más difíciles durante todo el
grado.
4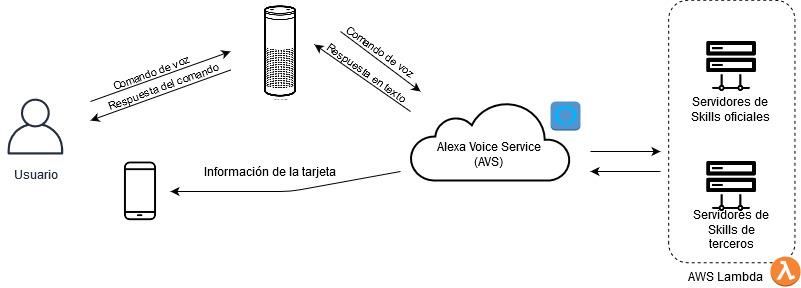
Índice
1 | Introducción y contextualización ................................................................................ 7
1.1 Introducción .......................................................................................................... 7
1.2 Identificación del problema .................................................................................. 8
1.3 Conceptos ............................................................................................................. 8
1.4 Actores implicados ............................................................................................. 10
2 | Justificación .............................................................................................................. 12
2.1 Soluciones existentes .......................................................................................... 12
2.2 Justificación proyecto ......................................................................................... 13
3 | Alcance ..................................................................................................................... 14
3.1 Objetivo general ................................................................................................. 14
3.2 Subobjetivos ....................................................................................................... 14
3.3 Requerimientos no funcionales .......................................................................... 15
3.4 Posibles obstáculos y riesgos.............................................................................. 16
4 | Metodología .............................................................................................................. 17
4.1 Método de desarrollo .......................................................................................... 17
4.2 Métodos de validación ........................................................................................ 17
4.3 Herramientas de desarrollo ................................................................................. 18
5 | Planificación temporal .............................................................................................. 19
5.1 Listado de tareas ................................................................................................. 19
5.2 Recursos ............................................................................................................. 21
5.3 Planificación inicial ............................................................................................ 22
5.4 Diagrama de Gantt inicial ................................................................................... 23
5.5 Gestión del riesgo ............................................................................................... 24
5.6 Planificación final ............................................................................................... 24
5.7 Diagrama de Gantt final ..................................................................................... 27
6 | Gestión económica .................................................................................................... 28
6.1 Costes de personal .............................................................................................. 28
6.2 Costes genéricos ................................................................................................. 29
6.3 Contingencia ....................................................................................................... 30
6.4 Imprevistos ......................................................................................................... 30
6.5 Coste inicial total ................................................................................................ 31
6.6 Coste final ........................................................................................................... 31
6.7 Control de gestión............................................................................................... 33
7 | Informe de sostenibilidad ......................................................................................... 34
5
7.1 Autoevaluación ................................................................................................... 34
7.2 Dimensión económica ........................................................................................ 34
7.3 Dimensión ambiental .......................................................................................... 34
7.4 Dimensión social ................................................................................................ 35
8 | Arquitectura y funcionamiento ................................................................................. 36
8.1 Arquitectura Amazon Alexa ............................................................................... 36
8.2 Análisis del tráfico .............................................................................................. 37
8.3 Características del tráfico ................................................................................... 38
9 | Base de datos ............................................................................................................ 40
9.1 Objetivo .............................................................................................................. 40
9.2 Preparación previa .............................................................................................. 40
9.3 Extracción de preguntas...................................................................................... 41
9.4 Obtención de datos ............................................................................................. 41
9.5 Datos obtenidos .................................................................................................. 43
9.6 Procesamiento de los datos ................................................................................. 46
10 | Desarrollo de la red neuronal .................................................................................. 49
10.1 Objetivo ............................................................................................................ 49
10.2 Limitaciones ..................................................................................................... 49
10.3 Redes neuronales artificiales ............................................................................ 50
10.4 Perceptrón multicapa - MLP............................................................................. 52
10.5 Implementación de la red neuronal .................................................................. 54
10.6 Evaluación ........................................................................................................ 58
10.7 Alternativas ....................................................................................................... 60
11 | Conclusión .............................................................................................................. 66
11.1 Futuras líneas de investigación ......................................................................... 66
12 | Índice de Figuras ..................................................................................................... 68
13 | Índice de Tablas ...................................................................................................... 69
14 | Referencias ............................................................................................................. 70
15 | Anexo 1 - Preguntas ................................................................................................ 72
16 | Anexo 2 – Arquitectura redes neuronales ............................................................... 75
6
1 | Introducción y contextualización
1.1 Introducción
Con la llegada de la Era Digital y la incursión de las nuevas tecnologías e Internet en
la vida de las personas, la sociedad se vio inmersa en una revolución que provocó cambios
fundamentales en las prácticas económicas, los medios de comunicación y el
comportamiento social, entre muchos otros aspectos.
A raíz de estas innovaciones tecnológicas y la implementación de las Tecnologías de la
Información y la Comunicación (TIC), se desarrolló la llamada sociedad de la
información. Esta destaca por la forma innovadora en la que se accede a la información,
cómo interactúan los seres humanos entre ellos y los cambios producidos en el día a día
de las personas.
Del mismo modo, en los últimos años ha comenzado una segunda revolución digital
impulsada por la creación de los dispositivos que conforman el Internet de las Cosas
(Internet of Things, IoT). Es decir, objetos cotidianos son transformados en dispositivos
inteligentes conectados a la red permitiendo automatizar tareas que debía realizar
anteriormente el ser humano. Por ejemplo: vehículos, electrodomésticos, dispositivos
mecánicos, o simplemente objetos tales como calzado, muebles, entre otros.
Además, tal y como se muestra en la Figura 1, la tendencia de crecimiento de los
dispositivos IoT es exponencial y surgió la necesidad de encontrar un método que
permitiera mantener el control de todos ellos desde un único punto centralizado.
