Estudio del estado del arte en bases de datos orientadas a grafos
←
→
Transcripción del contenido de la página
Si su navegador no muestra la página correctamente, lea el contenido de la página a continuación
Universidad ORT Uruguay
Facultad de Ingenierı́a
Estudio del estado del arte en
bases de datos orientadas a grafos
Entregado como requisito para la obtención del tı́tulo de
Licenciatura en Ingenierı́a de Software
Miguel Nuñez (191877)
Tutores: Juan Gabito, Sergio Yovine
2021
Declaraciones de autorı́a
Miguel Nuñez el autor de esta obra, declaro que el trabajo que se presenta en
esta obra es de mi propia mano. Puedo asegurar que:
La obra fue producida en su totalidad mientras realizaba el Trabajo integrador;
Cuando he consultado el trabajo publicado por otros, lo he atribuido con
claridad;
Cuando he citado obras de otros, he indicado las fuentes. Con excepción de
estas citas, la obra es enteramente mı́a;
En la obra, he acusado recibo de las ayudas recibidas;
Cuando la obra se basa en trabajo realizado conjuntamente con otros, he
explicado claramente qué fue contribuido por otros, y qué fue contribuido por
mi;
Ninguna parte de este trabajo ha sido publicada previamente a su entrega,
excepto donde se han realizado las aclaraciones correspondientes.
Miguel Nuñez
26/07/2021
2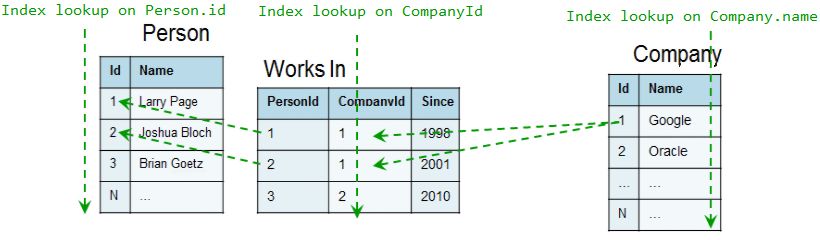
Agradecimientos
A mi familia por el apoyo y la paciencia que me han brindado dı́a a dı́a para
alcanzar una de las metas propuestas.
A mi amigo Eduardo, quien directa o indirectamente ha influido en mis decisio-
nes, ya sea con una plática o con el ejemplo de sus acciones.
A compañeros y compañeras con quienes hemos ido caminando juntos y mutua-
mente nos hemos apoyado.
A los profesores por compartir todos sus conocimientos, paciencia y voluntad de
explicar las veces necesario para comprender el tema, para que pueda crecer tanto
en el ámbito personal como en el profesional.
A mis tutores y guı́a académico que me han trasmitido sus conocimientos para
seguir adelante.
3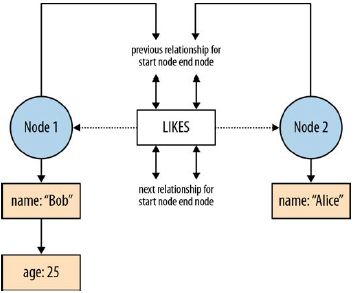
Abstract
En este trabajo de tesis se muestran las denominadas bases de datos orientada
a grafos (BDoG) y para comprender el contexto se hace una introducción a grafos,
sus propiedades y tipos de grafos para después profundizar en las BDoG.
Otro aspecto trabajado son las comparaciones de motores de bases de datos
orientadas a grafos contra bases de datos relacionales, comparando consultas com-
plejas y el armado del modelado. En efecto el modelado y algunos tipos de consultas
se pueden volver complejos en el mundo relacional mientras que en las BDoG se da
de forma natural.
También se brinda una guı́a para decidir cuándo utilizar una BDoG con simples
preguntas y también resumidas en un árbol de decisión.
Además se menciona diferentes tipos de gestores de base de datos orientadas
a grafos cubriendo almacenamiento en disco, en la nube y en memoria. Para cada
una se detallan la estructura de almacenamiento, el modelado de datos, manejo de
transacciones, interfaces y lenguajes de consultas.
Sobre los lenguajes de consultas, se comparan los tres más populares de la ac-
tualidad.
Finalmente se menciona el aprendizaje sobre grafos done se comentan cuatro
técnicas principales.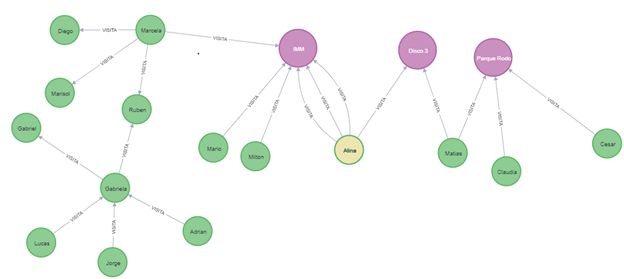
Palabras clave
grafo; base de datos orientada a grafos (BDoG); base de datos relacional (RDBMS);
SQL (Structured Query Language); NoSQL; Common Table Expressions (CTE); ti-
pos de grafos; neo4j; ArangoDB; TerminusDB; Amazon Neptune; Cypher; Gremlin;
Sparql;
5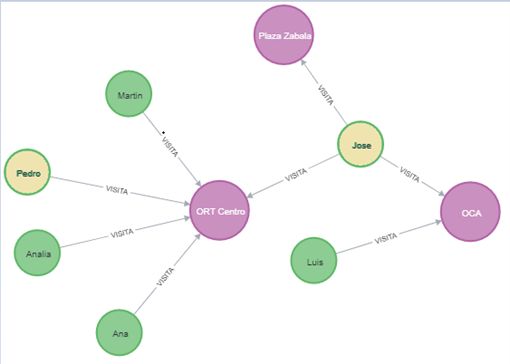
Índice general
1. Introducción 8
1.1. Contexto y motivación . . . . . . . . . . . . . . . . . . . . . . . . . . 8
1.2. Objetivos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
1.3. Estructura del documento . . . . . . . . . . . . . . . . . . . . . . . . 9
2. Introducción a grafos 11
2.1. ¿Qué es un grafo? . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.2. ¿Qué es una base de datos orientada a grafos (BDoG)? . . . . . . . 12
2.3. Comparación con otros tipos de bases de datos . . . . . . . . . . . . 13
2.4. ¿Por qué existen? . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
3. Base de datos orientada a grafos vs base de datos relacional 16
3.1. Consultas recursivas . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
3.1.1. Representación con RDBMS . . . . . . . . . . . . . . . . . . . 19
3.1.2. Representación con BDoG . . . . . . . . . . . . . . . . . . . . 21
3.2. Diferentes tipos de resultados . . . . . . . . . . . . . . . . . . . . . 23
3.2.1. Representación con RDBMS . . . . . . . . . . . . . . . . . . . 23
3.2.2. Representación con BDoG . . . . . . . . . . . . . . . . . . . . 24
3.3. Caminos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
3.4. Modelado BDoG . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
4. Cuándo usar BDoG 29
4.1. Selección - búsqueda . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
4.2. Datos relacionados o recursivos . . . . . . . . . . . . . . . . . . . . . 30
4.3. Agregación . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
4.4. Coincidencia de patrones . . . . . . . . . . . . . . . . . . . . . . . . . 31
4.5. Centralidad, agrupación e influencia . . . . . . . . . . . . . . . . . . . 31
4.6. Guı́a para decidir . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
4.7. Algunos usos de la BDoG . . . . . . . . . . . . . . . . . . . . . . . . 34
5. Tipos de grafos 36
5.1. Grafo no dirigido . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
5.2. Grafo dirigido . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
5.3. Grafo con peso o ponderado . . . . . . . . . . . . . . . . . . . . . . . 37
5.4. Grafo con etiquetas . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
5.5. Grafo de propiedades . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
5.6. Multigrafo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
6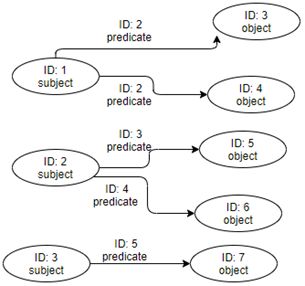
6. Tipos de gestores de BDoG 39
6.1. Neo4j . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
6.1.1. Modelo de datos . . . . . . . . . . . . . . . . . . . . . . . . . 39
6.1.2. Restricciones de integridad . . . . . . . . . . . . . . . . . . . . 39
