Predicción de criptomonedas con técnicas de Deep Learning - Grado en Ingeniería Informática Trabajo Fin de Grado
←
→
Transcripción del contenido de la página
Si su navegador no muestra la página correctamente, lea el contenido de la página a continuación
Predicción de criptomonedas
con técnicas de Deep Learning
Grado en Ingeniería Informática
Trabajo Fin de Grado
Autor:
Anton Chernysh
Tutor/es:
Antonio Javier Gallego Sánchez
Jorge Calvo Zaragoza
Mayo 2021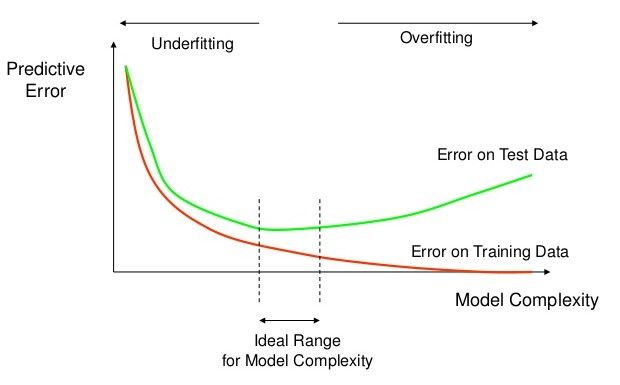
Predicción de criptomonedas con
técnicas de Deep Learning
-
Autor
Anton Chernysh
Directores
Jorge Calvo Zaragoza
Dpto. Lenguajes y Sistemas Informáticos
Antonio Javier Gallego Sanchez
Dpto. Lenguajes y Sistemas Informáticos
G RADO EN I NGENIER ÍA I NFORM ÁTICA
Alicante, Spain, 1 de junio de 2021
Justificación y Objetivos Este trabajo aborda el estudio de distintas técnicas de Deep Learning para la predic- ción de series temporales. Para hacer este estudio, usaremos los datos históricos de la criptomoneda Ethereum con un periodo de vela de cinco minutos. Realizaremos un análisis de los datos y extrae- remos nueva información a partir de algunos indicadores técnicos. Finalmente, estudia- remos distintos tipos de arquitecturas neuronales y llevaremos a cabo una comparativa de su rendimiento. Aunque en este documento aplicamos el estudio sobre el mercado de las criptomo- nedas, este trabajo es extrapolable a cualquier otro mercado de valores como el bursátil, e incluso a otro tipo de datos de series temporales.

Agradecimientos En esta sección quisiera agradecer a Darı́o, Marı́a y Carlos por ser las personas que más me han apoyado y las que más me han enseñado en los últimos años. Por último agradecer a mis tutores, Jorge Calvo y Antonio Javier Gallego Sánchez, por ayudarme y guiarme durante este trabajo.
Si compras cosas que no necesitas,
pronto tendrás que vender las cosas que necesitas.
Warren Buffet.
VIÍndice general
1 Introducción 1
1.1 Motivación . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.2 Objetivos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.3 Estructura del trabajo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2 Introducción a los mercados financieros 6
2.1 Análisis fundamental . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.2 Análisis técnico . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.2.1 Teorı́a de Dow . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.3 Velas japonesas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.3.1 Retorno de vela . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.4 Portafolio . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.5 Drawdown . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.6 Conclusiones del capı́tulo . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
3 Fundamentos sobre Aprendizaje Automático 12
3.1 Machine Learning . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
3.2 Deep Learning . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
3.2.1 Arquitectura de una neurona . . . . . . . . . . . . . . . . . . . . . 14
3.2.2 Función de Activación . . . . . . . . . . . . . . . . . . . . . . . . . 16
3.3 Entrenamiento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
3.3.1 Funciones de pérdida . . . . . . . . . . . . . . . . . . . . . . . . . 18
3.3.2 Evaluación . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
3.4 Series temporales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
4 Metodologı́a 23
4.1 Análisis de datos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
4.1.1 Preprocesado básico . . . . . . . . . . . . . . . . . . . . . . . . . . 24
4.1.2 Extracción de información . . . . . . . . . . . . . . . . . . . . . . . 24
4.1.3 Técnicas trigonométricas . . . . . . . . . . . . . . . . . . . . . . . 27
4.1.4 Escalado y normalización de los datos . . . . . . . . . . . . . . . . 28
4.1.5 Conclusiones del la sección de Análisis . . . . . . . . . . . . . . . 30
4.2 Arquitecturas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
4.2.1 Arquitectura MLP . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
4.2.2 Arquitectura Residual . . . . . . . . . . . . . . . . . . . . . . . . . 31
VIIÍndice general VIII
4.2.3 Arquitecturas recurrentes . . . . . . . . . . . . . . . . . . . . . . . 32
4.3 Pipeline . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
4.3.1 Split de datos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
4.3.2 Entrenamiento y la evaluación de los modelos . . . . . . . . . . . 37
4.4 Tecnologı́as . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
4.4.1 Librerı́as . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
4.4.2 Hardware . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
5 Experimentación 40
5.1 Parámetros de entrenamiento . . . . . . . . . . . . . . . . . . . . . . . . . 40
5.2 Modelo Base Naive . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
5.3 Modelo Dense . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
5.4 Modelo Dense Residual . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
5.5 Modelo LSTM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
5.6 Modelo LSTM Residual . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
5.7 Modelo GRU . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
5.8 Modelo GRU Residual . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
5.9 Modelo TCN . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
5.10 Modelo TCN-MLP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
5.11 Modelo TCN-RNN . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
5.12 Modelo TCN-RNN-MLP . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
5.13 Backtesting . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
5.14 Resultados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
6 Conclusiones y trabajos futuros 54
Bibliografı́a 57
Lista de Acrónimos 58Índice de figuras
2.1 Ejemplo de análisis técnico (Binance). . . . . . . . . . . . . . . . . . . . . 7
2.2 Anatomı́a de las velas japonesas. . . . . . . . . . . . . . . . . . . . . . . . 9
2.3 Drawdown en la rentabilidad de un portafolio. . . . . . . . . . . . . . . . 10
3.1 Arquitectura de una red neuronal. . . . . . . . . . . . . . . . . . . . . . . 14
3.2 Arquitectura de una neurona. . . . . . . . . . . . . . . . . . . . . . . . . . 15
3.3 Puertas lógicas con neuronas. . . . . . . . . . . . . . . . . . . . . . . . . . 16
3.4 Descomposición de los datos con periodos de una semana. . . . . . . . . 21
4.1 Relación del error y la complejidad de la red. . . . . . . . . . . . . . . . . 25
4.2 Coseno aplicado a los datos de fecha con ciclos de una semana y un año. 28
4.3 Bloque residual. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
4.4 Arquitectura de una célula LSTM. . . . . . . . . . . . . . . . . . . . . . . 33
4.5 Arquitectura de una célula GRU. . . . . . . . . . . . . . . . . . . . . . . . 34
4.6 Ejemplo de aplicación de un filtro de convolución. . . . . . . . . . . . . . 34
4.7 CNN para detección de caras. . . . . . . . . . . . . . . . . . . . . . . . . . 35
4.8 Splits de datos. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
5.1 Modelo Dense. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
5.2 Modelo Dense Residual. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
5.3 Modelo LSTM. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
5.4 Modelo LSTM Residual. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
5.5 Modelo GRU. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
5.6 Modelo GRU Residual. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
5.7 Modelo Convolucional. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
5.8 Modelo TCN-MPL. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
5.9 Modelo TCN-RNN. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
5.10 Modelo TCN-RNN-MLP. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
5.11 Relación entre las métricas obtenidas respecto al MAE. . . . . . . . . . . 52
IXÍndice de tablas
3.1 Puertas logicas OR y XOR. . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
5.1 Parámetros de configuración de la simulación de backtesting. . . . . . . 49
5.2 Resultado de los modelos estudiados. . . . . . . . . . . . . . . . . . . . . 51
XÍndice de Listados
5.1. Pseudocodigo del algoritmo de backtesting . . . . . . . . . . . . . . . . . 50
XI1 Introducción
Actualmente nos encontramos en una época donde el mundo de Inteligencia Arti-
ficial esta en auge y hasta las empresas más pequeñas quieren explotarlo. A pesar de
haber sido acuñado por primera vez a mitades del siglo XX por Alan Turing, no se ha
hecho tan popular hasta los últimos años gracias a los recientes avances en las tarjetas
gráficas que permitı́an reducir en gran medida su tiempo de cómputo. La popularidad
de estos algoritmos se debe a que son capaces de perfeccionarse en base a ”entrena-
mientos”, llegando a reemplazar por completo a un humano. En este trabajo estudia-
remos y experimentaremos con las últimas técnicas de Deep Learning, un subárea del
Aprendizaje Automático.