Para cubrir este cometido, se desarrollaron los llamados asistentes virtuales de compañías
como Amazon (Alexa) o Google (Google Assistant); así como los altavoces inteligentes
que integraban estas inteligencias artificiales.
Figura 1: Número de dispositivos conectados. Fuente: incibe-cert.es
71.2 Identificación del problema
Tal como se ha expuesto anteriormente, el número de dispositivos inteligentes no ha
dejado de aumentar año tras año, incluyendo los altavoces inteligentes.
Con relación a estos dispositivos, la popularidad ha aumentado considerablemente y se
estima que habrá 83,1 millones de usuarios con un altavoz inteligente este año. En este
mercado destaca Amazon que tiene una posición dominante con aproximadamente el
70% del total de usuarios de estos dispositivos en EE. UU.[1].
Sin embargo, también han generado una gran preocupación en cuanto a la seguridad y
privacidad de los usuarios[2]. Al tratarse de altavoces inteligentes, ofrecen a los usuarios
la posibilidad de realizar tareas utilizando únicamente comandos por voz. No obstante,
esto implica que es necesario que los dispositivos escuchen continuamente con el objetivo
de detectar la palabra de activación (por ejemplo, “Alexa”) para responder a las órdenes
del usuario.
Además, las interacciones que los usuarios pueden tener con el asistente virtual van desde
tareas simples como preguntar por las condiciones meteorológicas o reproducir música,
hasta tareas que pueden revelar información privada sobre el usuario. Por ejemplo, si se
realiza la compra de un medicamento se podría conocer detalles sobre su salud o incluso
sobre su situación financiera.
Debido a la problemática que se presenta, es de gran interés analizar y comprobar la
posible existencia de fugas de privacidad que comprometan la seguridad del usuario.
1.3 Conceptos
A continuación, se definen los conceptos más relevantes en este proyecto:
1.3.1 Asistente virtual
Un asistente virtual (Intelligent Virtual Assistant, IVA) es un agente tipo software que
permite realizar tareas y ofrecer servicios a un individuo. Estos agentes nacen con el
objetivo de ayudar a los usuarios automatizando y llevando a cabo distintas tareas
cotidianas que anteriormente tenían que hacer las personas manualmente; tal y como son:
apagar las luces, obtener información sobre las condiciones meteorológicas, ajustar el
termostato o controlar otros dispositivos domésticos inteligentes.
Además, se pretende que la interacción hombre-máquina sea la menor posible. Por esta
razón, las órdenes se realizan utilizando únicamente comandos por voz, lo que facilita
que los IVA pueda integrarse en altavoces inteligentes, teléfonos móviles, coches, entre
otros.
Los asistentes virtuales también se caracterizan porque pueden llegar a comprender
órdenes para las que no se habían programado explícitamente mediante el reconocimiento
automático del habla (Automatic Speech Recognition, ASR) y la comprensión natural del
8lenguaje (Natural Language Understanding, NLU). Además, con la inclusión del
Machine Learning se consigue un servicio más inteligente, dotándole de la capacidad de
desarrollar un vocabulario más amplio y dar respuestas más precisas a las consultas.
Finalmente, para un rendimiento óptimo, una gestión de datos eficiente y no necesitar una
gran potencia de procesamiento, los IVA más utilizados generalmente operan basándose
en la arquitectura de computación en la nube.
En la Tabla 1 se puede encontrar algunos ejemplos de asistentes virtuales inteligentes.
Fabricante Asistente Virtual Integración en dispositivos
Amazon Alexa Echo, Dot, Fire Tablet
Apple Siri iPhone, iPad
Google Google Assistant Google Nest, móviles con Android
Microsoft Cortana Ordenadores con Windows
Tabla 1: Asistentes virtuales.
1.3.2 Altavoz inteligente
Los altavoces inteligentes son dispositivos IoT que integran un asistente virtual
inteligente y micrófonos para que los usuarios interactúen con el IVA a través de
comandos por voz. Comúnmente se conectan a una red del hogar para interactuar y poder
gestionar otros dispositivos IoT que se encuentren también conectados.
Por ejemplo, se encuentra la gama de dispositivos Echo que integran el asistente Amazon
Alexa.
1.3.3 Base de datos
Una base de datos se puede definir como un conjunto de datos interrelacionados entre
sí que pertenecen al mismo contexto. Adicionalmente, esta se encuentra organizada de tal
manera que permite posteriormente al usuario añadir nuevos datos, realizar búsquedas y
consultas, entre otros.
1.3.4 Aprendizaje profundo
El aprendizaje profundo o Deep Learning es uno de los métodos de aprendizaje de la
Inteligencia Artificial. Engloba un conjunto de algoritmos que permiten procesar grandes
cantidades de datos mediante una estructura de redes neuronales artificiales inspiradas en
el cerebro humano. Con ello, se consigue que los ordenadores aprendan de forma
autónoma para realizar predicciones a partir de ejemplos previos.
1.3.5 Ataque huella digital
Los ataques basados en huellas digitales (fingerprinting) se centran en buscar patrones
en el tráfico de red que permitan conocer las acciones que está llevando a cabo la víctima.
9Comúnmente estos ataques se utilizan para detectar qué sitio web visita un usuario
(website fingerprinting) extrayendo las características del tráfico oportunas para
posteriormente, implementar diferentes algoritmos de Machine Learning y Deep
Learning [3]. Por ejemplo, si los paquetes de datos que se están recibiendo son muy
grandes y el intervalo de tiempo entre cada uno es demasiado alto, puede indicar que el
usuario está en alguna página web de streaming. En resumen, en base a unos patrones, se
puede llegar a entender que está realizando el usuario.