6.1.3. Manejo de transacciones . . . . . . . . . . . . . . . . . . . . . 40
6.1.4. Almacenamiento fı́sico de la estructura de datos . . . . . . . . 40
6.1.5. Datos en cache . . . . . . . . . . . . . . . . . . . . . . . . . . 43
6.2. ArangoDB . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
6.2.1. Modelo de datos . . . . . . . . . . . . . . . . . . . . . . . . . 45
6.2.2. Restricciones de integridad . . . . . . . . . . . . . . . . . . . . 45
6.2.3. Manejo de transacciones . . . . . . . . . . . . . . . . . . . . . 45
6.2.4. Almacenamiento fı́sico de la estructura de datos . . . . . . . . 47
6.3. TerminusDB . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
6.3.1. Modelo de datos . . . . . . . . . . . . . . . . . . . . . . . . . 48
6.3.2. Restricciones de integridad . . . . . . . . . . . . . . . . . . . . 49
6.3.3. Manejo de transacciones . . . . . . . . . . . . . . . . . . . . . 49
6.3.4. Almacenamiento de la estructura de datos . . . . . . . . . . . 49
6.4. Amazon Neptune . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
6.4.1. Modelo de datos . . . . . . . . . . . . . . . . . . . . . . . . . 52
6.4.2. Restricciones de integridad . . . . . . . . . . . . . . . . . . . . 52
6.4.3. Manejo de transacciones . . . . . . . . . . . . . . . . . . . . . 54
6.4.4. Almacenamiento de la estructura de datos . . . . . . . . . . . 54
6.4.5. Almacenamiento distribuido . . . . . . . . . . . . . . . . . . . 55
7. Lenguajes de consultas BDoG 56
7.1. CYPHER vs GREMLIN vs SPARQL . . . . . . . . . . . . . . . . . 56
7.2. Ejemplo práctico . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
7.2.1. Datos del modelo - COVID-19 . . . . . . . . . . . . . . . . . . 59
7.2.2. Consultas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
8. Aprendizaje sobre grafo 63
8.1. Clasificación de nodos . . . . . . . . . . . . . . . . . . . . . . . . . . 63
8.2. Predicción de enlaces . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
8.3. Detección de comunidad . . . . . . . . . . . . . . . . . . . . . . . . . 63
8.4. Clasificación de grafo . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
8.5. Modelos de inteligencia artificial - aprendizaje automático explicables 64
9. Conclusiones 66
10.Glosario 67
11.Anexo A 73
11.1. Datos de ejemplos - COVID-19 . . . . . . . . . . . . . . . . . . . . . 73
7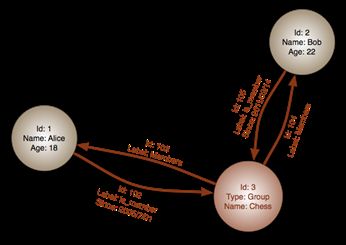
1. Introducción
Los RDBMS han sido el paradigma que ha dominado el almacenamiento de datos
en los sistemas que se han desarrollado durante los últimos 40 años. Es un modelo
bien fundado en bases matemáticas que puede representarse fácilmente usando al-
goritmos computacionales, pero también lo hace muy rı́gido.
Aun ası́, hemos llegado a un punto en que seguir usando bases de datos relacio-
nales para todos los casos es simplemente inviable.
En un mundo de constantes cambios a nivel de sistemas, donde los RDBMS no
son flexibles, también por su naturaleza computacional se vio la necesidad de otras
opciones para otros tipos de escenarios complejos.
Por lo que nace el movimiento NoSQL o también “No uses solo SQL”. Donde las
categorı́as más usadas de NoSQL son:
Bases de datos clave valor.
Bases de datos columnares.
Bases de datos orientadas a documentos.
Bases de datos orientadas a grafos (BDoG).
En este trabajo se profundizará en las bases de datos orientadas a grafos.
1.1. Contexto y motivación
En la actualidad hay un gran número de BDoG con sus propios lenguajes de
consultas y estructuras de almacenamiento.
Además, en los grafos se puede observar que se consideran las relaciones (aris-
tas) con lo cual las consultas que implican estas relaciones se pueden hacer de forma
eficiente.
Teniendo en cuenta lo mencionado anteriormente, surgió la motivación de pro-
fundizar en algunos motores, como almacenan los datos, los tipos de grafos que
soportan, las diferencias entre los lenguajes de consultas y sus ventajas contra los
almacenamientos RDBMS.
8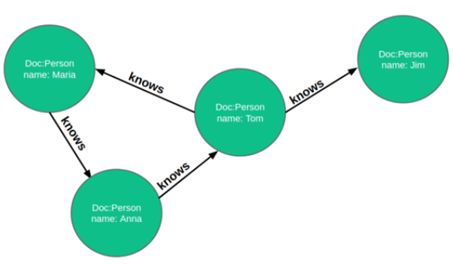
1.2. Objetivos
1. Introducción a grafos.
2. Comparativa entre BDoG vs RDBMS.
3. Cuando utilizar BDoG.
4. Tipos de Grafos.
5. Lenguaje de consultas.
6. Aprendizaje sobre grafos.
1.3. Estructura del documento
Capı́tulo 1: Introducción
Este capı́tulo presenta el contexto y motivación del trabajo con el alcance del
mismo.
Capı́tulo 2: Introducción a grafos
El objetivo de este capı́tulo es relacionarse con los grafos y bases de datos orien-
tadas a grafos. También se compara contra otros motores de bases de datos.
Capı́tulo 3: Base de datos orientada a grafos vs base de datos relacional
Se comparan los RDBMS contra la BDoG en sus accesos a búsquedas: consultas
recursivas, devolver diferentes tipos de resultados y caminos. Además, la compara-
tiva abarca el modelado en la práctica mostrando las ventajas del grafo.
Capı́tulo 4: Cuándo usar BDoG
En este capı́tulo se brindan herramientas para identificar el uso de BDoG. Tam-
bién se detalla un árbol de decisión para mejorar la elección sobre la BDoG.
Capı́tulo 5: Tipos de grafos
El motivo de este capı́tulo es clasificar los tipos de grafos para reconocerlos en
los diferentes motores de base de datos de grafos.
Capı́tulo 6: Tipos de gestores de BDoG
En este capı́tulo se mencionan algunos tipos de BDoG mostrando la estructura
de almacenamiento. También se menciona el manejo de las transacciones, el modelo
9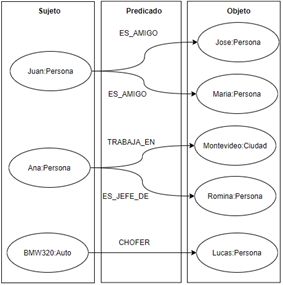
de datos, las interfaces y lenguaje de consultas.
Capı́tulo 7: Lenguajes de consultas BDoG
Este capı́tulo se centra en la comparativa de los lenguajes de consultas Cypher,
Gremlin y Sparql con un ejemplo práctico de la actualidad.
Capı́tulo 8: Aprendizaje sobre grafo
En este capı́tulo se presentan distintas técnicas de aprendizaje sobre grafos.
Capı́tulo 9: Conclusiones
En este capı́tulo se reflexiona las lecciones aprendidas durante el transcurso del
trabajo.
102. Introducción a grafos
Las aplicaciones modernas se basan en datos, datos que aumentan constantemen-
te tanto en tamaño como en complejidad. Incluso a medida que crece la complejidad
de nuestros datos, también aumentan nuestras expectativas de la información que
nuestras aplicaciones pueden derivar de esos datos.
2.1. ¿Qué es un grafo?