Otro sector que también ha sido muy popular en los últimos años es el de las crip-
tomonedas. Se trata de una divisa digital que surge como alternativa a la moneda tra-
dicional. Este criptoactivo utiliza criptografı́a fuerte para asegurar las transacciones,
controla la creación de unidades adicionales y verifica la transferencia usando tecno-
logı́as de registro distribuido. El control de cada moneda funciona a través de una base
de datos descentralizada mediante cadena de bloques (blockchain en inglés).
Desde el surgimiento de la primera criptomoneda, Bitcoin, en 2009, su valor y el de
muchas otras ha aumentado drásticamente. Este evento ha provocado que tanto inver-
sores profesionales como aficionados se interesaran por la inversión, las criptomonedas
y su funcionamiento. En este trabajo vamos a unir estas dos tecnologı́as y ver lo que po-
demos lograr.
1Introducción 2
1.1. Motivación
Durante los últimos dos años me he interesado mucho por otros tipos de conocimien-
to fuera de mi área de estudios, como el emprendimiento y la inversión. Esto, sumado a
mi personalidad competitiva, me han llevado al mundo del trading. El trading se puede
definir como un conjunto de técnicas y estrategias de compra y venta con el objetivo
de aprovechar o intentar predecir el estado de un valor y, a diferencia de la inversión
tradicional, este busca beneficios a corto plazo. Los mercados donde se negocian estos
valores son cada vez más complejos debido al alto nivel competitivo que hay entre las
personas y empresas que participan en él. Además, es considerado totalmente impre-
decible tal como la defiende la Efficient-market hypothesis 1 .
Por ello, a lo largo de este trabajo vamos a estudiar el uso y aplicaciones que tienen las
técnicas de Deep Learning en la capacidad de estimar el precio de un valor en el futuro.
En los últimos años estas técnicas nos ha demostrado que podemos detectar patrones o
caracterı́sticas en los datos que un humano no puede. Además, a veces el precio de un
valor no sube o baja sin motivo, sino que está influenciado principalmente por factores
externos como las noticias o publicaciones de gente influyente como Elon Musk, que
con una simple palabra son capaces de hacer que el precio de una criptomoneda como
Dogecoin suba más del 100 % en tan solo un dı́a.
Como podemos ver se trata más de algo sociológico que simple aleatoriedad. Es por
esto que realizaremos este estudio a partir de las siguientes ideas:
1. Los mercados no son aleatorios.
2. La historia se repite.
3. Los mercados siguen el comportamiento racional de las personas.
1
Esta hipótesis establece que los precios de los activos reflejan toda la información disponible y que es
imposible ”ganarle al mercado”de manera consistente, ya que los precios del mercado solo deberı́an
reaccionar ante nueva informaciónIntroducción 3
1.2. Objetivos
Los principales objetivos de este trabajo son los siguientes:
1. Estudio y análisis de los mercados financieros. Como veremos en el capı́tulo 2 de
introducción a los mercados financieros, existen dos grandes ramas de las cuales
nos centraremos solo en el de análisis técnico.
2. Conocer el estado del arte sobre el aprendizaje automático. Estudiaremos las
diferentes arquitecturas que se emplean y como emplearlas para abordar nuestro
problema.
3. Implementación y experimentación de las distintas arquitecturas de Deep Lear-
ning utilizando las librerı́as de gran relevancia como TensorFlow y Keras.
4. Evaluación y comparativa del rendimiento de los modelos implementados. Es-
tudiaremos las distintas funciones y métricas mas utilizadas para la regresión de
series temporales.
5. Combinar nuestro modelo de predicción con la implementación de un algo-
ritmo de trading. Realizaremos una simulación de nuestros modelos sobre los
mercados financieros mediante un algoritmo de backtesting .Introducción 4
1.3. Estructura del trabajo
Para facilitar su lectura, el contenido de este documento se encuentra organizado en
capı́tulos y secciones. A continuación se describe la estructura que vamos a seguir.
Capı́tulo 1: Introducción ⇒ Capı́tulo introductorio que abarca los fundamentos
del proyecto y describe los objetivos que se pretenden alcanzar.
Capı́tulo 2: Introducción a los mercados financieros ⇒ Breve introducción a los
mercados financieros.
Capı́tulo 3: Fundamentos sobre Aprendizaje Automático ⇒ Proporciona una ba-
se teórica general del ámbito de Machine Learning y su papel en el problema a
resolver.
Capı́tulo 4: Metodologı́a ⇒ Capı́tulo que abarca las arquitecturas neuronales es-
tudiadas, las distintas transformaciones aplicadas a los datos y la estrategia utili-
zada para abordar el problema.
Capı́tulo 5: Experimentación ⇒ Descripción de los experimentos realizados y los
resultados obtenidos.
Capı́tulo 6: Conclusiones y trabajos futuros ⇒ Reflexiones sobre los resultados
obtenidos y de posibles trabajos futuros a abordar.2 Introducción a los mercados financieros
Para poder entender la complejidad del problema a resolver, es necesario tener unos
conceptos básicos previos sobre los mercados financieros. Estos, se pueden definir como
un espacio a través del cual se intercambian activos financieros, donde los participantes
son los que definen los precios de dichos activos. Un mercado financiero esta regido por
la Ley de la Oferta y la Demanda. Es decir, cuando alguien quiere adquirir algo a un
precio determinado, sólo lo podrá comprar si hay otra persona dispuesta a venderlo a
ese mismo precio.
Por otro lado, está el análisis de los mercados financieros, cuyo objetivo es extraer
información que nos permita conocer la evolución de un activo en el futuro. Este a su
vez, se puede dividir en dos grandes ramas principales: el análisis fundamental y el
análisis técnico.
2.1. Análisis fundamental
El objetivo del análisis fundamental es intentar establecer un precio teórico de un
activo a través del estudio de las variables que afectan a su valor. En caso de que el
valor teórico sea mayor al real, significa que su valor está infravalorado y tiene un
gran potencial de revalorización de cara al futuro. Las variables que se incluyen en este
estudio son muchas, pero las más importantes suelen ser los resultados financieros de
la empresa, noticias financieras o polı́ticas, y opiniones públicas de gente influyente.