En el desarrollo de este proyecto, se adaptará este ataque para buscar patrones en el tráfico
que genera el Amazon Echo al recibir diferentes comandos de voz, teniendo en cuenta
que cada orden y su respuesta, aunque estén cifrados, tienen un patrón de tráfico único a
través de la longitud de cada uno de los paquetes, la dirección, el orden, entre otros.
1.4 Actores implicados
En este apartado se identifican y describen los stakeholders, es decir, aquellas personas
que directa o indirectamente pueden verse afectados por los resultados y conclusiones
que se obtengan en este proyecto.
▪ Investigadores: las bases de datos son uno de los elementos fundamentales a la
hora de realizar una investigación. Por consiguiente, cualquier estudio que analice
el altavoz inteligente de Amazon a partir del tráfico de red se podría beneficiar del
conjunto de datos generado en este proyecto.
▪ Amazon Inc: compañía que ha desarrollado el dispositivo objeto de estudio en
este proyecto. Al final de la investigación, si los resultados concluyen que existen
fallos que pueden llegar a comprometer la privacidad de los usuarios, se podrían
beneficiar positivamente implementando las actualizaciones necesarias para
evitar un ataque de estas características, evitando que sea posible extraer
información crítica de los usuarios.
▪ Usuarios: una de las principales preocupaciones que tienen las personas a la hora
de comprar el altavoz inteligente de Amazon es si este dispositivo se encuentra
siempre escuchando y qué información privada pueden llegar a obtener de ellos
[2]. Estas preocupaciones surgen porque son esencialmente micrófonos
conectados a Internet que escucha constantemente a los usuarios esperando la
palabra de activación. Este proyecto pretende investigar si es posible que existan
fugas de privacidad, permitiendo a atacantes que accedan a nuestra red obtener
información de los usuarios, comprometiendo su seguridad.
▪ Autor del proyecto: actor encargado de desarrollar el proyecto como parte del
Trabajo de Fin de Grado. En este rol se encuentra el alumno Rubén Barceló
Armada.
10▪ Director del proyecto: profesor encargado de orientar al alumno realizando un
seguimiento del proyecto. En este rol se encuentra el profesor Pere Barlet-Ros,
miembro del Departamento de Arquitectura de Computadores.
112 | Justificación
En este proyecto se pretende realizar una investigación sobre el nivel de privacidad
que ofrece el altavoz inteligente Amazon Echo. Concretamente, se analizará la
posibilidad de detectar la persona que ha ejecutado un comando de voz mediante el
análisis del tráfico de red. Para llevar a cabo este estudio se desarrollará una base de datos
con capturas del tráfico de red que genera el dispositivo cuando recibe una orden.
2.1 Soluciones existentes
En la actualidad existen varios artículos académicos que exponen el funcionamiento
interno de los altavoces inteligentes de Amazon, así como diferentes análisis del nivel de
seguridad y privacidad que ofrecen. No obstante, cabe destacar que la mayoría de los
estudios se realizaron con la 2ª generación del dispositivo. Por ello, en este proyecto se
va a utilizar un Amazon Echo Dot de 3ª generación [4].
Hay que tener en cuenta que este dispositivo trabaja con información sensible de los
usuarios (datos financieros, privados, entre otros). Por ello, se han publicado una gran
variedad de artículos que se centran en realizar un análisis de los vectores de ataque y las
vulnerabilidades que existen, así como las consecuencias que pueden llegar a tener.
Por ejemplo, en [5] y [6] se llevan a cabo diferentes pruebas para comprometer la
seguridad del altavoz inteligente, centrándose en ataques basados en el sonido, la red, la
página web de Alexa o skills (aplicaciones de terceros). No obstante, ambos concluyen
que la política de privacidad y seguridad que Amazon presenta en el documento [7] es
totalmente fiable, y efectivamente, se toman muy en serio su compromiso con la
seguridad de los datos de sus usuarios.
Por otro lado, existen varios artículos que realizan un análisis en profundidad del tráfico
de red que produce el dispositivo Amazon Echo. Por ejemplo, en [8] se realizan dos
hallazgos importantes. En primer lugar, se encuentra la posibilidad de ejecutar comandos
usando un recordatorio. En segundo lugar, se detecta la posibilidad de conseguir datos
sobre el historial de uso de Alexa que pueden ser utilizados para extrapolar patrones útiles
sobre los marcos de tiempo cuando los usuarios están lejos del dispositivo.
En el artículo [9] se plantea un estudio sobre la clasificación del tráfico encriptado que
genera el dispositivo con el objetivo de inferir que comando por voz ha ejecutado el
usuario. Para ello, se genera una aplicación aprovechando algoritmos Machine Learning
que permiten encontrar patrones y relacionar el tráfico con el comando de voz
correspondiente. No obstante, la tasa de aciertos que obtienen es únicamente del 33,8%.
Finalmente, en [10] se continúa desarrollando y mejorando la solución propuesta en el
anterior artículo. Sin embargo, en este caso se implementa un modelo utilizando Deep
Learning, con el que se obtiene un incremento notable de la tasa de acierto hasta un 91%.
12Esto indica que efectivamente existen fugas de privacidad que un usuario podría llegar a
utilizar malintencionadamente para conocer la pregunta que ejecuta un usuario.
2.2 Justificación proyecto
La intención de este proyecto es continuar con la investigación propuesta en los
artículos [9] y [10] planteándose, a su vez, nuevos objetivos. En concreto, se pretende
profundizar en otras fugas de privacidad que puedan existir a partir del análisis del tráfico
de red que genera el dispositivo Amazon Echo.
Por lo tanto, en este estudio se utilizará como base la técnica que se implementó en los
artículos citados anteriormente, donde se desarrolla un ataque basado en huellas digitales
para reconocer los comandos de voz utilizados por un usuario. No obstante, el objetivo
de este proyecto es ir un paso más allá y analizar el tráfico de red para encontrar patrones
que permitan detectar la persona que ha pronunciado un comando de voz.