Cuando miras una mapa de rutas o usas redes sociales como Facebook, Linke-
dIn o Twitter, usas un grafo. Los grafos son una forma casi ubicua de pensar en
escenarios del mundo real, ya que abstraen los elementos y las relaciones que se
representan, y esta abstracción permite un procesamiento rápido y eficiente de las
conexiones dentro de los datos.
En los mapas, las ciudades se representan con frecuencia mediante cı́rculos, y
las carreteras que las conectan se representan mediante lı́neas. En una red social,
las personas se conectan entre sı́ a través de amigos o seguidores. Este proceso
de generalizar entidades y las conexiones entre ellas es la base fundamental de los
grafos y la teorı́a de grafos. Debido a que los matemáticos han definido y estudiado
los grafos durante siglos, podemos ofrecer estas definiciones utilizadas en la teorı́a
de grafos:
Grafo: G = (V, A) donde V es un conjunto de vértices conectados por un
conjunto de aristas A.
Vértice: un punto en un gráfico donde cero o más bordes se encuentran,
también conocido como un nodo o una entidad.
Arista: una relación entre dos vértices dentro de un gráfico, a veces llamado
relación, enlace o conexión.
Si bien las definiciones son agradables, los grafos tienen la ventaja de ser simples
de ilustrar. Al trabajar con grafos, los diagramas generalmente consisten en cı́rculos
que representan vértices y lı́neas que representan aristas.
11Figura 2.1: Representación de grafos con cı́rculos para los vértices y lı́neas para las
aristas
Los grafos no son conceptos nuevos para los desarrolladores de software. Éstas
son la base de muchas estructuras de datos comunes que usamos todo el tiempo,
probablemente sin siquiera darnos cuenta. Las estructuras de datos comunes, como
listas vinculadas y árboles, son simplemente tipos de grafos a los que se les apli-
can reglas especı́ficas. Si bien estas estructuras de datos son bien conocidas por los
desarrolladores, los detalles reales de implementación especı́ficos de los grafos gene-
ralmente se abstraen.
2.2. ¿Qué es una base de datos orientada a grafos
(BDoG)?
Es una base de datos que tiene como propósito almacenar estructuras de datos
que tienen topologı́a de grafo, es decir, que la información que se almacena se puede
representar por medio de vértices y aristas entre ellos.
Por definición, una BDoG agruparı́a a cualquier solución de almacenamiento en
la que los elementos que están conectados se enlazan sin hacer uso de una referencia
por medio de ı́ndices (que serı́a el método habitual de simular una relación en una
RDBMS), de esta forma, los vecinos de una entidad son accesibles directamente por
ella por medio de una referencia directa, sin pasar por estructuras intermedias que
hagan el proceso de referenciado.
En esta definición no tenemos en cuenta el tipo de grafo (en su sentido más
amplio) que nuestros datos seguirán, ni en el tipo de relación (dirigidas o no), ni en
la multiplicidad de las mismas entre dos vértices (unirelacional o multirelacional),
ni en la aridad que reflejen las aristas (grafo o hipergrafo).
12Por lo tanto, una BDoG cumple los siguientes criterios:
El almacenamiento está optimizado para que los datos sean repre-
sentados como un grafo, con una disposición para almacenar vértices y
aristas.
El almacenamiento está optimizado para el recorrido del grafo, sin
usar un ı́ndice al seguir las aristas. Una BDoG está optimizada para consultas
aprovechando la proximidad de los datos, comenzando desde uno o varios
vértices raı́z, en lugar de consultas globales.
Modelo de datos flexible para algunas soluciones: no es necesario declarar
tipos de datos para vértices o aristas, a diferencia del modelo orientado a tablas
más restringido de una base de datos relacional.
API integrado con puntos de entrada para los algoritmos más clásicos de la
teorı́a de grafos.
Como punto final, las BDoG mejoran la productividad del desarrollador para
ciertos problemas de una manera que otras tecnologı́as no pueden. Almacenar los
datos de una manera que represente mejor a su contraparte del mundo real puede
facilitar que los desarrolladores razonen y comprendan el dominio en el que están
trabajando. Esto permite que los nuevos miembros del equipo se pongan al dı́a más
rápidamente en el dominio. Aprenden el dominio y la representación de su base de
datos simultáneamente.
2.3. Comparación con otros tipos de bases de
datos
Debemos tener en cuenta que el mundo de las bases de datos no se limita a los
tipos de almacenes de datos relacional o de grafo. En los términos más amplios, una
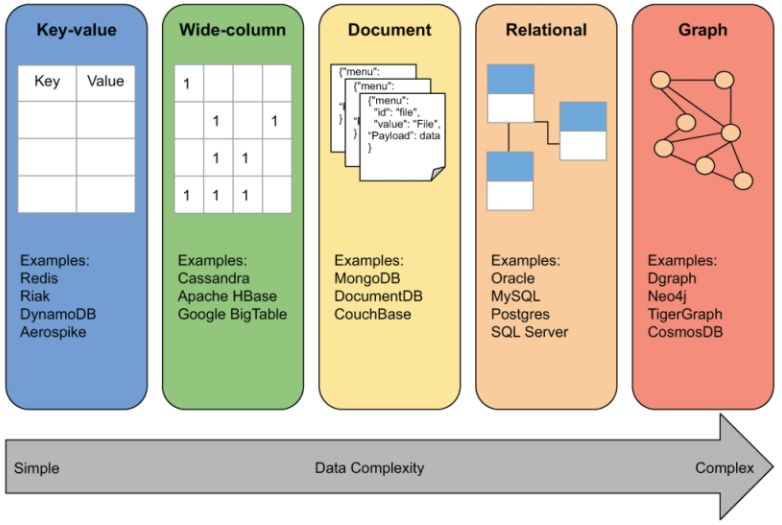
base de datos se puede clasificar como un tipo de motor en una de las cinco formas
siguientes:
Clave-Valor: representa todos los datos mediante un identificador único (una
clave) y un objeto de datos asociado (el valor).
Columna ancha u orientada a columnas: almacena datos en filas con un
potencial de una gran cantidad de columnas y/o de columnas variables en cada
fila.
Documento: almacena datos en un documento con clave única que puede
tener diferentes esquemas y que puede contener datos anidados.
Relacional: almacena datos en tablas que contienen filas con un esquema
estricto. Se pueden establecer relaciones entre tablas permitiendo la unión de
filas.
13Grafo: almacena datos como vértices (también conocida como nodos) y aristas
(también conocida como relaciones).
Figura 2.2: Tipos de motor de base de datos ordenados por complejidad de datos,
recuperado de [1]
En la Figura 2.2 se puede observar que solo las RDBMS y las BDoG, por defecto,
incluyen la capacidad de relacionar entidades dentro de los datos. Puede ser posible
hacerlo con implementaciones para el resto, pero esto suele ser una mejora agregada
por la implementación especı́fica de un proveedor.
2.4. ¿Por qué existen?
Una de las formas para obtener los datos de un sistema es a través de la base de
datos relacional. Los RDBMS cuentan con el álgebra relacional1 y con un lenguaje
de consultas común para todas los fabricantes SQL (Structured Query Language)2 .
Esta forma de almacenar y obtener los datos se ve afectada con la aparición
de la web 2.0, el desarrollo de software basado en navegadores web como también
la llegada de nuevas aplicaciones, como redes sociales, ecommerce, donde cualquier
usuario puede subir contenidos provocando ası́ un crecimiento exponencial de los
datos.
1
https://es.wikipedia.org/wiki/ %C3 %81lgebra relacional
2
https://es.wikipedia.org/wiki/SQL
14Dada la gran cantidad de datos sumado a problemas de escalabilidad y rendi-
miento donde hay escritura de miles de usuarios concurrentes y con millones de
consultas diarias surgió la necesidad de sistemas especifico apareciendo ası́ el movi-
miento NoSQL3 .
Las bases de datos NoSQL son sistemas de almacenamiento que no cumple el
esquema entidad-relación. Tampoco tienen el formato de tabla donde almacenan sus
datos, hacen usos de otros formatos: clave-valor, mapeo de columnas, grafos.