Como podemos ver, la mayorı́a de estas variables no son cuantitativas, por lo que
realmente no hay una forma objetiva de obtener su valor. Por tanto, varios análisis
pueden llegar a distintos resultados, concluyendo algunos de ellos que el valor del
activo está infravalorado y otros que está sobrevalorado. Por otra parte, esto es lógico,
ya que para que se realice una operación, debe haber alguien que quiera comprarlo y
otro venderlo al mismo precio.
6Introducción a los mercados financieros 7
2.2. Análisis técnico
A diferencia del análisis fundamental, el análisis técnico no pretende calcular el valor
teórico del activo, sino de encontrar patrones de comportamiento en la evolución de su
cotización, basándose en sus datos históricos. Se trata de un análisis más gráfico, que
permite visualizar las tendencias a lo largo del tiempo. Además, utiliza una serie de
indicadores u osciladores que permiten extraer nueva información que a simple vista
no se ve.
Al igual que con el análisis fundamental, no se trata de ciencia exacta, y dos analistas
pueden llegar a conclusiones diferentes. Estos dos análisis son muy distintos, pero en
la práctica, se utilizan ambos ya que se complementan y permiten obtener más infor-
mación. El análisis fundamental se puede ver como un análisis a largo plazo, ya que
no sabes cuándo se va alcanzar el valor teórico. En cambio, el análisis técnico es más a
corto plazo, que nos permite detectar el mejor momento para realizar cierta operación
y ası́ incrementar las posibilidades de obtener beneficios.
Figura 2.1: Ejemplo de análisis técnico (Binance).Introducción a los mercados financieros 8
2.2.1. Teorı́a de Dow
La teorı́a de Dow constituye el origen de lo que hoy se conoce como análisis técnico.
Los principios básicos de la teorı́a de Dow se resumen en estos 5 puntos:
1. El precio lo refleja todo. Toda la información pasada, presente e incluso futura,
como las noticias, inflación y expectativas están incluidas y reflejadas en los pre-
cios.
2. El precio se mueve por tres principales tendencias:
La tendencia primaria: periodos entre uno y tres años.
La tendencia secundaria: periodos mensuales o semanales.
La tendencia terciaria: periodos diarios.
3. Las tendencias primarias tienen tres fases.
4. El volumen debe confirmar la tendencia.
5. La tendencia se mantiene hasta que no se demuestre lo contrario. Es decir, hasta
que no haya una nueva tendencia en sentido contrario.
2.3. Velas japonesas
Las velas japonesas no es mas que una forma de representar el precio de un valor en
el mercado y es uno de los componentes más conocidos del análisis técnico. Gracias a
esta representación, podemos reflejar el precio en diferentes intervalos de tiempo, per-
mitiendo obtener una visualización gráfica de como evoluciona su negociación. Existen
dos tipos de velas: velas alcistas y velas bajistas. Como podemos ver en la figura 2.2, la
principal diferencia entre ambas es su color. En caso de que el precio de cierre (Close)
es superior al de apertura (Open), la vela indica una subida en el precio durante ese
periodo de tiempo y será de color verde. En caso contrario, será roja.Introducción a los mercados financieros 9
Figura 2.2: Anatomı́a de las velas japonesas.
2.3.1. Retorno de vela
El retorno de vela hace referencia a las ganancias o pérdidas de una inversión después
de un periodo de tiempo. Este retorno puede ser simple o porcentual.
ret.simple = preciot+1 − preciot (2.1)
preciot+1 − preciot
ret.porcentual = ∗ 100 (2.2)
preciot
2.4. Portafolio
El portafolio de inversión, también llamado cartera de inversión, es un conjunto de
activos financieros que posee una persona. Es común intentar diversificarlo en diferen-
tes sectores y que en su conjunto te permita multiplicar tu patrimonio a lo largo de los
años.
Más adelante veremos como se puede comparar el rendimiento de los modelos si-
mulando un portafolio y aplicando una estrategia simple de compra y venta.Introducción a los mercados financieros 10
2.5. Drawdown
Durante nuestro periodo de inversión, el valor de nuestro portafolio puede entrar
en una racha de pérdidas que se ven reflejadas como grandes caı́das en la gráfica. El
Drawdown es una medida que representa el máximo retroceso en la curva del valor
respecto al máximo anterior. En el campo del trading, esta medida permite evaluar el
riesgo de una estrategia.
Figura 2.3: Drawdown en la rentabilidad de un portafolio.
2.6. Conclusiones del capı́tulo
Esta breve introducción es necesaria para introducir al lector a los mercados financie-
ros, conocer los datos con los que vamos a trabajar y poder entender mejor las gráficas
en los siguientes capı́tulos.3 Fundamentos sobre Aprendizaje
Automático
En este capı́tulo vamos a explicar un poco en más detalle el problema del que trata
este estudio, las técnicas actuales que se usan y el enfoque que vamos a tomar para
resolverlo. Para terminar, realizaremos un breve estudio acerca de cómo medir y com-
parar el rendimiento de nuestro algoritmo.
3.1. Machine Learning
En informática, un programa o algoritmo, se define como una lista de instrucciones
finitas y ordenadas que permiten la resolución de un problema determinado. Cuando
el algoritmo depende de información externa y no conocida a priori, es necesario espe-
cificar una respuesta para cada caso posible y, en caso de no hacerlo, el programa puede
fallar provocando una respuesta imprevisible y errónea.
A mediados del siglo XX se crea una nueva disciplina de las ciencias de la informa-
ción llamada Inteligencia Artificial. Surge con la intención de crear un sistema capaz de
aprender y desarrollar una inteligencia como la de un humano y que permita simular
su comportamiento. Desde entonces, se han creado una gran cantidad de algoritmos
que se pueden considerar ”inteligentes” lo que ha llevado a crear distintas categorı́as
de acuerdo a sus propiedades y a los tipos de problemas que pueden solucionar.
El subcampo de la Inteligencia Artificial más conocido es Machine Learning[1] (ML).
Este área de estudio cuenta con algoritmos capaces de aprender analizando distinta
información, permitiendo al programa adaptarse a nuevas situaciones nunca vistas y
responder apropiadamente sin ser explı́citamente programadas.
Este campo se puede dividir en tres grandes grupos según el tipo de aprendizaje:
Aprendizaje supervisado: el aprendizaje se realiza a partir de casos de ejemplo
que están etiquetados, de manera que cuando el programa comete un error, pode-
mos medirlo y modificar nuestro modelo durante el entrenamiento. Gracias a que
12Fundamentos sobre Aprendizaje Automático 13
los datos están etiquetado y que podemos saber cuánto nos hemos equivocado, el
algoritmo puede aprender de manera mucho más rápida que usando el resto de
técnicas. Esta rama a su vez se puede dividir en dos grupos:
• Clasificación: la predicción se realiza sobre un conjunto limitado de cate-
gorı́as o clases. Por ejemplo clasificación de imagen para distinguir entre
distintos tipos de animales.
• Regresión: la predicción consiste de un valor numérico. Por ejemplo predecir
el numero de ventas de una tienda.
Aprendizaje no supervisado: a diferencia del supervisado, este no tiene informa-
ción etiquetada. Este algoritmo no intenta ajustarse a los datos de entrada y salida,
sino en aumentar el conocimiento estructural de los datos disponibles. Los casos
de uso podrı́an ser el agrupamiento de los datos según su similitud (clustering) o
detección de anomalı́as.