Con esta investigación, se pretende comprobar si es posible obtener, a partir del tráfico
encriptado, información crítica del usuario. Puesto que, si externamente se puede
reconocer la persona que está utilizando el dispositivo, podría suponer un peligro para la
seguridad de los usuarios.
Además, para desarrollar este proyecto es fundamental utilizar una base de datos formada
por capturas de tráfico del altavoz inteligente. No obstante, a pesar de haberse realizado
diversos estudios relacionados con el tráfico de este dispositivo, no se ha encontrado una
base de datos disponible de forma pública. Por consiguiente, en este proyecto se generará
una base de datos. Dado que la recolección de datos es un proceso muy costoso, este
dataset también permitirá ayudar a otros equipos de investigación que quieran realizar un
estudio relacionado con este dispositivo; al tener a su disposición una base de datos
extensa y completamente documentada.
En definitiva, este proyecto pretende dar un paso más allá en la investigación sobre el
nivel de privacidad y seguridad que ofrecen los altavoces inteligentes de Amazon.
133 | Alcance
Una vez contextualizada y justificada la elección del proyecto, se definirán los
objetivos que nos permitirán resolver el problema planteado anteriormente. Asimismo, se
definirán los posibles obstáculos y riesgos que pueden surgir, afectando negativamente al
desarrollo de la investigación.
3.1 Objetivo general
El objetivo de este trabajo consiste en realizar un estudio sobre las posibles fugas de
privacidad que pueden existir en el altavoz inteligente Amazon Echo. Para ello, se
implementará un ataque basado en huellas digitales con la finalidad de detectar patrones
en el tráfico de red que permitan diferenciar al usuario que emite una orden o pregunta al
dispositivo.
Asimismo, para llevar a cabo este estudio se desarrolla un conjunto de herramientas que
permita crear una base de datos con muestras del tráfico de red. Concretamente, se desea
obtener capturas del tráfico que genera el dispositivo Amazon Echo cuando recibe un
comando de voz.
3.2 Subobjetivos
Para alcanzar el objetivo planteado anteriormente, se deben resolver los siguientes
subobjetivos:
1. Comprender la arquitectura de red de Amazon Alexa: estudiar el rol que tiene
cada uno de los componentes que conforman el ecosistema de Alexa (Usuario,
Amazon Echo, Alexa Voice Services y Servidores de Skills) así como el proceso
que se lleva a cabo cuando un usuario activa el asistente.
2. Analizar el tráfico que genera el dispositivo: comprender con quién interactúa,
qué tipo de protocolos utiliza y la relación que existe entre el tráfico que se genera
con el comando por voz que se ha ejecutado.
3. Desarrollar aplicación para recolectar datos: implementar una herramienta que
permita interceptar el tráfico que genera el dispositivo a estudiar.
4. Generar una base de datos: desarrollar una extensa base de datos con muestras
de comandos de voz usados por diferentes personas.
5. Diseñar y desarrollar el ataque: desarrollar una aplicación que permita
implementar un ataque basado en huellas digitales, para extraer información del
usuario a partir del tráfico generado por el dispositivo Amazon Echo.
14En concreto, se desarrollará una red neuronal artificial con el objetivo de detectar
patrones en el tráfico de red que permitan reconocer la persona que ha ejecutado
una orden al dispositivo.
6. Experimentar con los modelos: realizar pruebas para incrementar la eficacia del
modelo y extraer resultados del ataque para generar un informe final.
3.3 Requerimientos no funcionales
También existen ciertos requerimientos no funcionales que se tienen en cuenta para
garantizar la validez del escenario presentado. Estos requisitos se agrupan según el
objetivo en el que se deben tener en cuenta, es decir, en la creación de la base de datos o
al desarrollar la red neuronal.
Base de datos:
1. Usabilidad: se debe poder utilizar por cualquier usuario. Por lo tanto, es
importante documentar correctamente el proceso de recolección de datos, la
estructura y el significado de las muestras.
2. Escalabilidad: se debe poder ampliar fácilmente en el futuro, añadiendo nuevos
datos de forma estructurada.
3. Calidad de los datos: los datos recolectados deben aportar información útil. Se
debe realizar un filtrado para eliminar aquellas muestras que tengan cualquier
defecto.
Desarrollo red neuronal:
4. Rendimiento: las aplicaciones que utilizan algoritmos Deep Learning necesitan
unos requisitos computacionales elevados. Esto se debe tener en cuenta a la hora
de desarrollar el programa a causa del limitado equipo que posee el autor del
proyecto. De igual forma, se debe configurar la aplicación y el entorno de
programación para que se pueda ejecutar en la GPU y mejorar el rendimiento.
5. Seguridad y Legalidad: el sistema que se plantea desarrollar puede permitir
obtener información privada de los usuarios. Por ello, únicamente se debe utilizar
para fines académicos.
153.4 Posibles obstáculos y riesgos
Es posible que durante la realización del proyecto puedan surgir diferentes imprevistos
que comprometan el desarrollo del trabajo. Aunque pueden aparecer dificultades que no
se hayan contemplado previamente, es importante que se localicen los riesgos más
comunes para solucionarlos de la forma más eficiente.
• En primer lugar, las técnicas de aprendizaje profundo dependen en gran medida
de la cantidad de datos disponibles para entrenar las redes neuronales. Por lo tanto,
para realizar el estudio planteado anteriormente, se debe disponer de un dataset
suficientemente extenso con capturas del tráfico que genera el altavoz inteligente.
En caso contrario, se corre el riesgo de que el sistema de aprendizaje profundo
desarrollado no sea efectivo.
• En segundo lugar, la calidad de los datos es otro de los aspectos fundamentales en
una base de datos. En particular, la calidad de las muestras en este proyecto
depende de si se capturan correctamente los comandos de voz por parte del
dispositivo. En caso contrario, se pueden llegar a obtener capturas de tráfico
erróneas o con defectos y reducir la eficiencia de la red neuronal. Por ello, se debe
realizar un filtrado después de recoger todas las muestras.