Las relaciones existen en la base de datos relacionales, pero solo en el momento
del modelado. En el momento de unir las tablas estas relaciones desaparecen y que-
dan expresadas en restricciones de claves foráneas4 para mantener la validez de los
datos, pero no queda la relación plasmada en el modelo fı́sico. De esta manera la
gran mayorı́a de consultas deben proyectar de varias tablas (JOIN) con estrategias
diversas para obtener los datos. Para entender podemos explorar el árbol de ejecu-
ción en una consulta SQL5 .
A medida que los datos atı́picos se multiplican y la estructura general del con-
junto de datos se vuelve mas compleja y menos uniforme, el modelo relaciona se
sobrecarga con grandes tablas de combinaciones, filas escasamente pobladas y mu-
chos campos nulos, nos impiden el rendimiento y dificultan la evolución de una base
de datos existente a respuestas de nuevas funcionalidades, cambios en el sistema.
Además tanto los RDBMS como las NoSQL están pensadas para almacenar co-
sas y no para entender como estas se relacionan entre si. Aquı́ es donde el modelo
orientado a grafos cobra sentido.
3
https://es.wikipedia.org/wiki/NoSQL
4
https://es.wikipedia.org/wiki/Clave foránea
5
https://slideplayer.es/slide/2747325/
153. Base de datos orientada a grafos
vs base de datos relacional
Una BDoG es una buena opción para explorar datos estructurados como un gra-
fo (o derivados como un árbol), en particular cuando las relaciones entre esos datos
son tan significativas como los mismos datos. El caso ideal de una consulta serı́a
comenzar por uno o varios vértices y ejecutar recorridos de grafos.
A pesar de sus nombres, las RDBMS están poco preparadas para explorar rela-
ciones de forma masiva, en donde necesita, por regla general, usar claves foráneas
accediendo a tablas intermedias. En BDoG los recorridos se realizan siguiendo pun-
teros fı́sicos, mientras que las claves externas son punteros lógicos.
Aunque el siguiente ejemplo es muy simple, muestra un escenario en el que el
rendimiento de una BDoG es muy superior a la de una RDBMS. En ambos casos
tenemos la misma información y pretendemos extraer todos los trabajadores de una
determinada empresa. Por ejemplo, suponemos un caso para encontrar a todas las
personas que trabajan en Google.
Con un modelo relacional podrı́amos ejecutar la siguiente consulta, que proba-
blemente necesitarı́a 3 búsquedas de ı́ndice correspondientes a las claves externas
del modelo.
Figura 3.1: Ejemplo Tablas Company, adaptado de [2], [3]
16Figura 3.2: Ejemplo Tablas Company - SELECT, adaptado de [2], [3]
En el caso de un grafo, la consulta necesitará una búsqueda de ı́ndice, luego
atravesará las relaciones desreferenciando punteros fı́sicos directamente.
Figura 3.3: Ejemplo Tablas Company, adaptado de [2], [3]
Este es un ejemplo muy simple, sin embargo, muestra una situación en la que el
rendimiento de una BDoG será superior al de una base de datos relacional.
Esta diferencia de rendimientos puede parecer poco relevante cuando se trabaja
con pocos datos, pero a medida que el volumen se incrementa, esta diferencia se hace
notable. A pesar de que probablemente en la primera parte de la consulta la BDoG
también deba mirar un ı́ndice para encontrar los vértices iniciales para el recorrido,
en el resto de los pasos se hace por uso directo de los punteros fı́sicos que relacionan
los vértices (esta consulta se ejecutará más o menos en tiempo constante), mientras
que en la RDBMS es necesario buscar en al menos un ı́ndice (a menudo dos) cada
una de las referencias buscadas costará O(log2 n) si se usa un ı́ndice B-Tree (siendo
n el número de registros en la tabla).
En cualquier caso, comparar modelos de bases de datos entre sı́ suele ser un
reto debido a las diferentes concepciones que tienen y a los distintos problemas que
intentan resolver. Podemos decir que, cuando la profundidad del recorrido sea im-
portante, o cuando no se conozca de antemano las BDoG son más eficientes que las
RDBMS, pero si la consulta se puede estructurar mucho, entonces hay herramientas
de optimización para RDBMS que pueden ofrecer resultados más eficientes. Uno de
los casos en los que las RDBMS no pueden optimizar sus consultas es precisamente
cuando la búsqueda es parametrizada y no se tiene a priori una forma estructurada
17uniforme, sino que depende de los resultados intermedios que se vayan obteniendo
a medida que se recorra el grafo.
3.1. Consultas recursivas
Las consultas recursivas se ejecutan varias veces seguidas, llamándose a sı́ mismas
repetidamente hasta que alcanzan alguna condición de escape o terminación. Las ba-
ses de datos relacionales no manejan bien las operaciones recursivas (especialmente
las ilimitadas), y tienen problemas tanto con la sintaxis como con el rendimiento.
Esto generalmente lleva a escribir y mantener consultas complejas, desnormalización
excesiva de nuestros datos, o ambos, todo en un esfuerzo por devolver resultados de
manera oportuna.
En las RDBMS en general, las consultas recursivas son útiles cuando se trabaja
con datos autorreferenciales o estructuras de datos en forma de grafo / árbol. Es-
tas consultas aprovechan el llamado Common Table Expressions (CTE)1 que es la
cláusula SQL WITH.
Observaremos la estructura formal de la consulta recursivas.
Figura 3.4: Estructura formal de consulta SQL recursiva, recuperado de [4]
En la estructura vemos que no es muy intuitiva además de la complejidad que
agrega para depurar como también el costo en términos de cómputos.
Analizaremos un ejemplo sencillo para entender las partes de la consulta en una
RDBMS contra la BDoG, el ejemplo minimalista trata de una jerarquı́a de gestión
de una posible solución para una empresas. Se utilizo para el ejemplo en RDBMS
MySQL2 y para BDoG Neo4j3 .
1
https://social.technet.microsoft.com/wiki/contents/articles/37558.t-sql-common-table-
expression-cte.aspx
2
https://www.mysql.com/
3
https://neo4j.com/
18Figura 3.5: Ejemplo de jerarquı́a de personas en una empresa
3.1.1. Representación con RDBMS
Para modelar la jerarquı́a (ver Figura 3.5 ), tenemos el siguiente esquema de
tabla e inserciones de los datos a continuación:
Figura 3.6: Representación del esquema en MySQL - ejemplo de jerarquı́a de perso-
nas en una empresa
19Luego usamos una función recursiva para consultar estos datos para encontrar
la jerarquı́a de administración del presidente (ver Figura 3.7).
Figura 3.7: Código recursivo RDBMS - ejemplo de jerarquı́a de personas en una
empresa, adaptado de [4], [5]
Lo primero es montar una CTE que busque el elemento de partida. Con las lı́neas
del código de recursivas podemos identificar sobre una consulta tipo:
En las lı́neas del 1 a 3 se define el CTE.
En las lı́neas del 4 a 6 identificamos el primer elemento de la estructura
jerárquica, nodo o raı́z. El WHERE implica el punto de partida.
En la lı́nea 7 preparamos el conjunto recursivo.
En la lı́nea 8 por ser UNION ALL devolvemos el mismo numero de elementos
y tipos.
En las lı́neas 9 al 10 se relacionan la tabla origen con la tabla de expresión
común o lo que es lo mismo la recursividad.
En la lı́nea 11 se indica que tiene que buscar los elementos de la tabla origen
en los cuales su columna padre, apunte al id que tenga en ese instante el CTE.
En las lı́neas 12 y 13, la salida de la tabla con expresión común.
El resultado de la consulta (ver Figura 3.1.1).
20Figura 3.8: Salida de la consulta recursiva - ejemplo de jerarquı́a de personas en una
empresa
3.1.2. Representación con BDoG
Para modelar esta jerarquı́a con neo4j se utilizó el lenguaje de consultas Cypher4
en primer lugar creamos los vértices (nodos) y luego las aristas (relaciones) (ver
Figura 3.9, Figura 3.10).
