Técnicas de aprendizaje para la identificación de rapaces por restos óseos Maching Learning techniques for the identification of raptors by ...
←
→
Transcripción del contenido de la página
Si su navegador no muestra la página correctamente, lea el contenido de la página a continuación

Técnicas de aprendizaje para la
identificación de rapaces por restos óseos
Maching Learning techniques for the
identification of raptors by skeletal remains
Por
Paula Sánchez de la Nieta Gómez
Grado en Ingeniería del Software
Facultad de Informática
Dirigido por
Yolanda García Ruiz
Madrid, 2020–2021
Agradecimientos
A mi familia, a mis amigas y compañeros de la universidad, gracias por el apoyo y los
ánimos durante todos estos años.
A Pilar Gamarra, por motivarme, por enseñarme lo que valgo y por confiar en mí más
que yo misma.
A mi tutora Yolanda García Ruiz, por acompañarme y ayudarme en todo momento. Y a
Luis Revuelta Rueda por pensar en mí para este proyecto innovador.
II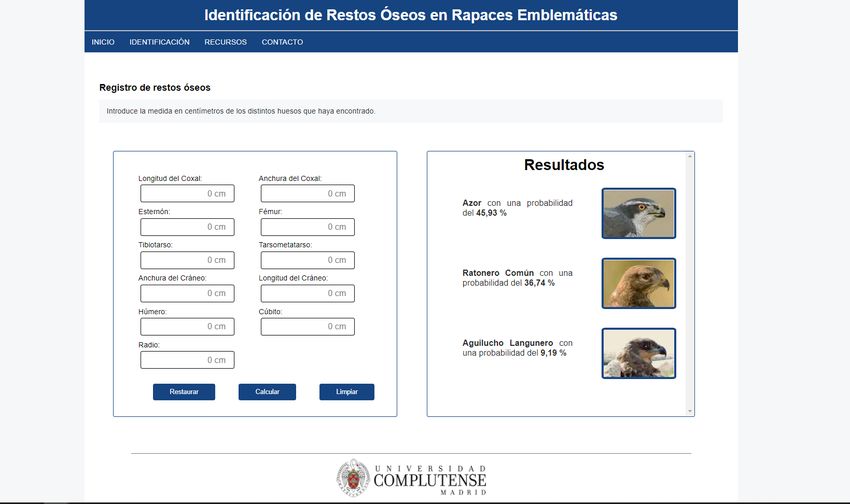
Certificado de permisos
Que dispone del permiso de utilización de los datos incluidos en la base de datos
(Número de registro 49/437736.9/21, Fecha: 06/07/2021 11:56).
Que el registro del programa está en proceso de patente.
III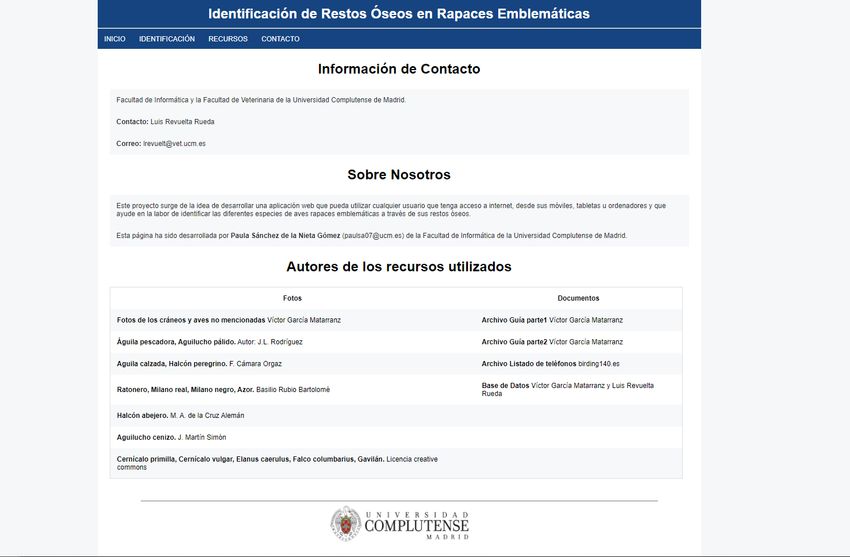
Índice general
Página
1. Introducción 1
1.1. Motivación . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2. Objetivo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.3. Plan de trabajo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
2. Machine Learning 5
2.1. ¿Qué es el Machine Learning? . . . . . . . . . . . . . . . . . . . . . . . . 5
2.2. Aprendizaje Máquina Supervisado . . . . . . . . . . . . . . . . . . . . . . 6
2.2.1. Algoritmos Aprendizaje Supervisado . . . . . . . . . . . . . . . . 7
2.3. Aprendizaje Máquina No supervisado . . . . . . . . . . . . . . . . . . . . 8
2.3.1. Algoritmos Aprendizaje No Supervisado . . . . . . . . . . . . . . 9
2.4. Aprendizaje Máquina por Refuerzo . . . . . . . . . . . . . . . . . . . . . 10
3. Predicción de tipo de ave 12
3.1. Materiales y métodos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
3.1.1. Materiales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
3.1.2. Métodos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
3.2. Comparativa de los algoritmos del DataSet . . . . . . . . . . . . . . . . . 14
4. Herramienta de desarrollo 16
4.1. Pruebas de arquitectura . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
4.2. Arquitectura . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
4.3. Implementación . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
4.3.1. Backed . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
4.3.2. Fronted . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
4.4. Despliegue . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
4.5. Herramientas de trabajo . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
5. Descripción de la aplicación web 24
5.1. Análisis de la competencia . . . . . . . . . . . . . . . . . . . . . . . . . . 24
5.2. Escenarios de uso . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
5.3. Requisitos funcionales . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