• En tercer lugar, cabe destacar que el autor del proyecto no tiene una gran
experiencia en el diseño y creación de modelos Deep Leaning. Debido a este
obstáculo, previamente al desarrollo del trabajo, se realizará una extensa
documentación y aprendizaje en este campo.
• En cuarto lugar, ejecutar aplicaciones Deep Learning comúnmente tiene unos
altos requerimientos computacionales y el autor dispone únicamente de un portátil
Lenovo Y50-70. Por lo tanto, se encuentra el riesgo de aumentar el tiempo de
ejecución de la aplicación considerablemente.
• Finalmente, si surgen algunos de los problemas que se han expuesto
anteriormente, es posible que también se presenten dificultades temporales al
existir una fecha límite fijada.
164 | Metodología
4.1 Método de desarrollo
Para alcanzar el objetivo propuesto para este estudio, se debe implementar una
planificación flexible que permita dividir el desarrollo del proyecto en ciclos cortos. Así,
se podrán añadir funcionalidades gradualmente y observar cómo afectan en el resultado
de la investigación.
Por ende, la metodología más adecuada es el Método Lean [11] que se trata de una
estrategia de trabajo orientada a equipos de desarrollo pequeños. Además, utiliza un
sistema de trabajo adaptativo en lugar de uno predictivo, es decir, el equipo del proyecto
conoce el objetivo, pero se desconoce con exactitud el proceso que se debe realizar para
alcanzarlo. Por consiguiente, se llevan a cabo ciclos incrementales, donde el desarrollo
será evolutivo según los resultados que se vayan obteniendo de los diferentes modelos de
Deep Learning que se desarrollen.
Por otro lado, el objetivo general que persigue esta metodología es crear un flujo de
trabajo que entregue los productos con el mayor valor posible al cliente. Para conseguirlo,
se deben cumplir los siguientes principios:
1. Eliminación de todo aquello innecesario (conocido como “desperdicio”). Es
decir, evitar todo aquello que no agregue valor al producto final para incrementar
así la eficiencia del proceso de desarrollo. Por ello, hay que evitar iniciar más
tareas de las que puedan ser completadas o prevenir cambios en las tareas que se
estén realizando.
2. Principio de aprendizaje continuo. Permite mejorar los conocimientos y las
habilidades de los integrantes del equipo de forma constante. Para conseguir esto,
se deberá documentar el código y realizar continuas revisiones con el director del
proyecto para recibir feedback.
3. Garantía de calidad. Desde el comienzo del proyecto, una de las metas que se
deben pretender alcanzar es la calidad del producto final. Para conseguirlo se debe
realizar una buena planificación, así como realizar constantes retroalimentaciones
por parte del director del proyecto para mejorar el producto.
4. Entregar tan rápido como sea posible. Consecuentemente, se deben favorecer los
ciclos cortos de diseño e implementación, evitando la complejidad y los excesos
que dificulten conseguir el objetivo en el menor tiempo posible.
4.2 Métodos de validación
La validación del proyecto se realizará a través de reuniones telemáticas con el director
del proyecto en la plataforma Google Meet, debido a la situación excepcional que se vive
actualmente.
17Al utilizar un método de trabajo Lean donde el desarrollo se divide en ciclos cortos, cada
una o dos semanas se realizará una reunión para comprobar los avances que se han
alcanzado. Además, el autor del proyecto presentará los resultados obtenidos hasta el
momento tanto de los datos recolectados para la base de datos como de los diferentes
modelos Deep Learning. También, se recibirá feedback de posibles mejoras que se
puedan implementar y se revisará posibles desviaciones o tareas innecesarias que se estén
realizando.
Finalmente, para comprobar y validar si se están cumpliendo los objetivos marcados para
cada ciclo, se realizarán tests con diferentes entradas de datos para comprobar cómo
evoluciona el desarrollo del modelo Deep Learning, así como el porcentaje de tasa de
aciertos y las conclusiones que se pueden obtener.
4.3 Herramientas de desarrollo
Las herramientas que se utilizarán para desarrollar el proyecto serán las siguientes:
En primer lugar, se ha optado por utilizar el lenguaje de programación Python. Este ha
servido para desarrollar la herramienta de recolección de muestras que permita generar la
base de datos, así como la aplicación Deep Learning. Esta decisión ha sido tomada tras
realizar un breve estudio sobre las diferentes posibilidades. Este lenguaje destaca por su
facilidad de aprendizaje, sintaxis simple y flexibilidad gracias a la incorporación de una
gran cantidad de bibliotecas que facilitan el desarrollo de la Inteligencia Artificial, tales
como NumPy, Pandas o SciPy [12].
En segundo lugar, el desarrollo se llevará a cabo en Anaconda Distribution. Se trata de
una de las Suite más completas para el procesamiento de grandes volúmenes de
información, como en este caso, al trabajar con una base de datos de capturas de tráfico
extensa.
En tercer lugar, para diseñar e implementar las redes neuronales se utilizará la librería
Keras [13]. Se trata de un Framework disponible en Python que nos permitirá
implementar algoritmos de Deep Learning de una forma sencilla y que utiliza como
backend TensorFlow.
En cuarto lugar, para capturar y analizar el tráfico se utilizará la aplicación Wireshark.
Esta herramienta permite capturar todos los paquetes que circulan en la red.
Finalmente, la planificación de tareas y el diagrama de Gantt se generarán gracias a la
herramienta Gantt Project. Esto permitirá mantener un control del tiempo que se ha
dedicado a cada uno de los subobjetivos.