Figura 3.9: Crear vértices - ejemplo de jerarquı́a de personas en una empresa
4
https://neo4j.com/developer/cypher/
21Figura 3.10: Crear relaciones - ejemplo de jerarquı́a de personas en una empresa
Figura 3.11: Consulta lenguaje Cypher para neo4j - ejemplo de jerarquı́a de personas
en una empresa
Este ejemplo (ver Figura 3.11) demuestra la naturaleza sencilla con la que pue-
de hacer preguntas de forma recursiva en un grafo. Las BDoG utilizan sus ricas
representaciones de relaciones para manejar estas consultas recursivas ilimitadas de
manera limpia y eficiente.
Este recorrido se corresponde naturalmente con nuestro instinto de navegar vi-
sualmente por la jerarquı́a de los datos. Podemos intuir que desde el vértice persona
presidente quiero obtener todas las aristas hacia el resto de las personas con la re-
lación TRABAJA CON.
Por otro lado, las BDoG también pueden visualizar el resultado en forma de
grafo. Y comparando con Figura 3.5 que fue la estructura de partida, obtendremos
el mismo resultado (no hubo cambio con el dominio de la solución) Figura 3.12.
22Figura 3.12: Resultado de neo4j - ejemplo de jerarquı́a de personas en una empresa
3.2. Diferentes tipos de resultados
Cuando se necesitado devolver varios tipos de datos diferentes de una base de
datos, todo dentro de un único conjunto de resultados.
Veamos cómo se comparan las RDBMS y BDoG cuando devuelven diferentes
tipos.
Para esto tomaremos un ejemplo de un sistema de procesamiento de ordenes y
queremos devolver la información de las órdenes y los productos. Es una implemen-
tación simple para cada base de datos con la intención de comparar ambos mundos.
3.2.1. Representación con RDBMS
Es posible lograr esto con una unión de todas las columnas en todas las tablas,
tiende a producir resultados menos que ideales.
23Figura 3.13: Tablas de productos y ordenes en una RDBMS, adaptado de [1]
El siguiente fragmento de código muestra cómo escribir una consulta para recu-
perar la información de órdenes y productos.
Figura 3.14: Fragmento de código SQL para la consulta - órdenes y productos,
adaptado de [1]
Figura 3.15: Resultado de la consulta SQL – órdenes y productos, adaptado de [1]
Vemos en el resultado que la unión de estos dos tipos de datos dispares dicta
que nuestra respuesta contiene una gran cantidad de valores nulos (comúnmente
conocidos como datos dispersos o matriz dispersa)5 . Esta abundancia de datos nulos
se debe a que las columnas entre las dos tablas son inconsistentes.
Una RDBMS especifica que el conjunto de resultados devuelto debe contener un
conjunto coherente de columnas. En los casos de datos escasos, esto no solo aumenta
la cantidad de datos devueltos, sino que también reduce la naturaleza descriptiva de
la estructura de datos.
3.2.2. Representación con BDoG
Uno de los puntos fuertes de una base de datos orientada a grafos es la capacidad
de devolver diferentes tipos de datos en los resultados.
5
https://es.wikipedia.org/wiki/Matriz dispersa
24Figura 3.16: Grafo de producto y ordenes en BDoG – neo4j
Con este grafo, podemos escribir una consulta para devolver tanto los datos del
producto como del pedido muy simple sin contener valores nulos.
Figura 3.17: Fragmento de código Cypher – neo4j y su resultado
En comparación con los resultados anteriores de SQL, los datos devueltos por el
grafo conservan el significado semántico de lo que es el objeto y lo que representa,
sin los datos nulos extraños.
Debido a que las BDoG brindan la flexibilidad para devolver datos dispares,
podemos crear un código mucho más limpio cuando trabajamos con tipos de datos
muy variados.
3.3. Caminos
Un camino es la secuencia de vértices y aristas que describen cómo se movió el
recorrido a través del grafo.
Representa problemas fundamentales que se encuentran en muchas aplicaciones
del mundo real, como encontrar un camino en un mapa, encontrar el uso óptimo
25de recursos en un sistema logı́stico, localizar conexiones entre personas en una red
social, etc. Cada uno de estos casos se trata fundamentalmente de determinar el
conjunto óptimo de pasos para pasar de una entidad a otra. La estructura de datos
del grafo nos permite aprovechar estas capacidades de búsqueda de caminos, que no
son una construcción nativa en otros tipos de bases de datos.
Usando una RDBMS, no podemos encontrar una manera de resolver caminos
óptimos sin usar un método de fuerza bruta para calcular todas las combinaciones
posibles. Sin embargo, con un modelado de datos un poco inteligente y el poder de
un algoritmo de búsqueda de caminos, es bastante sencillo resolver el/los caminos
que satisfaga el problema con un grafo.
La capacidad de devolver como dos entidades, están conectados entre sı́, desde
dentro de la base de datos es una caracterı́stica exclusiva de las BDoG.
3.4. Modelado BDoG
Por último, una caracterı́stica en la que las BDoG no tienen rival es en su faci-
lidad para modelar y adaptarse a modelos cambiantes, modelar datos como un
grafo es natural y tiene la ventaja de ser legible incluso para personas sin conoci-
mientos técnicos.
En RDBMS lo habitual tras diseñar un modelo de datos es pasar a normalizarlo
para asegurarnos el correcto funcionamiento del modelo relacional sobre los datos,
pero el modelado usando BDoG es tan natural que el modelado puede hacerse sin
conocimientos técnicos explı́citos, puesto que el modelo de datos de la BDoG y el
de los datos que se quieren almacenar es, en la mayorı́a de los casos, el mismo (es-
ta afirmación es voluntaria y exageradamente simplista, pero refleja un hecho muy
cercano al mundo real).
Un ejemplo simplista: representar un problema comercial y las entidades asocia-
das.
26Figura 3.18: Modelo del negocio (simulando pizarra), recuperado de [3]
Luego, cuando se ha elegido el sistema de almacenamiento, se debe incorporar
el modelo de datos.
Si se elige una base de datos relacional, generalmente se comienza normalizando
el modelo para que cumpla con la tercera forma normal, y podrı́a verse ası́:
Figura 3.19: Modelo relacional, recuperado de [3]
Pero si uno elige modelar los datos con una BDoG, probablemente se verá ası́:
27Figura 3.20: Modelo de Grafo, recuperado de [3]
284. Cuándo usar BDoG
Como saber si es una buena opción usar BDoG, lo identificaremos de una manera
genérica.
Estamos de acuerdo en que el mundo real se describe fácilmente en términos de
grafos, pero decir que todo se resuelve con un tipo de base de datos es una simplifi-
cación drástica. El hecho de que un problema se pueda representar como un grafo no
significa necesariamente que una BDoG sea la mejor tecnologı́a para elegir resolver
ese problema.
El proceso comienza con una simple pregunta: ¿Qué problema estamos tratan-
do de resolver? Responder a esta pregunta proporciona detalles cruciales sobre qué
preguntas vamos a hacer, y esto rige los tipos de datos que necesitamos almacenar
y cómo debemos recuperarlos.
Desglosamos las respuestas en las siguientes categorı́as de problemas:
Selección - búsqueda.
Datos relacionados o recursivos.
Agregación.
La coincidencia de patrones.
Centralidad, agrupación e influencia.
4.1. Selección - búsqueda
Las preguntas sobre las selección-búsqueda se enfocan de manera estricta en
encontrar un pequeño conjunto de entidades que comparten un atributo común
como el nombre, la ubicación o el empleador:
¿Quiénes trabajan en X empresa?
¿Quién en mi sistema tiene un nombre como John?
¿Dónde están los comercios dentro de X kilómetros?
29Este tipo de preguntas no requieren relaciones ricas dentro de los datos. En la
mayorı́a de las bases de datos, responder a estas preguntas requiere utilizar un único
criterio de filtrado o, potencialmente, un ı́ndice.
Debido a que estos problemas no aprovechan las relaciones en nuestros datos, es
poco probable que valga la pena asumir las complejidades adicionales de las BDoG.