5.4. Interfaz de usuario . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
5.4.1. Interfaz Principal . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
5.4.2. Interfaz Identificación . . . . . . . . . . . . . . . . . . . . . . . . 26
5.4.3. Interfaz Contacto . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
5.4.4. Interfaz Recursos . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
5.5. Navegación entre interfaces . . . . . . . . . . . . . . . . . . . . . . . . . 29
IV
Técnicas de aprendizaje para la identificación de rapaces por restos óseos UCM
6. Conclusiones 32
6.1. Trabajo futuro . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
7. Bibliografía y enlaces de referencia 36
V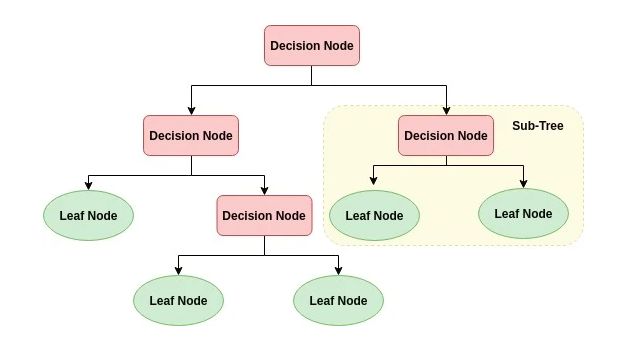
Resumen
Actualmente, en un mundo tan comprometido por la conservación del medio ambien-
te, aparecen muchas iniciativas e incluso modos de vida para salvar el planeta, cuidar la
Tierra y acciones de cero emisiones contaminantes. En este proyecto queremos centrarnos
en la conservación de los ecosistemas autóctonos.
El proyecto surge de la necesidad de reconocer los restos óseos de aves muertas que se
encuentran en nuestra geografía, de forma rápida y eficaz. La determinación de la especie
a partir de los restos óseos es de gran ayuda a las autoridades pertinentes, ya que les
permite mantener una estadística actualizada y correcta de la población de aves y deter-
minar los impactos medioambientales que conlleva la humanización de los terrenos.
La aplicación se focaliza en la identificación de aves rapaces emblemáticas a partir de sus
restos óseos, permitiendo su uso a cualquier usuario con acceso a internet.
Palabras clave
Aves
Rapaces
Aprendizaje Máquina
Aplicación web
Python
Framework
Django
VI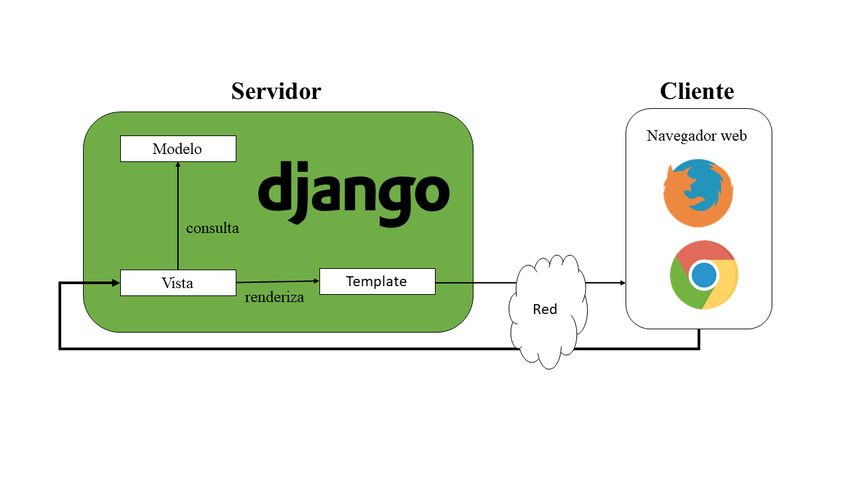
Abstract
Nowadays, in a world so committed to environmental conservation, there are many initia-
tives and even ways of life to save the planet, take care of the Earth and zero polluting
emissions actions. In this project we want to focus on the conservation of native ecosys-
tems.
The project arises from the need to recognise the skeletal remains of dead birds found in
our geography, quickly and efficiently. Determining the species from the skeletal remains
is of great help to the relevant authorities, as it allows them to keep up-to-date and co-
rrect statistics on the bird population and to determine the environmental impact of the
humanisation of the land.
The application focuses on the identification of emblematic birds of prey from their ske-
letal remains, allowing its use by any user with internet access.
Key words
Birds
Raptors
Machine Learning
Web aplication
Framework
Python
Django
VIICapítulo 1
Introducción
1.1. Motivación
En España existen 622 especies de aves, convirtiéndose en el segundo país con más bio-
diversidad de aves en Europa [1], solamente superado por Rusia. Este trabajo se centra
en las aves rapaces emblemáticas, caracterizadas por su pico curvado, sus garras, sus po-
tentes músculos en las patas y porque suelen ser de gran tamaño, que se encuentran en
nuestro país. Además, en España desde el 23 de julio de 1966 en el Boletín Oficial del Es-
tado de ley se estableció la protección legal de todas las aves rapaces, diurnas y nocturnas.