Aprendizaje reforzado: al igual que el no supervisado este tampoco tiene infor-
mación etiquetada. Se trata de un agente que explora un entorno desconocido y
aprende a base de comportamientos de prueba y error. En caso de cumplir una ta-
rea, es recompensado, y en las siguientes iteraciones intentará realizar la tarea de
la manera más óptima para obtener la máxima recompensa. Este tipo de apren-
dizaje es el más similar a como aprende el ser humano, y de la misma manera
necesita de muchas iteraciones para aprender. Los casos de uso mas comunes es
en videojuegos, donde el agente se dedica a jugar al videojuego durante muchas
iteraciones y evolucionando en cada una de ellas. Para optimizar su tiempo de
computo se realizan diferentes simulaciones en paralelo y se mezclan las mejores
versiones, lo que recibe el nombre de algoritmos genéticos.Fundamentos sobre Aprendizaje Automático 14
3.2. Deep Learning
A pesar de que la Inteligencia Artificial busca imitar el comportamiento humano, los
algoritmos tradicionales de ML siguen un enfoque racional y emplean métodos ma-
temáticos y estadı́sticos para solucionar un determinado problema. Con la intención de
conseguir imitar mejor el aprendizaje humano, se crean los modelos neuronales.
Deep Learning (DL) es un área dentro del Machine Learning que consiste en una
jerarquı́a de neuronas interconectadas, denominadas redes neuronales, que permiten
detectar patrones y caracterı́sticas más complejas que el ML.
Figura 3.1: Arquitectura de una red neuronal.
3.2.1. Arquitectura de una neurona
Las neuronas de las que están formadas estas redes funcionan de manera similar que
la de nuestros cerebros y se pueden representar como funciones lineales que reciben
datos y devuelven otros. Como se puede ver en la figura 3.2 el funcionamiento de la
neurona consiste en una suma ponderada de los datos de entrada y los pesos de la
neurona. Al resultado se le añade un peso extra denominado bias para modificarlo de
forma directa y, finalmente, se le aplica una función de activación que, además de mo-
dificar el valor, facilita durante el entrenamiento calcular el grado de influencia de la
neurona sobre el resultado final. Este resultado lo reciben como dato de entrada todas
las neuronas de la siguiente capa, y ası́ hasta obtener el resultado final.Fundamentos sobre Aprendizaje Automático 15
Figura 3.2: Arquitectura de una neurona.
Ahora bien, estas neuronas por si solas no son capaces de resolver todos los pro-
blemas. Por ejemplo imaginemos que queremos realizar un algoritmo que simule el
comportamiento de una puerta lógica. Para este ejemplo vamos a utilizar las puertas
lógicas OR y XOR. Su funcionamiento se puede ver en la tabla 3.1. Como podemos en
la figura 3.3, en el caso de la puerta OR es fácil, solo necesitamos una linea (función)
para poder dividir el espacio y ası́ distinguir entre un grupo u otro (rojo representa
el 0 y verde el 1). En cambio para la puerta XOR es imposible de lograrlo empleando
solamente una función. Es aquı́ donde necesitamos emplear una segunda neurona que
permita al modelo ajustarse mejor a los datos.
Entrada 1 Entrada 2 OR XOR
0 0 0 0
0 1 1 1
1 0 1 1
1 1 1 0
Tabla 3.1: Puertas logicas OR y XOR.Fundamentos sobre Aprendizaje Automático 16
Figura 3.3: Puertas lógicas con neuronas.
3.2.2. Función de Activación
Las funciones de activación no son mas que funciones no lineales que se le aplican a
la salida de la neurona. Gracias a estas funciones la red es capaz de detectar patrones no
lineales. Otra caracterı́stica importante es que durante el entrenamiento estas funciones
nos permiten calcular de manera mas sencilla la responsabilidad que ha tenido cada
neurona en la solución final, para ası́ poder saber cuanto hay que ajustar sus pesos. Las
funciones de activación más usadas son las siguientes:
Sigmoide: para cualquier valor de x, esta función devuelve su correspondiente
valor en el rango de [0, 1]. Su principal uso se encuentra en la última capa de sali-
da. Gracias a su rango de valores que devuelve, podemos utilizar las predicciones
resultantes como probabilidades que muestras la certeza de la predicción.
1
sigmoide(x) = (3.1)
1 + e−t
Hyperbolic tangent (Tanh): para cualquier valor de x, esta función devuelve su
correspondiente valor en el rango de [-1, 1].
ex − e−x
tanh(x) = (3.2)
ex + e−x
Rectified Linear Unit (ReLU): esta función es la mas simple y a su vez la masFundamentos sobre Aprendizaje Automático 17
usada. Para una x positiva devuelve el mismo valor, y en caso contrario devuelve
cero.
x x>0
relu(x) = (3.3)
0 otherwise.
3.3. Entrenamiento
Cuando decimos que el modelo aprende, lo que realmente está haciendo es ajustarse
a los datos que recibe con el objetivo de obtener un resultado lo más parecido posi-
ble al valor real. El proceso de ajuste se denomina entrenamiento de la red y consiste
principalmente en dos partes:
Feedforward: consiste en darle a la red los valores de entrada y que te devuelva
los valores de salida. Como hemos mencionado, este proceso solamente consiste
en una serie de sumas ponderadas que heredan el resultado a las siguientes capas
hasta obtener un resultado final.
Backpropagation: una vez obtenido el resultado, este tendrá un error respecto al
valor real que se deberı́a obtener. La siguiente etapa del entrenamiento consiste
en medir ese error y castigar a cada neurona modificando sus pesos en función de
la influencia que ha tenido sobre el resultado final.Fundamentos sobre Aprendizaje Automático 18
3.3.1. Funciones de pérdida
Para el cálculo del error durante el entrenamiento, se emplean funciones de pérdida,
también llamadas funciones de error, y son un elemento fundamental en la teorı́a de
optimización de problemas en varias ciencias: Teorı́a de decisión (donde juega un gran
papel la Teorı́a Bayesiana, propuesta por el Inglés Thomas Bayes en el siglo XVIII),
estimación, pronóstico, inversión financiera y en la econometrı́a, entre otros [2]. La de-
finición más sencilla de una función de pérdida podrı́a darse de la siguiente manera:
dada una predicción ybi , y el valor real yi , la función de pérdida mide la diferencia o
discrepancia entre el algoritmo o modelo de predicción y la salida deseada. El error
calculado nos permite propagarlo por la arquitectura actualizando sus pesos, y de esta
manera hacer que la red ”aprenda”.
Algunos ejemplos de las funciones clásicas son las cuadráticas, las de valor absoluto,
las de cuantiles y la 0-1. Cada una de estas funciones se soportan en una medida es-
tadı́stica (la media, la media al cuadrado o la mediana), que se convierte en un criterio
importante para la decisión del modelo de estimación.
Por otro lado, dependiendo de cómo se tratan las magnitudes de los errores y su
signo, se podrı́an clasificar las funciones como simétricas y asimétricas. Las más popu-
lares son las funciones simétricas, pero a veces con las asimétricas se puede lograr una
medición más real desde el punto de vista económico y no matemático. Por ejemplo
en [3] crean su propia función de pérdida para que penalice más los errores donde la
tendencia de la predicción sea contraria a la que realmente ocurre posteriormente. En
nuestro estudio hemos utilizado las siguientes funciones:
Mean Absolute Error (MAE): mide el promedio de la diferencia absoluta entre el
valor real y el valor predicho.