En este caso es recomendable usar RDBMS.
4.2. Datos relacionados o recursivos
Las preguntas que exploran las relaciones entre entidades agregan significado y
brindan valor topológico a los datos, proporcionando un caso de uso sólido para una
BDoG.
Algunos ejemplos de este tipo de preguntas incluyen:
¿Cuál es la forma más fácil de que me presenten a un ejecutivo de X empresa?
¿Cómo se conocen John y Paula?
¿Cómo se relaciona la empresa X con la empresa Y?
Las BDoG aprovechan esta información mejor que cualquier otro tipo de motor
de datos, y sus lenguajes de consulta son más adecuados para razonar sobre las re-
laciones dentro de los datos. Aunque no es imposible en bases de datos relacionales,
este tipo de consultas de amigos de amigos requieren complejas y difı́ciles de man-
tener o razonar sobre CTE recursivas o combinaciones complejas en muchas tablas
diferentes.
En este caso es recomendable usar BDoG.
4.3. Agregación
Las consultas de agregación de datos constituyen un excelente caso de uso para
una RDBMS. Las mismas están optimizadas para realizar consultas de agregación
complejas de forma rápida y con una sobrecarga mı́nima.
Las preguntas de ejemplo pueden incluir:
¿Cuántas empresas hay en mi sistema?
¿Cuáles son mis ventas promedio de cada dı́a durante el último mes?
¿Cuál es la cantidad de transacciones procesadas por mi sistema cada dı́a?
30Estos mismos tipos de consultas se pueden realizar en BDoG, pero la naturale-
za de los recorridos de grafos requiere que se toquen muchos más datos. Pero esto
provoca una mayor latencia de consulta y utilización de recursos.
En este caso es recomendable usar RDBMS.
4.4. Coincidencia de patrones
La coincidencia de patrones basada en cómo se relacionan las entidades es un
excelente ejemplo de cómo aprovechar el poder de las BDoG. Los casos de uso tı́pi-
cos para este tipo de consultas involucran cosas como motores de recomendación,
detección de fraude o detección de intrusiones.
Algunas preguntas pueden incluir:
¿Quién en mi sistema tiene un perfil similar al mı́o?
¿Esta transacción se parece a otras transacciones fraudulentas conocidas?
¿El usuario J. Smith es el mismo que Johan S.?
Los casos de uso de coincidencia de patrones se realizan con tanta frecuencia
en BDoG que los lenguajes de consulta de grafos tienen caracterı́sticas integradas
especı́ficas para manejar con precisión este tipo de consultas.
En este caso es recomendable usar BDoG.
4.5. Centralidad, agrupación e influencia
La influencia o importancia relativa de una entidad en comparación con otra es
un caso de uso tı́pico de una BDoG.
Algunas preguntas de ejemplo pueden incluir:
¿Quién es la persona más influyente con la que estoy conectado en LinkedIn?
¿Qué equipo de mi red tiene el impacto más sustancial si se rompe?
¿Qué partes tienden a fallar al mismo tiempo?
Ejemplos de otros problemas de este tipo incluyen encontrar a la persona más
influyente en una red de Twitter, identificar piezas crı́ticas de infraestructura o ubi-
car grupos de entidades dentro de sus datos.
Calcular las respuestas a este tipo de problemas requiere observar las entidades,
sus relaciones y las relaciones de incidentes y entidades adyacentes.
31Al igual que con los casos de uso de coincidencia de patrones, estos tipos de
problemas a menudo tienen caracterı́sticas especı́ficas de lenguajes de consulta de
grafo incorporados.
En este caso es recomendable usar BDoG.
4.6. Guı́a para decidir
¿Deberı́a usar una base de datos orientada a grafo? Desde el árbol de decisión
avanzamos contestando las preguntas hasta llegar a un estado de sı́, no o quizás.
Figura 4.1: Árbol de decisión – utilizar un BDoG, adaptado de [1]
32¿Nos preocupan las relaciones entre entidades tanto o más que las
propias entidades?
Esta pregunta es quizás la pista más crı́tica. Habla del corazón de una de las ca-
racterı́sticas más poderosas de las BDoG: las relaciones son tan significativas como
las entidades.
Si nuestra respuesta a esta pregunta es sı́, entonces probablemente necesitemos
un modelo de datos que permita representaciones sofisticadas de las relaciones, un
candidato excelente para usar una BDoG. Pero si nuestra respuesta es no, entonces
quizás otro motor de datos serı́a una mejor opción.
¿Mi consulta SQL realiza múltiples combinaciones en la misma tabla
o requiere un CTE recursivo?
Si bien una gran cantidad de combinaciones en una consulta SQL puede indicar
que una BDoG podrı́a ser una buena opción, no asegura esa posibilidad. Un gran
número de combinaciones en una consulta SQL suele ser un signo de un modelo
de datos bien normalizado. Pero cuando esas uniones no se utilizan para recuperar
datos de referencia (como se hace con una tercera forma normal en una base de
datos relacional) y, en cambio, se utilizan para vincular elementos juntos (como con
una relación padre-hijo), entonces es posible que deseemos considerar una BDoG.
Además, los patrones de consulta recursivos se benefician de las BDoG cuando
no sabemos el número de uniones que se realizarán.
¿La estructura de mis datos evoluciona continuamente?
Las RDBMS tienen una reputación bien merecida por la rigurosidad de su es-
quema y la complejidad asociada al realizar cambios de esquema.
Si su problema requiere tomar datos con diferentes esquemas de datos, entonces
vale la pena investigar una BDoG.
La flexibilidad con el esquema de datos por sı́ sola no deberı́a ser una razón
suficiente para elegir una BDoG, sin embargo, combinada con otras caracterı́sticas,
podrı́a ser suficiente para inclinar la balanza a favor del uso de una BDoG.
¿Es mi dominio un ajuste natural para un grafo?
Si está haciendo algo como enrutamiento, administración de dependencias, análi-
sis de redes sociales, etc. entonces su problema gira en torno a datos altamente in-
terconectados, por lo que su dominio puede ser adecuado para usar un grafo.
Una advertencia: aunque su dominio se modela naturalmente en un grafo, si
sus preguntas no se basan en las relaciones del grafo para las respuestas, entonces
33deberı́a considerar otras opciones.
4.7. Algunos usos de la BDoG
Las potencialidades múltiples de las BDoG las hacen atractivas para diferentes
tipos de proyectos. Existen condiciones especiales donde es casi obligatorio pensar
en implementar una.
Detección de fraude
Sirven para estudiar patrones relacionales que se presentan en las estrategias que
utilizan los delincuentes para cometer fraude.
Esta potencialidad es muy útil para empresas del sector financiero y bancario
donde es difı́cil ver por donde circula el dinero, sobre todo si se usan empresas pan-
talla o empresas en paraı́sos fiscales, testaferros, sociedades, etc. Al final tenemos un
conjunto de datos de diferentes fuentes, pero con relaciones directas o indirectas di-
ficultando el seguimiento del dinero y por tanto ocultando el fraude. Con un modelo
basado en grafos, nos facilita el trabajo pudiendo seguir la pista, sobre todo si hay
una representación visual de los datos, ejecutando consultas y búsquedas de los ele-
mentos, llegando a establecer las relaciones por donde haya podido circular el dinero.
Sistema de recomendación
Al tener la capacidad de mostrar las relaciones complejas entre vértices estas nos
brindan la posibilidad de establecer aristas entre personas e intereses.
Su implementación ha ayudado a las redes sociales a optimizar su funcionamien-
to.
También es una gran oportunidad para las empresas ya que con información de
esta clase pueden optimizar sus productos y servicios a los intereses de su público,
donde un cliente tiene una compra pendiente de un producto, y por relación de
similitud o proximidad de productos te ofrece otros para completar el pedido. Esto
se consigue gracias a que entre ambos productos existe una o varias relaciones.
Cálculo de rutas en logı́stica
Son capaces de aplicar el algoritmo del camino más corto, usando algoritmos de
Kruskal1 , Dijkstra2 o Prim3 . Lo que le facilita a la empresa el cálculo y reducción
de costos en la selección de las rutas.