185 | Planificación temporal
Este Trabajo de Fin de Grado (TFG) tiene una carga lectiva de 18 créditos. Teniendo en
cuenta que la normativa de la Universidad Politécnica de Cataluña indica que cada crédito
equivale a 30 horas de trabajo aproximadamente[14], se espera que se dediquen 540 horas
al desarrollo del proyecto. Asimismo, este trabajo comenzó el desarrollo el día 15 de
septiembre de 2020 y está previsto que finalice el 25 de enero de 2021.
Por lo tanto, es fundamental tener una buena planificación temporal para poder finalizar
el proyecto en la fecha de entrega correspondiente.
5.1 Listado de tareas
Este proyecto se encuentra dividido en seis grupos de tareas que se detallarán a
continuación:
[GP] Gestión del proyecto
• [GP-T1] Definir el contexto y alcance. Se trata de uno de los pasos más relevantes
porque determina el alcance y objetivos de nuestro estudio.
• [GP-T2] Definir la planificación temporal. Para ello, se divide el proyecto en tareas.
Además, se especifica una estimación del tiempo que se le dedicará a cada una de
estas, así como las posibles dependencias y los recursos que se van a utilizar.
• [GP-T3] Definir el presupuesto. Documentar los costes humanos y materiales
necesarios para realizar la investigación.
• [GP-T4] Análisis de sostenibilidad. Realizar un análisis del impacto
medioambiental, económico y social que puede ocasionar este proyecto.
• [GP-T5] Reuniones de seguimiento. Esta tarea incluye todas las reuniones
telemáticas que se lleven a cabo entre el director y autor del proyecto. Se mantienen
cada dos semanas con una duración aproximada de 1 hora y permiten revisar las
tareas que se han realizado en las dos semanas anteriores.
[EP] Estudio previo
• [EP-T4] Preparación del entorno de trabajo. Configurar el equipo necesario para
desarrollar la investigación. Por un lado, un portátil donde se desarrolla e implementa
una aplicación para detectar patrones en la red con Deep Learning. Por otro lado, se
configura una Raspberry Pi para convertirla en un Access Point y capturar
sencillamente el tráfico de red que genere el dispositivo Amazon Echo.
• [EP-T5] Estudiar algoritmos Deep Learning. Inicialmente el autor del proyecto no
posee los conocimientos necesarios para desarrollar la aplicación principal donde se
19implementarán algoritmos Deep Learning. Por esta razón, se dedican unos días para
aprender los fundamentos de la Inteligencia Artificial, analizar los algoritmos Deep
Learning más comunes y aprender a programarlos.
[AF] Análisis del tráfico
• [AF-T6] Entender el ecosistema de Amazon Alexa. Estudiar el rol que tiene cada
uno de los componentes que conforman el ecosistema de Alexa (Usuario, Amazon
Echo, Alexa Voice Services y Servidores de Skills) y cómo interactúan entre ellos.
• [AF-T7] Análisis del tráfico. Es necesario comprender cómo funciona el tráfico que
genera el dispositivo Amazon Echo. Por lo tanto, se estudia con quién interactúa este
dispositivo, qué tipo de protocolos utiliza y los patrones que permitan relacionar el
tráfico con el comando por voz ejecutado.
[DBD] Desarrollo de la base de datos
• [DBD-T8] Seleccionar comandos de voz. Recopilar y seleccionar las preguntas o
ordenes que se utilizarán como comandos de voz.
• [DBD-T9] Desarrollar aplicación recolectora de datos. Desarrollar una aplicación
que permita reproducir audios con los comandos por voz. Además, mientras Alexa
recibe la orden y la resuelve, se debe capturar el tráfico de red que genera este
dispositivo.
• [DBD-T10] Generar la base de datos. Con la herramienta desarrollada
anteriormente, se genera un dataset con muestras de un conjunto de preguntas
ejecutadas por diferentes voces.
• [DBD-T11] Filtrado de los datos. Para obtener unos resultados fiables y válidos, es
necesario realizar un filtrado para detectar y eliminar aquellas muestras que tengan
algún defecto.
• [DBD-T12] Procesamiento de los datos. Para poder utilizar el dataset generado
como entrada de datos en una red neuronal, es necesario realizar un procesamiento
de los datos.
[DA] Desarrollo aplicación
• [DA-T13] Diseñar modelo Deep Learning. Para conocer si existen fugas de
privacidad en el altavoz inteligente de Amazon se implementa un ataque basado en
huellas digitales. Por esta razón, el primer paso es decidir qué algoritmo Deep
Learning se adapta mejor a este estudio, así como diseñar la red neuronal
seleccionando los parámetros de configuración óptimos.
20• [DA-T14] Implementar aplicación y modelo. Se desarrolla e implementa la
aplicación juntamente con la red neuronal que permitirá realizar el ataque.
• [DA-T15] Analizar y corregir el modelo. Se entrena el modelo con la base de datos
generada anteriormente y se ejecutan diferentes pruebas para comprobar la tasa de
aciertos. A partir de los resultados del análisis anterior, se manipulan los parámetros
del modelo para conseguir una mayor tasa de aciertos.
• [DA-T16] Extraer conclusiones. Cuando el equipo de desarrollo obtenga el modelo
deseado para cumplir el objetivo del proyecto, se deben extraer las conclusiones
oportunas para generar el informe con los resultados obtenidos.
[GP] Memoria y presentación
• [GP-T17] Redacción de la memoria. Documento que se escribe de forma paralela al
desarrollo del Trabajo de Fin de Grado. En este se agrupa el material de la asignatura
de Gestión de Proyectos (GEP), la explicación del desarrollo del proyecto y los
resultados obtenidos.
• [GP-T18] Lectura. El autor del proyecto defiende el Trabajo de Fin de Grado ante
un tribunal que lo evaluará. Para ello, se prepara una presentación, un guión y se
realizan varios ensayos.