N
1 X
M AE = |yi − ybi | (3.4)
N
i=0
Mean Squared Error (MSE): similar a MAE, pero penaliza más cuanto mayor es
el error. Pero como veremos más adelante, tanto MAE como MSE son una medida
absoluta, y van a penalizar por igual las diferencias de 20 − 10, que 200 − 190.
N
1 X
M SE = (yi − ybi )2 (3.5)
N
i=0
Huber loss: función de pérdida usada para regresiones robustas que combina los
dos errores de MAE y MSE. Esta función es menos sensible a los errores muy gran-
des. Utiliza MAE para errores más grandes que δ y en caso contrario MSE. EstoFundamentos sobre Aprendizaje Automático 19
puede resultar útil cuando queremos utilizar el error cuadrático pero queremos
ignorar los errores grandes provocados por anomalı́as.
1
bi )2
Huber = 2 (yi − y for |yi − ybi | ≤ δ,
(3.6)
δ |yi − ybi | − 12 δ 2 otherwise.
3.3.2. Evaluación
Después de entrenar un modelo, para poder clasificarlo y evaluarlo, es necesario
tener una medida que mida su rendimiento. Estas medidas pueden ser absolutas si
calculan el error sin importar el signo, relativas a una base si utilizan un valor para
compararse y relativas al tamaño de los errores si arrojan un valor porcentual.
Las funciones que hemos mencionado en el apartado de funciones de pérdida 3.3.1 se
consideran solamente absolutas, ya que no miden un error proporcional a la magnitud
de los datos y no podemos saber si un es error es grande o pequeño. Esto no impide a
que podamos usarlo para compararlo con el resultado de otro modelo de referencia.
3.3.2.1. Métricas relativas
De la métricas relativas se han estudiado las siguientes:
Mean Absolute Scaled Error (MASE): se calcula como ratio de MAE en datos de
test dividido por el MAE de las predicciones del método naı̈ve 1 de un paso sobre
el conjunto de entrenamiento.
N
1 X
M ASE = M AE/Q; Q= |yi − yi−1 | (3.7)
N −1
i=2
Mean Absolute Percentage Error (MAPE): es una de las medidas estadı́sticas
más usadas para evaluar la precisión de un modelo y permite calcular el error
porcentual independientemente de la magnitud de los datos. La desventaja de
MAPE es que tiende a infinito con la presencia de valores reales iguales o cercanos
a cero, y tiene una curva de error asimétrica porque posee un valor mı́nimo, pero
no máximo.
N
1 X |yi − ybi |
M AP E = ∗ 100 (3.8)
N yi
i=0
1
Técnica de estimación que utiliza como predicciones los valores reales del pasado.Fundamentos sobre Aprendizaje Automático 20
Symmetric Mean Absolute Percentage Error (SMAPE): se presenta como una so-
lución a las limitaciones de MAPE, pero realmente no soluciona del todo ninguna
de ellas [4].
N
1 X |yi − ybi |
SM AP E = ∗ 100 (3.9)
N (yi + ybi )/2
i=0
3.3.2.2. Backtesting
Para nuestro problema concreto, una de las formas para medir el rendimiento de los
modelos es simulando su comportamiento mediante backtesting. Esta simulación con-
siste en una estrategia de compra y venta utilizando la información proporcionada por
las predicciones. Gracias a esta simulación podemos medir y comparar el rendimien-
to del portafolio y el drawdown máximo de cada modelo durante el rango de tiempo
simulado.
Hay que destacar que esta simulación se usa concretamente para medir el riesgo de
una estrategia y no la precisión de las predicciones de un modelo. En nuestro caso, las
predicciones forman una parte importante de la estrategia, por lo tanto el modelo puede
ser preciso y la estrategia poco robusta, donde robusta hace referencia a la constancia de
las ganancias y un drawdown bajo. De la misma manera la estrategia puede ser buena,
pero si las predicciones son poco precisas, estas harán que la estrategia pierda.
3.4. Series temporales
Los datos que vamos a utilizar en este trabajo pertenecen a la categorı́a de series
temporales. Una serie temporal se define como una serie de datos recogidos secuen-
cialmente en el tiempo. A diferencia de otros tipos de datos, estos tienen registrado el
momento exacto en el cual fueron recogidos y que suelen estar tomados en instantes de
tiempo equiespaciados o bien acumulados en intervalos. Su caracterı́stica es que las ob-
servaciones sucesivas no son independientes entre sı́ y su análisis debe llevarse a cabo
teniendo en cuenta su orden temporal.
Durante su análisis, cuando se piensa que los datos presentan una tendencia princi-
pal o cierta periodicidad, se considera que la serie temporal se puede representar como
un agregado (suma) o como una combinación (multiplicación) de estos tres componen-
tes:
1. Tendencia: valor y dirección que representa la tendencia principal de la serie aFundamentos sobre Aprendizaje Automático 21
largo plazo.
2. Estacionalidad: representa un ciclo repetitivo de la serie que indica tendencias
repetitivas en periodos de tiempo equidistantes.
3. Ruido: después de extraer los componentes anteriores lo que queda se considera
ruido con comportamiento aleatorio.
En la figura 3.4 podemos ver un ejemplo de descomposición de nuestros datos en sus
tres componentes principales usando composición mediante combinación y periodos
de una semana.
Figura 3.4: Descomposición de los datos con periodos de una semana.
La predicción de series temporales es un problema muy común ya que la mayorı́a de
los datos del mundo real son almacenados junto a su fecha, y esta información resulta
muy útil. La distribución de nuestro horario y la forma de medir el tiempo hace que
cada cierto tiempo realizaremos acciones similares lo que lo convierte en patrones tem-
porales y gracias a ellos podemos obtener predicciones más precisas. Un claro ejemplo
es un incremento de compras de regalos en época de fiestas o el tiempo meteorológico
que se repite de manera anual.4 Metodologı́a
El trabajo realizado se puede dividir en dos grandes bloques. Por un lado, se ha
realizado un estudio sobre los datos con los que hemos trabajado, y de trabajos similares
a partir de los cuales poder partir. De la misma manera, se han estudiado algunas de
las técnicas modernas de Deep Learning que puedan resultar útiles para la resolución
del problema planteado. En este capı́tulo hablaremos de los métodos y estrategias que
se han aplicado para abordar el problema planteado en este trabajo.
4.1. Análisis de datos
Existen multitud de diferentes activos financieros que podı́an haber sido usados para
este estudio. Además, como en el caso de las criptomonedas, su información puede ser
extraı́da de diferentes sitios. Se ha optado por la utilización de las criptomonedas por su
gran popularidad reciente y el gran potencial que pueden tener en un futuro cercano.
Concretamente, los datos que hemos utilizado para el estudio están formados por
el histórico de la criptomoneda Ethereum con los precios respecto al dólar, representa-
dos como velas con una temporalidad de cinco minutos y extraı́dos de la plataforma
Binance. Como vimos en la sección 2.3 de Velas Japonesas, las variables de los que dis-
ponemos son cinco: precio máximo, precio mı́nimo, precio de apertura, precio de cierre,
el volumen durante el periodo de la vela y, además, la fecha exacta de la apertura de la
vela.
En los siguientes apartados veremos cómo se han tratado los datos y los distintos
tipos de preprocesado aplicados.