Aunque estas cifras sean positivas, no debemos relajarnos con la conservación de éstas y
el resto de especies aviares, ya que la humanización de los terrenos provoca la muerte de
muchas de estas aves. Se ha demostrado que la principal causa de mortalidad no natu-
ral de muchas aves rapaces es por electrocución, a causa de las líneas eléctricas que no
cumplen las características técnicas exigidas por el Real Decreto 1432/2008 por el cual se
establecen medidas para la protección de la avifauna contra la colisión y la electrocución
[2]. Además, hay que tener en cuenta también la caza ilegal de aves, en el que el grupo
más afectado son las aves rapaces. En España estos datos son críticos e impide en muchos
casos la recuperación de estas aves. Es necesario revertir esta situación, para garantizar la
recuperación de estas especies y el mantenimiento del ecosistema, ya que, la conservación
de las aves rapaces es clave.
En resumen, en muchos casos no es fácil determinar la causa de la muerte de las aves,
resulta muy útil conocer el número de aves que aparecen muertas en nuestros campos, así
como su especie. Sin embargo, determinar la especie de un ave no es tarea fácil, incluso
para aquellos que se consideran expertos en el tema. Esto es debido a que en muchos
casos solo se dispone de esqueletos (uno o varios huesos) encontrados en el campo por
caminantes, pastores y/o turistas. Entre las variables que permiten determinar el tipo
de ave, se encuentran las relacionadas con la fisionomía de los huesos, y en particular su
tamaño. Disponer de una aplicación que permita registrar los tipos de huesos encontrados
así como sus medidas, permitirá predecir de forma automática el tipo de ave para su
registro. En este sentido, las tecnologías actuales y el hecho de que prácticamente todo
el mundo disponga de un dispositivo móvil con acceso a internet en cualquier punto
geográfico, proporcionan una solución viable.
1Técnicas de aprendizaje para la identificación de rapaces por restos óseos UCM
1.2. Objetivo
Desarrollar una aplicación web que pueda utilizar cualquier usuario que tenga acceso a
internet, desde sus móviles, tabletas u ordenadores y que ayude en la labor de identificar
las diferentes especies de aves rapaces emblemáticas a través de sus restos óseos.
Objetivo 1. Definir un modelo predictivo para determinar el tipo de ave rapaz a partir
de un algoritmo de Aprendizaje Máquina (Machine Learning en inglés).
Objetivo 2. Desarrollar una aplicación web donde se incluya el modelo predictivo con una
interfaz intuitiva para el usuario, en la cual se mostrarán los resultados de la predicción.
1.3. Plan de trabajo
La organización de este proyecto consta de una serie de etapas.
1. Estudio de distintos algoritmos de Machine Learning, supervisado y no supervisado,
con la posterior comparación entre ellos para determinar el más apropiado para el pro-
yecto.
2. Implementación de distintos modelos de Machine Learning en el lenguaje Python para
estudiar y comparar su eficiencia.
3. Investigación de las distintas tecnologías web, eligiendo aquella que se adaptó mejor
al Modelo Vista Controlador (MVC) y a la unificación entre el algoritmo implementado
y el controlador de la página web.
4. Implementación de la página web.
5. Desarrollo del diseño de las interfaces de la aplicación web.
6. Despliegue de la aplicación web en un servidor.
2Introduction
Motivation
There are 622 bird species in Spain, making it the country with the second highest biodi-
versity of birds in Europe [1], second only to Russia. This work focuses on the emblematic
birds of prey, characterised by their curved beaks, their claws, their powerful leg muscles
and because they are usually large in size, which are found in our country. Moreover, in
Spain, since 23 July 1966, the Boletín Oficial del Estado established the legal protection
of all birds of prey, both diurnal and nocturnal.
Although these figures are positive, we must not relax with the conservation of these and
other avian species, as the humanisation of land causes the death of many of these birds.
It has been shown that the main cause of unnatural mortality of many birds of prey is
electrocution, due to power lines that do not comply with the technical characteristics
required by Real Decreto 1432/2008, which establishes measures for the protection of
birds of prey against collision and electrocution [2]. In addition, illegal hunting of birds
must also be taken into account, in which the most affected group are birds of prey. In
Spain, these figures are critical and in many cases prevent the recovery of these birds. It
is necessary to reverse this situation in order to guarantee the recovery of these species
and the maintenance of the ecosystem, as the conservation of birds of prey is key.
In summary, in many cases it is not easy to determine the cause of death of birds, it is
very useful to know the number of birds that appear dead in our fields, as well as their
species. However, determining the species of a bird is not an easy task, even for those who
consider themselves experts on the subject. This is due to the fact that in many cases
only skeletons (one or several bones) found in the field by walkers, shepherds and/or
tourists are available. Among the variables that make it possible to determine the type
of bird are those related to the physiognomy of the bones, and in particular their size.
Having an application that allows the types of bones found and their measurements to be
recorded will make it possible to automatically predict the type of bird to be recorded.
In this sense, current technologies and the fact that practically everyone has a mobile
device with internet access at any geographical location provide a viable solution.
Target
To develop a web application that can be used by any user with internet access, from
their mobiles, tablets or computers, to help in the task of identifying the different species
of emblematic birds of prey through their skeletal remains.
3Técnicas de aprendizaje para la identificación de rapaces por restos óseos UCM
Target 1. Define a predictive model to determine the type of bird of prey from a Machine
Learning algorithm.