1
https://es.wikipedia.org/wiki/Algoritmo de Kruskal
2
https://es.wikipedia.org/wiki/Algoritmo de Dijkstra
3
https://es.wikipedia.org/wiki/Algoritmo de Prim
34Relaciones sociales
Donde mayor uso se le puede dar y en donde mejor encajan.
En este caso hay múltiples ejemplos, desde temas relacionados con el cine, per-
sonajes, actores, directores, etc.
También lo podemos usar para modelar el conocimiento adquirido por los em-
pleados, que tecnologı́as conocen, en qué proyectos han estado trabajando, con qué
personas han estado trabajando.
Modelos de redes
Donde una red de sistemas o computadoras puede ser representado por un grafo.
355. Tipos de grafos
En el capı́tulo 3: Introducción a grafos vimos la definición de grafos.
Ahora veremos algunos tipos de grafos.
5.1. Grafo no dirigido
Un grafo no dirigido es un tipo de grafo en el cual las aristas representan rela-
ciones simétricas y no tienen un sentido definido.
Formalmente, se definen por un par de conjuntos G = (V, E), donde:
V 6= ∅ es el conjunto no vacı́o de vértices.
E ⊆ {(a, b) ∈ V xV } es el conjunto de aristas, tal que (a, b) = (b, a).
Figura 5.1: Grafo no dirigido con dos vértices y una arista, recuperado de [6]
5.2. Grafo dirigido
Un grafo dirigido es un tipo de grafo en el cual las aristas tienen un sentido
definido.
Formalmente, se definen por un par de conjuntos G = (V, E), donde:
V 6= ∅ es el conjunto no vacı́o de vértices.
E ⊆ {(a, b) ∈ V × V : a 6= b} es un conjunto de pares ordenados de elementos
de V donde una arista va del primer vértice (a) al segundo vértice (b).
36Figura 5.2: Grafo dirigido con tres vértices y tres aristas dirigidas, recuperado de [7]
5.3. Grafo con peso o ponderado
Es un grafo dirigido o no dirigido, donde las aristas tienen algún tipo de valora-
ción.
Figura 5.3: Grafo no dirigido con peso, recuperado de [8]
5.4. Grafo con etiquetas
Es un grafo dirigido o no dirigido, donde se incorporan etiquetas que pueden
definir los distintos vértices y también las aristas entre ellos.
Formalmente, dado un grafo G, un vértice etiquetado es una función que hace
corresponder vértices de G a un conjunto de etiquetas. De la misma manera, una
arista etiquetada es una función que hace corresponder aristas de G a un conjunto
de etiquetas.
Figura 5.4: Grafo dirigido con etiquetas en vértices y aristas
375.5. Grafo de propiedades
Es el más complejo, es un grafo con etiquetas y donde podemos asignar propie-
dades tanto a vértices como a sus aristas.
Figura 5.5: Grafo dirigido de propiedades, vértices con etiqueta “Person” y pro-
piedades (Id, Name, Age), aristas con etiqueta “Knows” y propiedades (Id, Since),
recuperado de [9]
5.6. Multigrafo
Los multigrafos pueden ser grafos no dirigidos o grafos dirigidos y con la combi-
nación de grafo con peso, grafos con etiquetas y/o grafos de propiedades.
Con la diferencia que las aristas pueden ser un conjunto en un mismo vértices o
entre un par de vértices.
Figura 5.6: Multigrafo con vértices que representan departamentos y sus aristas
distintas opciones de llegar al destino
386. Tipos de gestores de BDoG
6.1. Neo4j
Neo4j es la base de datos orientada a grafos más polular según db-engines.com1
a la fecha de este trabajo, es una plataforma de base de datos de grafos nativa que
está diseñada para almacenar, consultar, analizar y administrar datos altamente
conectados de manera eficiente.
6.1.1. Modelo de datos
El modelo de datos utilizado por Neo4j es un grafo de propiedades etiquetado
(ver Sección 5.5). Por tanto, las unidades básicas de procesamiento en Neo4j son:
vértices, aristas entre vértices, etiquetas que permiten definir el tipo de los vértices
y de las aristas y también las propiedades (definidas sobre vértices y/o aristas).
En Neo4j se utilizan los dos puntos “:” para representar las etiquetas. Las pro-
piedades se acostumbran a representarse en minúsculas.
Por otro lado, para distinguir fácilmente las etiquetas de vértices de las de aris-
tas, en Neo4j se escriben las etiquetas de aristas en mayúsculas y las etiquetas de
vértices con la primera letra en mayúscula y el resto en minúsculas.
Como ejemplo :Libro, :Persona y :HA LEÍDO entonces Libro y Persona son eti-
quetas de los vértices mientras que HA LEÍDO representa la etiqueta de la relación.
6.1.2. Restricciones de integridad
En Neo4j es posible aplicar ciertas restricciones de integridad sobre los esquemas.
Estas restricciones son:
Unicidad (UNIQUE): permite indicar que el valor de una propiedad debe
ser único para todos los vértices del mismo tipo.
Existencia: permite indicar que una propiedad (o un conjunto de ellas) debe
existir para todos los vértices de un tipo.
1
https://db-engines.com/en/ranking/graph+dbms
39Clave (PRIMARY KEY): permite indicar que una propiedad es clave para
todos los vértices de un determinado tipo, es decir, que todos sus vértices
deben tener definida la propiedad y que el valor de la propiedad es único.
6.1.3. Manejo de transacciones
Para mantener completamente la integridad de los datos y garantizar un buen
comportamiento transaccional, Neo4j admite las propiedades ACID (ver en el Capı́tu-
lo 10).
Interfaces de consultas
Neo4j permite acceder a sus datos de diversas formas:
Desde consola.
Un entorno web gráfico.
Mediante API.
Lenguaje de consultas
Neo4j permite consultar sus datos de distintos lenguajes de consulta:
Cypher, que es un lenguaje declarativo que permite consultar y manipular
grafos.
Gremlin, que es un lenguaje especı́fico de dominio para la gestión de grafos.
6.1.4. Almacenamiento fı́sico de la estructura de datos
Neo4j almacena los datos en una serie de archivos de almacenes diferentes, cada
archivo de almacén contiene una parte especı́fica del grafo, entre ellos:
Archivo de almacenamiento de vértices.
Archivo de almacenamiento de aristas.
Archivo de almacenamiento de propiedades.
Archivo de almacenamiento de tipos de relaciones.
Otros.
40Almacenamiento de vértices
Este archivo como su nombre lo indica solo almacena registro de vértices y el
nombre fı́sico es neostore.nodestore.db.
Es un almacenamiento de registros fijos donde cada registro tiene 9 bytes de
longitud. Esto le permite a Neo4j búsquedas rápidas en este archivo con un costo
de O(1).
Figura 6.1: Neo4j registro de vértice de largo fijo (9 bytes)
En la Figura 6.1 tenemos un registro del vértice donde el byte 1 es la marca de
uso, indica si el registro se esta usando actualmente los siguientes bytes del 2 al 5
(4 bytes) contiene el identificador del primer registro de la arista y el resto del 6 al
9 (4 bytes) identifica el registro de la primera propiedad.
Resumiendo, el registro del vértice es un par de punteros a listas de aristas y
propiedades identificando el primero de cada lista.
Almacenamiento de aristas
Este archivo como su nombre lo indica solo almacena registro de aristas y el
nombre fı́sico es neostore.relationshipstore.db.
Al igual que el registro de vértices, el registro de aristas es de longitud fija de 33
bytes. Con el cual Neo4j consulta con un costo de O(1).
41Figura 6.2: Neo4j registro de arista de largo fijo (33 bytes)
En la Figura 6.2 es un registro de arista donde el 1 byte es la marca de uso con
la misma funcionalidad de la marca de uso para el registro de vértice. Los bytes
siguientes del 2 al 5 (4 bytes) tiene el identificador al vértice inicial y los otros 4
bytes del 6 al 9 el identificador del vértice final. Los bytes del 10 al 13 (4 bytes) el
identificador de tipos de aristas (que también están en un archivo de almacenamien-
to). El resto de los bytes del 14 al 29 (16 bytes) tiene el identificador de las aristas
anterior y siguiente de cada vértice inicial y final mientras que los bytes del 30 al 33
(4 bytes) es el identificador a la primera propiedad.