23Metodologı́a 24 4.1.1. Preprocesado básico Los datos crudos descargados presentan valores nulos que se deben a pérdida de información en la plataforma que puede ser provocado por algún fallo o interrupción de su funcionamiento por mantenimiento. Por lo tanto se ha aplicado un preprocesado básico para rellenar los valores vacı́os con los últimos valores disponibles, y además, se ha comprobado que no haya fechas duplicadas ni valores extremos erróneos. 4.1.2. Extracción de información Antes hemos mencionado que las redes neuronales se consideran algoritmos con una capacidad de aprendizaje profundo y que consiguen extraer caracterı́sticas de los datos que a veces un ser humano es incapaz. También, que esto se debe a su jerarquı́a de capas y neuronas, donde cada capa extrae algún tipo de información y la comparte con las siguientes capas. Se podrı́a pensar que cuantas más capas y neuronas tenga una red, mejor va predecir, y que extraer nuevas caracterı́sticas, serı́a como duplicar datos que ya tenemos, ya que la red deberı́a ser capaz de hacerlo por su cuenta y mejor. Por desgracia, la realidad es más compleja. En los siguientes apartados explicaremos cómo influye el tamaño de la red en los resultados, la importancia de extraer nuevas caracterı́sticas y cuáles hemos utilizado. 4.1.2.1. Datos de entrenamiento vs test Los datos de entrenamiento, como su nombre indica, son los datos usados para entre- nar un modelo y conseguir que este aprenda. Ahora bien, no queremos que se memo- rice los datos, sino conseguir extraer caracterı́sticas que nos permitan predecir mejor el futuro. Recordemos que cuando entrenamos un modelo modificamos sus pesos en fun- ción de cuánto se ha equivocado, con el objetivo de obtener predicciones más precisas. Pero ese error no es real, es decir, que tengamos un error bajo en los datos de entre- namiento no asegura que sea igual de bajo en las predicciones que hagamos con datos que el modelo nunca habı́a visto. Es por esto que guardamos una parte de los últimos datos disponibles, que llamaremos test, para saber si el modelo es capaz de predecirlos igual de bien.
Metodologı́a 25
4.1.2.2. Complejidad de la red
En Machine Learning, la complejidad de un modelo hace referencia a la cantidad de
parámetros o pesos de los que esta formado. Cuantos más parámetros tiene, mayor ca-
pacidad tiene de relacionar las distintas caracterı́sticas de los datos de entrada con los
de salida. Sin embargo, a medida que vayamos aumentando la cantidad de parámetros,
el modelo deja de extraer caracterı́sticas importantes, y empieza a guardarse informa-
ción menos importante pero que le permite obtener un error más pequeño durante el
entrenamiento. En otras palabras, estarı́a memorizando los datos de entrenamiento pro-
vocando que no sepa reaccionar a nuevos datos nunca vistos. En Machine Learning este
comportamiento recibe el nombre de Overfitting (sobre-entrenamiento). Por otro lado,
si hacemos un modelo muy pequeño, puede ser insuficiente para detectar caracterı́sti-
cas más complejas. En la figura 4.1 se puede observar cómo el error converge y diverge,
entre los datos usados para entrenar y los datos nunca vistos, a medida que aumenta la
complejidad de la red.
Figura 4.1: Relación del error y la complejidad de la red.
La extracción de información nos permite indicarle a la red caracterı́sticas importan-
tes en forma de nuevos datos de entrada. De esta manera podemos reducir la comple-
jidad del modelo y evitar en cierta medida que la red aprenda información irrelevante
de los datos de entrenamiento.Metodologı́a 26
4.1.2.3. Indicadores técnicos
Los indicadores técnicos [5] son medidas que extraen diferentes tipos de información
de un mercado financiero. Miden caracterı́sticas como la tendencia del mercado y son
fundamentales en el análisis técnico y las estrategias de trading.
En este estudio hemos utilizado los siguientes indicadores:
Exponential Moving Average (EMA): es uno de los indicadores de tendencia más
usados. Permite visualizar el precio medio de un activo durante un periodo. A
diferencia de una media móvil simple (SMA), este indicador realiza una media
ponderada aplicando mayor peso a los precios más recientes.
Percentage Price Oscillator (PPO): es un oscilador de momentum (impulso), que
mide la diferencia entre dos medias móviles1 como un porcentaje de la media
móvil más grande.
Rate of Change (ROC): también conocido simplemente como Momentum. Mide
el retorno porcentual después de cierto periodo.
Relative Strength Index (RSI): compara las tendencias alcistas y bajistas para me-
dir la velocidad y el cambio de los movimientos del precios de un activo durante
un rango de tiempo. Se utiliza principalmente para intentar identificar condicio-
nes de sobrecompra o sobreventa en la negociación del activo.
Stochastic RSI (stochRSI): mide el valor de RSI respecto al valor máximo y mı́ni-
mo durante un periodo de tiempo. Se puede considerar como un indicador de un
indicador.
Money Flow Index (MFI): es un oscilador de volumen que utiliza el precio y el
volumen para medir la presión de compra y venta.
Donchian Channel: está formado por dos medias móviles y una linea central. Las
dos medias se obtienen de los valores máximo y mı́nimos respectivamente, y la
linea central es el resultado de la media. Para no utilizar una cantidad elevada de
datos solo se ha utilizado la linea central.
Commodity Channel Index (CCI): mide la relación entre el precio actual y el pre-
cio medio durante un perı́odo de tiempo. El CCI se puede utilizar para identificar
una nueva tendencia o advertir de condiciones extremas.
1
Una media móvil no es más que una media aritmética de los precios en un rango de tiempo.Metodologı́a 27
Moving Average Convergence Divergence (MACD): es un indicador de tenden-
cia que mide la relación entre una EMA rápida (periodo corto) y una EMA lenta
(periodo largo). Se suele emplear en estrategias de trading para detectar posibles
entradas al mercado. Cuando la media rápida corta a la larga por debajo, se su-
pone que el precio va subir, y cuando la corta por arriba, que el precio va bajar.
4.1.3. Técnicas trigonométricas
Al trabajar con series temporales, una de las variables más importantes es la fecha.
Esta nos puede ayudar a encontrar patrones clave que tienen una fuerte relación con el
momento en el cual fue tomada la información, como podrı́an ser, por ejemplo, eventos
que se repiten de manera anual. El problema es que nuestros datos no tienen ninguna
información que permita indicar esa relación, como tampoco que la hora siguiente de
23 es un cero y, por lo tanto, existen ciclos que necesitamos indicar.
Para resolver este problema se emplean técnicas trigonométricas que permiten con-
vertir las fechas en ondas con amplitud máxima que indique el fin o el inicio de un
nuevo ciclo. El método más común consiste en modelizar los datos mediante una fun-
ción armónica como el seno o el coseno.
Para aplicar esta técnica hemos transformado los datos en ciclos semanales y anua-
les, ya que pueden ser los periodos más importantes. De esta manera podemos detectar
cambios en el mercado que puedan ser habituales en festivos o fines de semana. Con-
cretamente las fórmulas aplicadas son las siguientes:
W eekCos = cos(timestamp ∗ (2π/ws)) (4.1)
Y earCos = cos(timestamp ∗ (2π/ys)) (4.2)
Previamente a las fechas se les aplica una transformación al formato Timestamp2 pa-
ra tenerlas representadas en formato numérico. Por otro lado, las constantes ws y ys
representan la duración en segundos de una semana y un año respectivamente. Final-
mente se les aplica la función coseno para representar las fechas como ciclos con valores
en el rango [-1, 1].