Target 2. Develop a web application including the predictive model with an intuitive
user interface to display the prediction results.
The work plan
The organisation of this project consists of a series of stages.
1. Study of different Machine Learning algorithms, supervised and unsupervised, with
subsequent comparison between them to determine the most appropriate for the project.
2. Implementation of different Machine Learning models in the Python language to study
and compare their efficiency.
3. Investigation of the different web technologies, choosing the one that best adapted to
the Model View Controller (MVC) and the unification between the implemented algo-
rithm and the web page controller.
4. Website implementation.
5. Development of the design of the web application interfaces.
6. Deployment of the web application on a server.
4Capítulo 2
Machine Learning
2.1. ¿Qué es el Machine Learning?
La inteligencia artificial (IA) nace en el año 1956 (New Hanpshire, Estados Unidos). El
filósofo Thomas Hobbes (1588-1679) formuló la hipótesis de que todo pensamiento es el
resultado de un cálculo. Esta hipótesis es retomada por Alan Turning, matemático, acom-
pañado por Alanzo Church (en su tesis chuch-Turing), enuncia una segunda hipótesis:
“una máquina puede hacer cualquier cálculo. Por lo tanto, si el pensamiento es el resul-
tado de un cálculo y el cálculo lo hace una máquina, ¡el pensamiento se puede simular en
las máquinas!” [3]
De esta idea surge la inteligencia artificial, que al final es más probabilidad y estadística
de lo que pensamos. Existen dos tipos:
Aprendizaje Máquina (Machine Learning): siendo la capacidad estadística de
dotar a las máquinas la facultad de “aprender” mediante algoritmos diseñados a
partir de modelos estadísticos.
Los algoritmos de aprendizaje máquina se clasifican en tres tipos dependiendo de
los datos utilizados para su aprendizaje, véase el esquema de la Figura 2.1.
Aprendizaje Profundo (Deep Learning): son los algoritmos capaces de mejorar
de forma autómata. Se puede llegar a considerar una rama del aprendizaje máquina.
Los algoritmos del aprendizaje máquina han evolucionado mucho, convirtiéndose en un
reto para los programadores que desarrollan los algoritmos para cada vez ser más precisos
en una tarea en concreto. Entrenan a dichos algoritmos con grandes cantidades de datos
(cuánto mayor sea el volumen de datos más relevancia tendrá a la hora de dar respuestas
válidas), para que sean parseados, aprendan de ellos y que al final sean capaces de hacer
una predicción.
Esta capacidad de aprendizaje se emplea también para la mejora de motores de búsqueda,
la robótica, el diagnóstico médico, en la ciencia científica relacionada con el desarrollo de
la Inteligencia Artificial, entre otros.
5Técnicas de aprendizaje para la identificación de rapaces por restos óseos UCM
Figura 2.1: Esquema clasificación Aprendizaje Máquina. (Fuente: Elaboración propia)
2.2. Aprendizaje Máquina Supervisado
Los algoritmos de aprendizaje supervisado, trabajan con un conjunto de datos “etiqueta-
dos”, es decir, variables de entrada de las cuales sabemos el valor de salida adecuado. El
algoritmo es entrenado con dicho conjunto de datos etiquetados permitiendo al algoritmo
“aprender” a predecir un valor de salida factible a través de las variables suministradas,
puede verse la explicación más gráficamente en la Figura 2.2.
El aprendizaje supervisado se divide en dos grandes grupos dependiendo del tipo de datos
etiquetados:
Problemas de clasificación: El resultado de la predicción es un valor categórico,
valor dentro de un conjunto finito de datos posibles. Por ejemplo, el género de una
persona, si un correo es spam o no. Además, estos problemas pueden ser binarios,
si solo clasifican en dos tipos de clases, o multi-clases, cuando pueden clasificar los
datos en varias clases.
Problemas de regresión: El resultado de la predicción es un valor real, un valor nu-
mérico dentro de un conjunto infinito de valores posibles. Por ejemplo, predicciones
meteorológicas o de crecimiento.
Este trabajo se ajusta a un problema de clasificación multi-clase, donde las clases se co-
rresponden con las distintas especies de aves rapaces.
6Técnicas de aprendizaje para la identificación de rapaces por restos óseos UCM
Figura 2.2: Diagrama de flujo del aprendizaje supervisado. (Fuente: https://medium.
com/soldai/tipos-de-aprendizaje-automático-6413e3c615e2)
2.2.1. Algoritmos Aprendizaje Supervisado
Árboles de decisión. Decision trees. Algoritmo utilizado tanto en clasificación,
como en regresión, consiste en la toma de decisiones simples que permitan recorrer
el conjunto de datos hasta hallar un resultado correcto. Un árbol de decisiones, se
representa con nodos, indican una característica, y hay tres tipos, nodo raíz (nodo
superior o “padre” a todos), nodo (nodo hijo, tiene un nodo padre y nodos hijos)
y nodo hoja (nodo que ya no tiene nodos hijos), y con ramas que representan la
decisión tomada [4].
En la Figura 2.3, podemos observar un ejemplo general de como se iría construyen-
do un árbol de decisión.
Máquinas de vectores de soporte. Support vector machines (SVM). Al-
goritmo de clasificación y regresión, cuyo objetivo es dividir el conjunto de datos
dados eficazmente, para elegir un hiperplano (plano que separa una colección de
datos de distintas características) con la mayor distancia posible entre los dos vec-
tores más cercanos ( denominado margen), para obtener el máximo margen posible.