5.2 Recursos
5.2.1 Recursos humanos
Este TFG lo desarrollará un equipo formado por dos personas. Por un lado, el autor
del proyecto [RH-1] (Rubén Barceló Armada), estudiante de Ingeniería Informática de
la Universidad Politécnica de Cataluña. El tiempo de dedicación será de 4 horas al día.
Por otro lado, el director [RH-2] (Pere Barlet Ros), profesor de la Universidad
Politécnica de Cataluña que asesorará y ayudará al desarrollador. Realizará una reunión
con el autor cada dos semanas con una duración aproximada de 1 hora.
5.2.2 Recursos materiales
Además, se utilizarán los siguientes recursos materiales para la realización de la
investigación:
• [RM-1] Portátil Lenovo Y50-70 con procesador Intel Core i7-4720HQ, 8GB
de RAM, 512 GB SSD, tarjeta gráfica NVIDIA GTX 960M y sistema operativo
Windows 10[15].
• [RM-2] Altavoz inteligente Amazon Echo Dot de 3ª Generación[4].
• [RM-3] Raspberry Pi 4 Modelo B[16].
215.2.3 Recursos software
Finalmente, también se deberán utilizarán los siguientes programas:
• [RS-1] Wireshark[17]: software con el que se realizarán las capturas del tráfico
necesarias para entrenar el modelo Deep Learning.
• [RS-2] Python[18]: lenguaje de programación que se utilizará por su facilidad de
aprendizaje, sintaxis simple y flexibilidad.
• [RS-3] Google Meet[19]: plataforma para realizar las reuniones con el director del
proyecto.
• [RS-4] Gantt Project[21]: página web para crear diagramas de Gantt.
5.3 Planificación inicial
En la Tabla 2 se muestra un resumen de las tareas detalladas anteriormente junto con
el tiempo que aproximadamente se les dedicará, así como las dependencias que existen
entre ellas y los recursos necesarios.
Código Tarea Tiempo Dependencia Recursos
GP Gestión del proyecto 65h - -
GP-T1 Definir el contexto y alcance 25h - RH-1, RM-1
GP-T2 Definir la planificación temporal 10h T1 RH-1, RM-1, RS-4
GP-T3 Definir el presupuesto 5h T2 RH-1, RM-1
GP-T4 Análisis de sostenibilidad 5h T2 RH-1, RM-1
GP-T5 Reuniones de control 20h - RH-1, RH-2, RM-1, RS-3
EP Estudio previo 30h - -
EP-T4 Preparación del entorno de trabajo 10h - RH-1, RM-1, RM-2, RM-3, RS-1
EP-T5 Estudiar algoritmos Deep Learning 20h - RH-1, RM-1
AF Análisis del tráfico 30h - -
AF-T6 Entender ecosistema Amazon Alexa 10h - RH-1, RM-2, RM-3
AF-T7 Análisis del tráfico 20h T6 RH-1, RM-2, RM-3, RS-1
DBD Desarrollo base de datos 150h - -
DBD-T8 Seleccionar comandos de voz 20h - RH-1, RM-2, RM-3, RS-1, RS-2
DBD-T9 Desarrollar aplicación recolectora de 30h - RH-1, RM-2, RM-3, RS-1, RS-2
datos
DBD-T10 Generar base de datos 50h T8, T9 RH-1, RM-2, RM-3, RS-1, RS-2
DBD-T11 Filtrado de los datos 25h T10
DBD-T12 Procesamiento de los datos 25h T11
DA Desarrollo aplicación 100h - -
DA-T13 Diseñar un modelo Deep Learning 30h T5, T7 RH-1, RM-1, RS-2
DA-T14 Implementar aplicación y modelo 30h T13 RH-1, RM-1, RS-2
DA-T15 Analizar y corregir modelo 20h T12, T14 RH-1, RM-1, RS-2
DA-T16 Extraer conclusiones 20h T15 RH-1, RM-1, RS-2
GP Memoria y presentación 95h
GP-T17 Redacción de la memoria 80h - RH-1, RM-1
GP-T18 Lectura 15h T17 RH-1, RM-1
Reserva (Plan de acción) 40h
Total 510h
Tabla 2: Resumen tareas inicial.
225.4 Diagrama de Gantt inicial
El diagrama de Gantt (Figura 2) permite comprobar gráficamente la planificación y
el tiempo dedicado a cada una de las tareas detalladas en el apartado anterior.
Figura 2: Diagrama de Gantt inicial.
235.5 Gestión del riesgo
Durante la realización del proyecto pueden surgir diferentes obstáculos que afecten
negativamente al desarrollo del trabajo. Por lo tanto, es importante prevenir estas situaciones
con antelación generando un plan de acción a modo de respuesta a los posibles riesgos.
En primer lugar, uno de los principales obstáculos es que el autor del proyecto no tiene
mucha experiencia con el diseño y creación de modelos Deep Learning. Por ello, se ha
planificado una tarea “[EP-T5] Estudiar algoritmos Deep Learning” de aproximadamente
20 horas que permitirá al desarrollador aprender los fundamentos de la Inteligencia
Artificial y obtener los conocimientos necesarios para desarrollar la aplicación principal.
En segundo lugar, ejecutar aplicaciones Deep Learning tiene unos altos requerimientos
computacionales y el autor dispone únicamente de un portátil Lenovo Y50-70. En
consecuencia, el rendimiento de la aplicación podría verse afectado negativamente. En el
caso de que el tiempo de ejecución sea demasiado alto, se deberá optimizar el modelo y
la aplicación utilizando las horas reservadas para corregir el modelo.
En tercer lugar, el objetivo de este estudio es conocer qué tipo de información se puede
llegar a obtener de un usuario analizando únicamente el tráfico de red que genera el
altavoz inteligente. Por lo tanto, es importante disponer de un dataset suficientemente
extenso para poder extraer posibles patrones a través del modelo Deep Learning. Para
ello, se ha planificado la tarea “Generar base de datos” con una previsión de 40 horas de
trabajo, aunque se realizará en paralelo con el diseño de la aplicación.