2
Timestamp es un formato de fecha que representa el número de segundos transcurridos desde 1970.Metodologı́a 28
Figura 4.2: Coseno aplicado a los datos de fecha con ciclos de una semana y un año.
4.1.4. Escalado y normalización de los datos
Una de las técnicas básicas de preprocesado de datos es la normalización y escalado
de los datos.
Los datos con los que trabajamos tienen mucho ruido, su histograma es muy disperso
y no sigue una distribución normal. Además, nuestros valores pueden crecer de forma
indefinida en el tiempo y disponen de gran cantidad de valores extremos cuya frecuen-
cia en el conjunto de datos es muy pequeña, lo que se traduce en menor probabilidad de
ser seleccionado como predicción. Para solucionar estos problemas, se aplica la norma-
lización. La normalización de los datos consiste en representarlos en un rango reducido,
normalmente en el de [0, 1], y repartirlos de tal manera que siga una distribución nor-
mal, también llamada distribución gaussiana. La ventaja de estas transformaciones es
que nos permite, como su nombre indica, normalizar los datos, por un lado elimina los
valores extremos y, por otro, permite obtener una distribución más repartida y que la
diferencia de frecuencia de los valores no sea tan elevada.
Las transformaciones más comunes consisten en:
Aplicar a los datos una transformación logarı́tmica. De esta manera cuanto mayor
sea el valor menor importancia tendrá a sus valores vecinos.
Sustituir los datos por cambios porcentuales que representan el porcentaje de
cambio de sus valores respecto a los previos.
Operaciones con la desviación tı́pica y percentiles de los datos para reducir los
valores extremos.
Por otros lado, a diferencia de la normalización, el escalado de datos no cambia suMetodologı́a 29
distribución, sino que se encarga simplemente en reducir el rango de los datos.
Durante este estudio hemos estudiado los siguientes escaladores:
MinMaxScaler: escala los datos entre un rango de [0, 1]. Cuando trabajamos con
datos que pueden superar sus valores mı́nimos o máximos, al utilizar el mismo
escalador se van a salir del rango mencionado. Para prevenir esto a veces se utili-
zan valores máximos y mı́nimos artificiales que se piensa que no se van a superar,
pero sigue sin ser una solución óptima.
x − xmin
xscaled = (4.3)
xmax − xmin
StandardScaler: escala y centra los datos restándoles la media y escalándolo res-
pecto la desviación estándar. Al igual que el MinMaxScaler, utiliza la media y
desviación de los datos del pasado para escalar los nuevos datos, por lo que no
puede asegurar un escalado equitativo.
x − xmean
xscaled = (4.4)
xstdev
RobustScaler: a diferencia de los anteriores, escala los datos usando estadı́sticas
que son robustas a los valores extremos. Para ello escala y centra los datos respec-
to al rango del cuartil 1 (percentil 25) y cuartil 3 (percentil 75).
x − xq1
xscaled = (4.5)
xq3 − xq1
PowerTransformer: aplica una transformación de potencia para que los datos
sean más ”gaussianos”. Esto es útil para solucionar problemas de varianza va-
riable y permite normalizar los datos.
QuantileTransformer: aplica una transformación no lineal a los datos para que
sigan una distribución normal o uniforme. De esta manera, tiende a dispersar los
valores más frecuentes y, además, reduce el impacto de los valores extremos, por
lo tanto también es robusto. Hay que tener en cuenta que puede distorsionar las
correlaciones lineales entre las distintas variables, pero por otro lado permite que
los datos de diferentes magnitudes sean más comparables.Metodologı́a 30 4.1.5. Conclusiones del la sección de Análisis El análisis de datos no forma parte de las técnicas de Deep Learning, pero suele re- presentar hasta el 80 % del tiempo total dedicado a la resolución de un problema, ya que es muy importante para que los modelos funcionen correctamente y poder obtener una solución óptima al problema. Con la intención de centrar el trabajo en el estudio de las técnicas de Deep Learning, hemos realizado un análisis básico con las técnicas mencionadas en este capı́tulo.
Metodologı́a 31
4.2. Arquitecturas
Durante este bloque, vamos a estudiar y ampliar nuestros conocimientos sobre las
distintas técnicas y arquitecturas de redes neuronales.
El primer paso fue decidir que querı́amos predecir. Por ejemplo en [3] utilizaron co-
mo predicciones el retorno porcentual, es decir, predecı́an cuánto y en qué dirección iba
a cambiar el precio tı́pico de la siguiente vela. Hay que recordar que las predicciones
del modelo van a funcionar de manera parecida a un indicador técnico, por tanto sigue
haciendo falta una estrategia y una gestión de riesgo para poder utilizarlo como un al-
goritmo de trading, es decir, podemos predecir lo que queramos con tal de que creamos
que esa información pueda resultarnos útil. En este trabajo hemos decidido abordar el
problema mediante la predicción del precio tı́pico 3 de la siguiente vela. A diferencia
del precio de cierre, este valor esta más centrado a la vela, y en caso de cometer un
error en nuestra predicción, el valor estimado tiene más posibilidades de estar dentro
del rango entre el valor máximo y mı́nimo real.
4.2.1. Arquitectura MLP
La arquitectura Multi Layer Perceptron es la arquitectura más simple. A parte de las
capas de entrada y salida, está formada por varias capas ocultas conectadas entre sı́. En
los experimentos que vamos a realizar, este modelo va estar estructurado en forma de
embudo con el objetivo de ir reduciendo la dimensionalidad de los datos.
4.2.2. Arquitectura Residual
Una red neuronal residual, conocida como ”ResNet”[6], se caracteriza por ensam-
blar la información de distintos niveles, es decir, concatena la salida de varias capas
distintas. La idea de esto es juntar información de distinta granularidad, ya que la in-
formación de una capa más profunda se puede considerar más procesada o fina que la
información anterior. Además, permite evitar los gradientes que se desvanecen 4 pro-
pagando el error directamente a las capas principales.
3
El precio tı́pico es la media aritmética del precio máximo, mı́nimo y de cierre de una vela.
4
El desvanecimiento del gradiente ocurre cuando el gradiente obtenido es muy pequeño y por tanto no
consigue modificar suficientemente los pesosMetodologı́a 32
Figura 4.3: Bloque residual.
4.2.3. Arquitecturas recurrentes
Las redes recurrentes están formadas por bucles de realimentación, permitiendo a
través de ellos que la información persista un tiempo durante el entrenamiento. Estos
bucles devuelven los resultados como nuevos datos de entrada adicionales. Funciona
como una red con múltiples copias de sı́ misma, cada una proporciona alguna infor-
mación adicional a su sucesor, por lo que resultan muy útiles con secuencias de datos
como pueden ser secuencias de palabras o datos temporales como los nuestros.
4.2.3.1. Long Short Term Memory Networks (LSTM)
Las LSTMs [7] son un tipo de bloque empleados en la construcción de redes recu-
rrentes. Estas, son capaces de aprender y memorizar dependencias del pasado. Esto se
debe a que contienen información en su memoria, que puede considerarse similar a la
memoria de un ordenador, en el sentido que una neurona de una LSTM puede leer,
escribir y borrar información de su memoria.