Cuanto mayor sea el margen, más óptimo será el algoritmo [5].
En la Figura 2.4 se representa la elección de un hiperplano óptimo y el margen.
7Técnicas de aprendizaje para la identificación de rapaces por restos óseos UCM
Figura 2.3: Ejemplo árbol de decisión generalizado. (Fuente: https://www.datacamp.
com/community/tutorials/decision-tree-classification-python)
Figura 2.4: Ejemplo SVM generalizado. (Fuente: https://www.datacamp.com/
community/tutorials/svm-classification-scikit-learn-python)
Bosques aleatorios. Random Forest. Se tiene un conjunto de datos con muchas
características, el algoritmo del árbol de decisión, visto en el apartado 2.2.1, tiende
a ser de gran tamaño complicando el modelo y el proceso de entrenamiento, por
tanto, se decide a utilizar el Random Forest. Basado en la técnica de “divide y
vencerás”, división aleatoria del conjunto de datos en pequeños árboles de decisión
independientes, cada árbol aporta un resultado y la clase más popular entre todos
los árboles de decisión, se considera el resultado final [6].
Véase una representación gráfica del algoritmo en la Figura 2.5.
2.3. Aprendizaje Máquina No supervisado
Los algoritmos de aprendizaje no supervisado, al contrario que pasa con los algoritmos
de aprendizaje supervisado, no trabajan con un conjunto de datos etiquetados en los que
conocemos su valor de salida, ya que solo se conoce el tipo de datos de entrada. Por tanto,
son algoritmos interesados en aumentar la estructura de los datos disponibles para poder
8Técnicas de aprendizaje para la identificación de rapaces por restos óseos UCM
Figura 2.5: Ejemplo Random Forest generalizado. (Fuente: https://www.datacamp.com/
community/tutorials/random-forests-classifier-python)
delimitar lo máximo posible el resultado final.
El aprendizaje no supervisado se divide en dos grandes grupos dependiendo de la forma
en la que se traten los datos de entrada:
Problemas de agrupación o clustering: Basados en el agrupamiento de caracte-
rísticas según unas similitudes, que pueden tener o no un sentido. Son muy utilizados
en los sistemas de recomendación.
Problemas de reducción de la densidad: Técnicas matemáticas y estadísticas
para transformar el conjunto de datos original en un nuevo conjunto de datos con
una dimensión más pequeña a cambio de cierta pérdida de información. Se utilizan
para representar de una forma más visual y sencilla los datos.
2.3.1. Algoritmos Aprendizaje No Supervisado
K-Medias (K-Means). El algoritmo KMedias es muy fácil de implementar y muy
eficiente computacionalmente. Éstas son las principales razones de su popularidad.
Sin embargo, para los grupos no esféricos, la identificación de clases no es muy
buena.
El algoritmo KMeans tiene como objetivo encontrar y clasificar puntos de datos
que son muy similares entre sí. Cuanto más cerca estén los puntos de datos entre
sí, es más probable que pertenezcan al mismo grupo.
Agrupación jerárquica. Alternativa al algoritmo K-Means, visto en el apartado
2.3.1. Este algoritmo, se caracteriza por no ser necesaria la especificación del número
9Técnicas de aprendizaje para la identificación de rapaces por restos óseos UCM
Figura 2.6: Diagrama de flujo del aprendizaje no supervisado. (Fuente:https://medium.
com/soldai/tipos-de-aprendizaje-automático-6413e3c615e2)
de grupos, que surgen por la unión de las distintas características similares. Además,
este algoritmo permite dibujarlo con un dendograma, véase la Figura 2.7, diagrama
que muestra las distancias de las características entre cada par de clases unidas
de manera secuencial. Esta forma de representación, nos permite observar que el
algoritmo se construye de abajo hacia arriba (bottom-up), en donde al principio,
cada característica es un grupo, las cuales se unen según su cercanía hasta que
todas las características forman parte de un único grupo [7].
2.4. Aprendizaje Máquina por Refuerzo
El aprendizaje máquina por refuerzo es un método de aprendizaje que implica recompen-
sar los comportamientos deseables y castigar los no deseados. Al aplicar este enfoque, los
agentes pueden reconocer e interpretar el entorno, actuar y aprender mediante prueba
y error. Está aprendiendo a establecer metas a largo plazo para obtener las máximas
recompensas generales y las soluciones óptimas. (Véase la Figura 2.8).
Una de las áreas más populares para probar el aprendizaje por refuerzo es el juego.
AlphaGo o Pacman son juegos que aplican esta técnica. En estos casos, el algoritmo
recibe información sobre las reglas del juego y aprende a jugar por su cuenta. Funciona
de forma aleatoria al principio, pero con el tiempo comienza a aprender movimientos más
complejos. Este tipo de aprendizaje también se aplica a otros campos como la robótica,
la relación calidad-precio y los sistemas de control.
10Técnicas de aprendizaje para la identificación de rapaces por restos óseos UCM
Figura 2.7: Ejemplo dendograma. (Fuente: https://www.jacobsoft.com.mx/es_mx/
clustering-jerarquico-con-python/)
Figura 2.8: Diagrama de flujo del aprendizaje por refuerzo. (Fuente: https://medium.
com/soldai/tipos-de-aprendizaje-automático-6413e3c615e2)
11Capítulo 3
Predicción de tipo de ave
En este capítulo se va a hacer una descripción detallada del algoritmo de predicción del
tipo de aves rapaces emblemáticas comparándolo con distintos modelos de aprendizaje
máquina supervisado.