Punteros de los registros vértices-aristas
Figura 6.3: Neo4j estructura de punteros, recuperado de [10]
En la Figura 6.3 se visualiza como interactúan los distintos archivos de almace-
namiento en disco. Cada registro de los 2 vértices contiene un puntero a la primera
propiedad y relación en una cadena de relaciones.
Para leer las propiedades de un vértice como arista se sigue la estructura de lista
simples enlazadas comenzando con el puntero a la primera propiedad.
42Para leer las aristas de un vértice se sigue la estructura de lista doblemente enla-
zadas comenzando con el puntero a la primera arista. En el caso particular de querer
leer una arista determinada, seguimos el mismo procedimiento y al encontrarla po-
demos leer sus propiedades (si las tiene) o se puede examinar los dos registros de los
vértices que conecta esa arista mediante sus identificadores de vértice inicial y vérti-
ce final. Estos identificadores multiplicados por el tamaño del registro del vértice (9
bytes) obtenemos el desplazamiento inmediato en el archivo de almacenamiento de
vértices.
Al tener las aristas con la estructura de listas dobles enlazadas permite recorrer
en cualquier dirección e insertar y eliminar de forma eficiente.
6.1.5. Datos en cache
Representados por dos objetos en memoria: vértices y aristas.
Las representaciones de las propiedades tanto en vértices como en aristas son de
clave, valor.
Los objetos de vértices agrupan sus aristas por tipo de relación y su dirección,
si son entrantes o salientes.
Figura 6.4: Neo4j – estructura minimalista de nodo y relación, mostrando el ciclo
para recorrer todos los nodos de algún tipo de relación
43Para entender esto supongamos que tenemos un grafo que representa las relacio-
nes de amistad entre personas, las ciudades donde viven y el automóvil que manejan.
Como se aprecia en la Figura 6.5. Se puede observar en cada relación el id que es la
referencia directa a dicha relación.
Figura 6.5: Neo4j - ejemplo nodos y relaciones
Suponiendo que queremos obtener los amigos de Miguel, tenemos los tipos de
relación ES AMIGO, VIVE EN y CONDUCE, pero solo nos interesa la relación de
amistad los demás tipos se descartan y se itera sobre la lista de salida y se obtienen
los vértices Carlos, Luis, Ana de forma directa.
Figura 6.6: Neo4j - ejemplo del ciclo para obtener los amigos
446.2. ArangoDB
ArangoDB se encuentra en el puesto 3 del grupo BDoG db-engines.com2 .
Es una plataforma de base de datos diseñada para almacenar datos de forma
nativa como grafo, pares clave-valor y documentos a los que se puede acceder con
un lenguaje de consulta único.
6.2.1. Modelo de datos
Es una base de datos multi-modelo porque combina los modelos clave/valor, do-
cumentos y grafos en un solo núcleo desarrollado en C++. Poseé un lenguaje de
consulta unificado AQL (ArangoDB Query Language) que permite realizar consul-
tas entre los diferentes modelos de datos indistintamente. Soporta un multigrafo
dirigido de propiedades.
Tanto las aristas como los vértices son colecciones de documentos en formato
JSON.
Figura 6.7: ArangoDB – vertices y aristas en formato JSON, recuperado de [11]
6.2.2. Restricciones de integridad
Solo cuenta con la clave primaria (atributo Key), pero se pueden definir otras
cumpliendo ciertas restricciones definidas por ArangoDB3 .
6.2.3. Manejo de transacciones
ArangoDB soporta transacciones ACID (ver en el Capı́tulo 10), las transacciones
son siempre operaciones del lado del servidor.
2
https://db-engines.com/en/ranking/graph+dbms
3
https://www.arangodb.com/docs/stable/data-modeling-naming-conventions-document-
keys.html
45Se realiza con una función de JavaScript db. executeTransaction(object) donde
object contiene diferentes atributos (colecciones, acción, opcionales).
Índices
ArangoDB indexa automáticamente algunos atributos del sistema y también per-
mite crear ı́ndice a los usuarios, pero a nivel de colección. Los ı́ndices son:
Índices persistentes
Es un ı́ndice ordenado con persistencia en disco.
Índices TTL
Se puede utilizar para eliminar automáticamente documentos caducados en la co-
lección.
Índices de texto completo
Para indexar texto completo dentro de los documentos.
Índices geográficos
Índice que almacena coordenadas bidimensionales con los atributos latitud y longi-
tud que tienen que ser de tipos numéricos.
Índices centrados en vértices
Son los mas importantes para el grafo donde se indexan los atributos de las aristas
(atributos from y to). Proporcionan un acceso rápido a todas las aristas que se
originan o llegan a un vértice dado y permiten encontrar rápidamente los vecinos de
un vértice en el grafo.
Interfaces de consultas
La gestión de la base de datos se pueden hacer a través de las interfaces:
Web.
ArangoSH.
REST/ API.
Lenguaje de consultas
El lenguaje de consulta de ArangoDB es declarativo y permite la combinación de
diferentes patrones de acceso a datos en una sola consulta AQL (ArangoDB Query
Lenguage).
466.2.4. Almacenamiento fı́sico de la estructura de datos
ArangoDB tiene una estructura distinta para el almacenamiento del grafo donde
se cuestiona el ı́ndice de adyacencia4 . Este usa un hı́brido entre ı́ndice y lista doble-
mente encadena.
El almacenamiento de los vértices está referenciado a un hash que fue creado por
la clave del vértice. De igual forma se almacenan las aristas.
Cada vértice tiene referencia al identificador de la primera arista en el hash de
aristas, y las aristas siguientes están en la estructura de lista doblemente encadenada,
recorriendo la lista se obtiene todas sus relaciones.
Figura 6.8: ArangoDB – Hash hı́brido con listas vinculadas - ı́ndices, adaptado de
[12]
6.3. TerminusDB
TerminusDB se encuentra en el puesto 25 (mayo 2021) del grupo BDoG de db-
engines.com5 . Es una plataforma de base de datos de grafos en memoria.
4
https://en.wikipedia.org/wiki/Talk:Graph database#Changed opening paragraph
5
https://db-engines.com/en/ranking/graph+dbms
476.3.1. Modelo de datos
Es un grafo dirigido de propiedades etiquetados.
Figura 6.9: TerminusDB – grafo de propiedades, recuperado de [13]
En TerminusDB todo es un objeto de una clase. Los objetos pueden tener pro-
piedades, y las propiedades pueden vincularse a otros objetos.
De la Figura 6.9 se identifican 4 estructuras principales:
OrdinaryClass.
DocumentClass (doc:Person).
ObjectProperty (knows:doc:Person).
DatatypeProperty (name:String).
Las clases de documentos son clases de nivel superior. Continuando con la Figu-
ra 6.9 los vértices Marı́a , Anna , Tom y Jim son objetos de documento. knows es
una propiedad de objeto y con alcance al documento de persona.
Las clases pueden ser subclases de otras clases, lo que significa que heredan todas
las propiedades de los padres (al igual que la herencia en la programación orientada
a objetos). Se admite también la herencia múltiple.
El tipo de datos al que apunta la propiedad puede ser un simple literal de tipo
de datos DatatypeProperty o puede ser una clase ObjectProperty.
TerminusDB es una base de datos de grafos que almacena datos como Git con los
mismos beneficios como tener registro de quienes hicieron confirmaciones, permite
volver a un estado anterior y la mayor motivación de TerminusDB es poder clonar
el conjunto de datos y hacer las modificaciones necesarias y sincronizar los datos
para dejarlo en el nuevo estado, esto permite que diferentes desarrolladores pueden
48También puede leer

















