Finalmente, si surge algún obstáculo previamente comentado, es posible que también se
presenten dificultades temporales considerando que existe una fecha límite de entrega.
Para mitigar este riesgo se ha reservado una semana antes de la defensa del proyecto para
cualquier imprevisto con un total de 40 horas. Por lo tanto, aumentaría el tiempo de
dedicación a 8 horas diarias.
5.6 Planificación final
Durante el desarrollo del proyecto han surgido diferentes imprevistos que han afectado
negativamente a la duración del estudio. Por esta razón, no se ha podido cumplir la
planificación inicial descrita anteriormente y se ha decidido posponer la defensa del
proyecto al mes de abril de 2021, incrementando así las horas disponibles de trabajo.
A lo largo de este apartado se analizarán los diferentes obstáculos que se han producido,
así como la planificación final.
245.6.1 Obstáculos
Base de datos
El principal imprevisto se encuentra relacionado con la creación de la base de datos. La
recolección de las capturas de tráfico ha sido un proceso más lento de lo que inicialmente
se había previsto y ha incrementado notablemente las horas de trabajo necesarias para
cumplir este objetivo. La base de datos debía ser suficientemente extensa; por ello, se
marcó el objetivo de capturar 500 muestras para cada una de las 100 preguntas
seleccionadas con tres voces diferentes. Teniendo en cuenta que de media se necesitaban
15 segundos para cada una de las muestras; para obtener todos los datos se necesitaban
aproximadamente 25 días completos. Además, el autor del proyecto solo tenía disponible
un dispositivo Amazon Echo para poder reproducir los comandos de voz.
En segundo lugar, debido al COVID-19 el proceso de captura de muestras se vio afectado
negativamente. Hay que destacar que para poder ejecutar el audio con los comandos por
voz y que el dispositivo lo detecte correctamente, no debe producirse ningún ruido de
fondo. En caso contrario, el altavoz inteligente puede llegar a no detectar la orden que se
está ejecutando. Por lo tanto, se debía instalar el altavoz inteligente en una habitación
donde no se encuentre nadie. No obstante, este requisito ha sido difícil gestionarlo porque
en estos meses gran parte del tiempo la población ha tenido que estar en sus casas.
Finalmente, la tarea DBD-T10: Generar base de datos sufrió una variación.
Concretamente, se planteó la idea de generar una base de datos adicional con comandos
de voz en inglés, con el objetivo de publicar un artículo en la revista Computer Networks.
Dificultad para implementar redes neuronales
La creación de la red neuronal se trata de otra de las causas que ha provocado que no se
pueda cumplir con la planificación inicial. Era la primera vez que el autor del proyecto
que afrontaba un problema de Deep Learning. Por lo tanto, las primeras semanas las tuvo
que dedicar a aprender cómo funcionan los algoritmos y la programación con la API de
Keras.
Además, para poder entrenar el modelo y poder analizar su funcionamiento se necesitaba
disponer de la base de datos, para poder procesar los datos e introducirlos como entrada
de modelo. No obstante, este proceso se demoró más de lo esperado por las causas
presentadas anteriormente.
255.6.2 Planificación final
En la Tabla 3 se puede observar un resumen de las tareas con el tiempo que finalmente
se les ha dedicado a cada una de ellas, así como las dependencias y los recursos
necesarios.
Código Tarea Tiempo Dependencia Recursos
GP Gestión del proyecto 65h - -
GP-T1 Definir el contexto y alcance 25h - RH-1, RM-1
GP-T2 Definir la planificación temporal 10h T1 RH-1, RM-1, RS-4
GP-T3 Definir el presupuesto 5h T2 RH-1, RM-1
GP-T4 Análisis de sostenibilidad 5h T2 RH-1, RM-1
GP-T5 Reuniones de control 20h - RH-1, RH-2, RM-1, RS-3
EP Estudio previo 30h - -
EP-T4 Preparación del entorno de trabajo 10h - RH-1, RM-1, RM-2, RM-3, RS-1
EP-T5 Estudiar algoritmos Deep Learning 20h - RH-1, RM-1
AF Análisis del tráfico 30h - -
AF-T6 Entender ecosistema Amazon Alexa 10h - RH-1, RM-2, RM-3
AF-T7 Análisis del tráfico 20h T6 RH-1, RM-2, RM-3, RS-1
DBD Desarrollo base de datos 200h - -
DBD-T8 Seleccionar comandos de voz 20h - RH-1, RM-2, RM-3, RS-1, RS-2
DBD-T9 Desarrollar aplicación recolectora de 30h - RH-1, RM-2, RM-3, RS-1, RS-2
datos
DBD-T10 Generar base de datos (Español/Inglés) 80h T8, T9 RH-1, RM-2, RM-3, RS-1, RS-2
DBD-T11 Filtrado de los datos 30h T10
DBD-T12 Procesamiento de los datos 40h T11
DA Desarrollo aplicación 240h - -
DA-T13 Diseñar un modelo Deep Learning 80h T5, T7 RH-1, RM-1, RS-2
DA-T14 Implementar aplicación y modelo 100h T13 RH-1, RM-1, RS-2
DA-T15 Analizar y corregir modelo 40h T12, T14 RH-1, RM-1, RS-2
DA-T16 Extraer conclusiones 20h T15 RH-1, RM-1, RS-2
GP Memoria y presentación 105h
GP-T17 Redacción de la memoria 90h - RH-1, RM-1
GP-T18 Lectura 15h T17 RH-1, RM-1
Reserva (Plan de acción) 40h
Total 710h
Tabla 3: Resumen tareas final.
26También puede leer

















