3.1. Materiales y métodos
A continuación, se van a presentar los materiales utilizados para la realización de la
predicción y los distintos métodos que hemos tenido en cuenta al comparar los diferentes
modelos supervisados.
3.1.1. Materiales
Base de datos
La base de datos, número de registro 49/437736.9/21, utilizada para la comparación de
los algoritmos supervisados, ha sido proporcionada por Víctor García Matarranz agente
forestal del Ministerio para la Transición Ecológica y el Reto Demográfico (MITECO) y
Luis Revuelta Rueda. La elaboración de esta base de datos, fue realizada por ellos mismos
gracias a la obtención de distintos esqueletos privados y de diferentes museos de España,
permitiendo que Víctor García Matarranz los verificase como especialista que es.
La base de datos, es un archivo excel, en el que se recogen veintiséis especies diferentes
de aves, el Búho Real, el Gavilán, entre otras como se puede observar en la Figura 3.3.
Las especies forman las filas, mientras que las columnas son los ocho huesos más repre-
sentativos en el esqueleto de un ave rapaz, ( cráneo, húmero, radio, cúbito, coxal, fémur,
tibiotarso, tarsometatarso), en la base de datos se presentan once columnas, ya que el
hueso del cráneo y del coxal se deben medir en longitud y anchura.
En la Figura 3.1 se muestra un extracto de la base de datos utilizada.
3.1.2. Métodos
Estos métodos serán utilizados en la comparación de los diferentes algoritmos, sección
3.2.
12Técnicas de aprendizaje para la identificación de rapaces por restos óseos UCM
Figura 3.1: Base de datos. (Fuente: Elaboración propia)
Overfitting y Underfitting
El problema del Overfitting, sobre-entrenamiento en español, en el ámbito del machine
learning consiste en el aprendizaje erróneo de nuestro algoritmo con los datos suministra-
dos, ya que éste solo predecirá correctamente aquellos datos idénticos al entrenamiento.
Esto provoca que el algoritmo no sea capaz de distinguir datos factibles [8].
En cambio, el Underfitting, falta de entrenamiento en español, es lo opuesto al overfitting,
ya que este problema surge cuando los datos de entrenamiento del algoritmo son muy
escasos o no hay diversidad entre ellos, provocando sesgos en el resultado, excluyendo
datos válidos.
En la Figura 3.2 se puede observar una gráfica aclarativa del resultado esperado de nues-
tro modelo y lo que provoca los problemas de overfitting y underfitting.
Figura 3.2: Gráfica comparativa del Overfitting y Underfitting. (Fuente: https://www.
aprendemachinelearning.com/que-es-overfitting-y-underfitting-y-como-solucionarlo/)
Para evitar estos problemas, o que afecten los menos posible, se realizará: [9]
Obtención de una cantidad suficiente de datos para entrenar el modelo y validarlo.
Clases variadas y balanceadas, la cantidad y variedad de clases debe ser equitativa.
Dividir el conjunto de datos en entrenamiento y test.
13Técnicas de aprendizaje para la identificación de rapaces por restos óseos UCM
Técnica de sobre muestreo de minorías sintéticas
Este método conocido también por Synthetic Minority Oversampling Technique, a partir
de ahora SMOTE para abreviar, se utiliza para resolver el problema de overfitting y un-
derfitting que puedan presentar los modelos.
Nitesh Chawla, describió esta técnica como “la elección de los datos más cercanos en el
espacio de características entre dos datos de la clase minoritaria” [10]. Es decir, se elige
un dato “A” al azar y de los datos más cercanos a “A” se elige un “B”, se traza un
segmento en el espacio de características entre los datos “A” y “B”, generando un nuevo
dato “C” que pertenecerá al conjunto de datos [11]. Este método se puede utilizar para
crear tantos datos como sean necesarios.
En la Figura 3.3, se observa una gran diferencia entre la primera especie, la Perdicera,
frente a la última, el Circus Cyaneus, por tanto se realizará un balanceamiento de las
clases para que todas ellas tengan un conteo equitativo, facilitando el funcionamiento de
los algoritmos.
En nuestro modelo solo se aplica SMOTE a los datos de entrenamiento, con el objetivo
de tener mejores resultados.
Figura 3.3: Contador del número de especies que aparecen en la base de datos. (Fuente:
Elaboración propia)
3.2. Comparativa de los algoritmos del DataSet
Se han implementado los algoritmos árbol de decisión, SVM y random forest, vistos en
la sección 2.2.1, para nuestro modelo y estudiar su grado de eficacia.
14Técnicas de aprendizaje para la identificación de rapaces por restos óseos UCM
Para ello se ha realizado una tabla 3.1 comparativa entre los distintos algoritmos estu-
diados y su precisión sin aplicar SMOTE y aplicándolo.
Algoritmo score con SMOTE score sin SMOTE
Árbol de decisión 0.98 (+/- 0.03) 0.94 (+/- 0.05)
SVM 1.00 (+/- 0.00) 1.00 (+/- 0.00)
Random Forest 1.00 (+/- 0.01) 0.98 (+/- 0.02)
Cuadro 3.1: Comparativa de algortimos
La diferencia entre el score, precisión del algoritmo al predecir, aplicando SMOTE y
sin aplicarlo es mínima. Para nuestra elección nos basaremos en la columna de aplica-
ción con SMOTE, parqa evitar problemas de overfitting, sección 3.1.2, en nuestro modelo.