Esta memoria se puede ver como una ”celda” bloqueada, donde ”bloqueada” signifi-
ca que la célula decide si almacenar o eliminar información dentro (abriendo la puerta
o no para almacenar), en función de la importancia que asigna a la información que
está recibiendo. La asignación de importancia se decide a través de los pesos, que tam-
bién se aprenden mediante el algoritmo. Esto lo podemos ver como que aprende con el
tiempo qué información es importante y cuál no.Metodologı́a 33
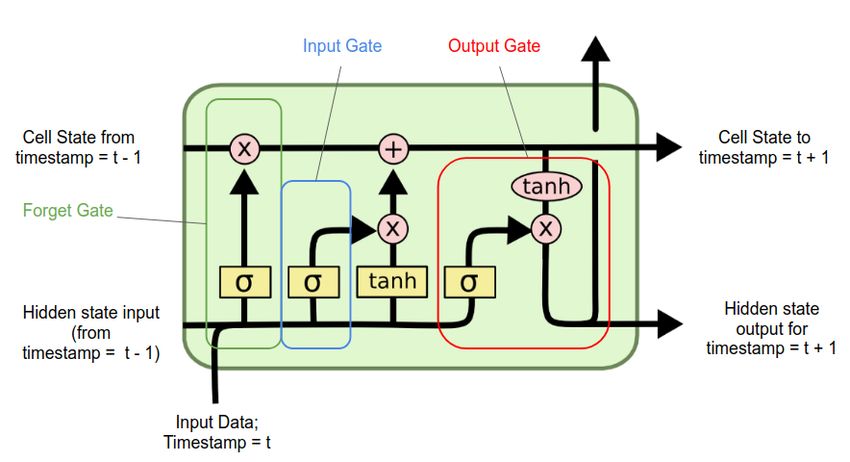
Como podemos ver en la figura 4.4, una unidad LSTM común se compone de una
celda, una puerta de entrada, una puerta de salida y una puerta de olvido. La celda
recuerda valores en intervalos de tiempo arbitrarios y las tres puertas regulan el flujo
de información dentro y fuera de la celda. Concretamente, estas puertas determinan si
se permite o no una nueva entrada, si se elimina la información porque no es importante
o se deja que afecte a la salida en el paso de tiempo actual.
Figura 4.4: Arquitectura de una célula LSTM.
Este tipo de bloque, además de ser una potente herramienta para succiones de datos,
permite solucionar el problema del desvanecimiento del gradiente mencionado ante-
riormente.
4.2.3.2. Gated Recurrent Unit (GRU)
Otro tipo de bloque recurrente son las Gared Recurrent Unit [8] (GRU). Este bloque,
al igual que las LSTM, permite recordar información del pasado y de la misma ma-
nera evitar el problema del desvanecimiento del gradiente. La principal diferencia se
encuentra en su estructura. Como podemos observar en la figura 4.5, el bloque de la
GRU no dispone de la puerta de olvido y, las dos salidas que contiene la LSTM, GRU
las combina en una sola.
En la mayorı́a de problemas, ambos bloques obtienen resultados muy similares, con
la diferencia de que las GRU tienen un tiempo de computo ligeramente menor.Metodologı́a 34
Figura 4.5: Arquitectura de una célula GRU.
4.2.3.3. Redes Convolucionales (CNN)
Las capas convolucionales consisten en un conjunto de filtros que recorren el con-
junto de los datos de entrada en busca de caracterı́sticas. Estos filtros disponen de un
tamaño y dimensión que definen el área para la búsqueda de las relaciones entre sus
valores vecinos. Como podemos ver en la figura 4.6, los valores del filtro se multiplican
por la matriz de entrada hasta recorrer toda la matriz.
Figura 4.6: Ejemplo de aplicación de un filtro de convolución.
En este caso consiste en un filtro de dos dimensiones, pero puede ser usado también
con datos de 3 dimensiones, como podrı́a ser una imagen con varios canales de color.Metodologı́a 35
Sus aplicaciones más comunes son con datos de entrada que representan los dı́gitos de
una imagen. Los filtros son capaces de detectar desde estructuras simples como bordes
o formas geométricas simples, hasta estructuras más complejas como caras a partir de
la información de las capas anteriores.
Figura 4.7: CNN para detección de caras.
4.2.3.4. Temporal Convolutional Network (TCN)
Las redes convolucionales temporales son una variación de las redes neuronales con-
volucionales preparado para datos secuenciales. Esta arquitectura está diseñada para
que la salida sea la entrada en el siguiente paso de tiempo lo que permite extraer infor-
mación tanto espacial como temporal. Estas caracterı́sticas hacen esta arquitectura muy
interesante para competir con las redes recurrentes.Metodologı́a 36
4.3. Pipeline
Una vez procesados de los datos, se ha establecido una cadena de procesos que se-
guir. Esta cadena empieza por dividir los datos, y entra en un bucle de entrenamiento
y comparativa de los modelos para seleccionar los mejores. Finalmente se realiza una
comparativa del rendimiento de los mejores modelos con los datos de test.
4.3.1. Split de datos
Como hemos mencionado, nuestros datos forman parte del grupo de series tempo-
rales, y es por ello que la forma más realista de dividir los datos es utilizar los últimos
disponibles para la evaluación de los modelos, y el resto para entrenamiento.
Por tanto, hemos reservado el ultimo 10 % de los datos para test, y el 90 % de los datos
restantes se ha dividido en 5 trozos solapados de manera que los trozos posteriores
incluyen todas las partes anteriores, empezando el primero con el primer 1/5 de los
datos. Por último, de cada trozo se ha extraı́do su ultimo 10 % para evaluación. En la
figura 4.8 se puede observar como queda finalmente la división de los datos para el
entrenamiento.
Figura 4.8: Splits de datos.
Esta estrategia nos permite entrenar y evaluar los modelos sobre distintos grupos de
datos con el objetivo de medir su capacidad de generalización.Metodologı́a 37
4.3.2. Entrenamiento y la evaluación de los modelos
Para el entrenamiento de los modelos, se han probado con las distintas funciones de
error mencionadas en la sección 3.3.1, pero la que mejores resultados ha obtenido ha
sido la función de perdida de MAE.
Por otro lado, para la evaluación de los modelos se han utilizado las métricas men-
cionadas en la sección 3.3.2. Sobre todo, nos hemos fijado en los valores de SMAPE y
MAE. Este último, a pesar de no ser un error relativo a la magnitud de los datos, nos
permite comparar el error de la misma manera y, además, nos permite visualizar mejor
el error promedio real.
Una vez obtenidos los resultados, se procedió a ajustar los distintos parámetros de
entrenamiento y, en caso de sobreentrenamiento, se ajustaba la arquitectura de la red
reduciendo su complejidad o usando capas de Dropout y BatchNormalization que per-
miten meter ruido en los datos y normalizarlos respectivamente.
4.4. Tecnologı́as
Para llevar a cabo este estudio se han utilizado una serie de recursos que indicaré en
este apartado.
4.4.1. Librerı́as
Pandas[9] & Numpy[10]: para el procesamiento y análisis de los datos.
Seaborn[11] & Matplotlib[12]: para la visualización de los datos.
Pickle[13]: permite almacenar estructuras de datos en ficheros binarios.
Statsmodels[14]: permite la realización de tests estadı́sticos y la exploración es-
tadı́stica de los datos.
Tensorflow[15] & Keras[16]: para la implementación de los algoritmos de apren-
dizaje profundo.
Sklearn[17]: contiene varios algoritmos que incluyen procesamiento, análisis y
estimación de los datos.También puede leer

















