En la tabla 3.1 se muestra una ligera diferencia entre el algoritmo de árbol de precisión y
los de SVM y Random Forest. El árbol de decisión queda descartado por tener un score
inferior al de los otros dos algoritmos, aunque la precidicción haya sido válida, la del resto
fue superior.
A continuación, se debe decidir entre utilizar el SVM y el Random Forest. Como ambos
algoritmos tienen una precisión del 1.00, se decide utilizar en nuestro modelo el random
forest, porque es un método preciso, no sufre de overfitting y para este modelo parece el al-
goritmo más adecuado, ya que el SVM no es tan eficaz cuando hay muchas características
y no se puede asegurar un amplio margen entre los dos vectores más cercanos.
15Capítulo 4
Herramienta de desarrollo
Este capitulo trata la implementación de la aplicación web, desde la arquitectura seguida,
las tecnologías utilizadas para el desarrollo backend (Django, framework de Python) y las
del fronted (HTML5, lenguaje de marcas de hipertexto para la creación de las plantillas
web y CSS3, hojas de estilo en cascada para darle formato, diseño y estilo al documento
escrito en lenguaje de marcado), hasta las herramientas de trabajo que se han utilizado
para este proyecto.
La aplicación “Identificación de restos óseos de las aves rapaces emblematicas” se puede
visitar en el siguiente enlace [ http://sdelanieta.pythonanywhere.com ] y si lo que desea
es ver como se ha programado dicha aplicación, en este enlace encontrará el código fuente
[https://github.com/Enolah/djangoTFG].
4.1. Pruebas de arquitectura
Estas pruebas sirven para conocer si las tecnologías conocidas para aplicarse a la pro-
gramación web son viables para mi proyecto. Se han desarrollado dos prototipos con
las mismas funcionalidades básicas (pagina de inicio con enlace a otra página donde se
implementa el algoritmo), para su posterior evaluación, donde analizaremos las partes
positivas y negativas de la utilización de dichas tecnologías. Esto permite decidir cual de
las dos opciones es más viable para la construcción del software.
NODE.JS + JAVASCRIPT
JavaScript es un lenguaje de programación y scripting, encargado de dar dinamis-
mo e interactividad a las paginas web, complementándose con HTML y CSS para
añadir funciones avanzadas del lado cliente y así no construir una pagina plana
[12]. Siendo el numero tres en el índice de Popularidad PYPL de Febrero 2021 [13],
se le considera uno de los tres lenguajes nativos de la web (HTML, CSS, JavaScript).
Node.js es un entorno en tiempo de ejecución multiplataforma para la capa del
servidor basado en JavaScript. Pero no se debe confundir con un lenguaje de pro-
gramación o framework (plataforma para desarrollar aplicaciones software), ya que
es un entorno de ejecución que se utiliza para ejecutar JavaScript fuera del navega-
dor [14].
16Técnicas de aprendizaje para la identificación de rapaces por restos óseos UCM
Aunque Node.js puede utilizarse tanto para fronted como para backend, en este pro-
totipo se utilizó para construir el servidor de la app web, consta de una estructura
“Single Threaded Event Loops” pudiendo así manejar múltiples clientes al mismo
tiempo.En la Figura 4.1 se puede ver la arquitectura de Node.js.
Figura 4.1: Procesamiento de Node.js las peticiones entrantes utilizando el bucle de even-
tos. (Fuente: Elaboración propia)
En la Figura 4.1 se puede observar que es un modelo de solicitud-respuesta multihi-
lo,varios clientes envían una solicitud y el servidor procesa cada una de ellas antes
de devolver la respuesta. Sin embargo, se utilizan múltiples hilos para procesar las
llamadas concurrentes. Estos hilos se definen en un pool de hilos, y cada vez que
llega una petición, se asigna un hilo individual para manejarla [14].
Por ultimo, a Node.js le añadimos una serie de paquetes, que se explicarán después.
Los paquetes utilizados fueron:
1. Express: Framework basado en el módulo de HTTP que proporciona la posi-
bilidad de dividir la función callback que gestiona peticiones HTTP en varias
fases y mecanismos de alto nivel para acceder a algunas componentes de la
petición.
2. Express session: Gestiona el almacenamiento de sesiones. Este middleware
añade el atributo sesión al objeto request que contiene los datos de sesión
correspondientes al cliente que se está atendiendo.
3. Body-parser: Obtiene el cuerpo de la petición HTTP, interpreta su contenido
y modifica el objeto request añadiéndole un nuevo atributo (body).
4. Moment: Permite manejar fechas, es mas potente que la clase Date.
5. Nodemon: Monitoriza los cambios, en el momento que detecta un cambio
reinicia el servidor.
17Técnicas de aprendizaje para la identificación de rapaces por restos óseos UCM
6. Ejs: son documentos HTML con marcadores especiales de varios tipos. Utili-
zados en nuestra aplicación como plantillas o subplantillas.
Para la implementación de la web se utilizó EJS, el cual también es un lenguaje
de plantillas simples que permite generar lenguaje de marcado como HTML con
JavaScript simple. También nos permite crear subplantilla para no repetir código.
Es la opción mas utilizada a la hora de crear una aplicación con Node.js, ya que es
muy útil para generar HTML y contenido dinámico.
Una vez que se tiene una idea general de las tecnologías que vamos a utilizar para
este prototipo decidimos ponerlo a prueba y evaluar sus ventajas y desventajas.
• Ventajas.
Durante el transcurso de la carrera he tenido asignaturas que trataban estas
mismas tecnologías, sabiendo así ya utilizarlas.
Hay mucha documentación e información para crear una pagina web con esta
tecnología.
La aplicación puede ser dinámica e interactuar con el usuario a tiempo real.
La ejecución de un modelo vista controlador (MVC) es viable y sencilla de
implementar.
• Desventajas.
Poca información encontrada para la compatibilidad entre JavaScript y Python.
Para conseguir que el algoritmo funcionase era bastante complicado, no se con-
seguía una buena conexión.
DJANGO
Python es un lenguaje de programación orientado a objetos de alto nivel con se-
mántica dinámica incorporada, principalmente para desarrollar aplicaciones web y
de escritorio. Esta es una opción multiplataforma con bibliotecas e intérpretes gra-
tuitos disponibles [15].
La empresa The World Company of Lawrence en Kansas, Estados Unidos, contaba
con un grupo de desarrolladores que decidieron hacer una serie de aplicaciones en
PHP para optimizar los procesos de la empresa, en 2003 cambiaron de lenguaje de
programación a Python.
Después de un proceso de múltiples mejoras consiguieron desarrollar un framework
muy potente, llamado Django.
EN 2005, lanzaron Django como código abierto, facilitando que la comunidad de
desarrolladores aportase mejoras, soporte y usabilidad. Así es como Django empezó
a darse a conocer. No fue hasta 2008 cuando Django obtuvo las características base
por las que actualmente es conocido:
• Es muy rápido programar una aplicación web funcional.
• Contiene funcionalidades ya creadas para facilitar el desarrollo, por ejemplo,
la autenticación de un usuario.
• Solución de problemas de seguridad.
18Técnicas de aprendizaje para la identificación de rapaces por restos óseos UCM
• Escalable.
• Puede utilizarse para aplicaciones de cualquier tipo.
• Integración del patrón Modelo Vista Controlador en su implementación.
Aunque Django tiene una forma distinta de implementar el MVC, siendo Modelo
Template Vista (MTV), esta última característica ha sido la más importante para
el desarrollo del prototipo.
Hoy en día, Django, se utiliza en aplicaciones como Instagram, Mozilla, entre otras.
Una vez que se tiene una idea general de las tecnologías que vamos a utilizar para
este prototipo decidimos ponerlo a prueba y evaluar sus ventajas y desventajas.
• Ventajas.
Hay una comunidad muy grande con una amplia documentación.
En constante progreso y mejoras.
Muchas funcionalidades ya implementadas que ahorran trabajo al programa-
dor.
Incluye el patrón Modelo Template Vista (MTV).
Al pertenecer al mismo lenguaje de programación, el algoritmo se acopla muy
bien al desarrollo de la aplicación web.
• Desventajas.
Nuevo framework no visto anteriormente
4.2. Arquitectura
La arquitectura usada en la aplicación es la mostrada en la figura 4.2, en ella podemos
observar el patron Modelo Template Controlador (MTV para abreviar), que divide la
aplicación en tres componenetes.
Figura 4.2: Ejemplo de un servidor en Django. (Fuente: Elaboración propia)
19Técnicas de aprendizaje para la identificación de rapaces por restos óseos UCM
El modelo contiene la funcionalidad básica entre datos.
La vista media entre el modelo y el template.
El template decide la forma en la que se muestra la información.
4.3. Implementación
A continuación, se relatará la implementación seguida para la creación de la página web.
4.3.1. Backed
Primero se implementa un entorno virtual, aislando la configuración de nuestra aplica-
ción, evitando conflictos con otros posibles proyectos.
Figura 4.3: Esquema de Django. (Fuente: Elaboración propia)
A continuacion, desarrollamos el servidor Django, programado en Python, dentro de
nuestro entorno virtual. Django genera inicialmente una estructura de proyecto, véase
Figura 4.3, respetando el patrón MTV.
Models.py: Archivo donde esta la información de la base de datos, en el proyecto
no se le da uso a este archivo, ya que la base de datos proporcionada no necesita
ser modificada, solo leerla una única vez al inicio para el algoritmo.
View.py: Archivo que contiene los métodos, funciones necesarios para el correcto
desarrollo de la aplicación web.
20Técnicas de aprendizaje para la identificación de rapaces por restos óseos UCM
Peticiones HTTP
Descripción GET/POST URL
Página principal/Inicio GET /
Página de contacto GET /contacto
Página de recursos GET /descargas
Página de identificación GET /iden
Cálculo del algoritmo de predicción POST /calcular
Cuadro 4.1: peticiones HTTP
Urls.py: Archivo donde se almacenan todas las urls, peticiones HTTP que pueden
realizarse dentro de la aplicacion web. 4.1
Templates: Carpeta donde se ubican todos los archivos HTML que se utilizan en
la aplicación.
Además de éstas, se han implementado dos nuevas, que nos ayudarán a tener más orga-
nizado y mejorar la lectura del código, puede verse la nueva estructura del proyecto en
la Figura 4.4
Figura 4.4: Esquema de Django versión 2. (Fuente: Elaboración propia)
prediccion.py: Clase que contiene la codificación del modelo utilizado para la
prediccion del tipo de aver.
read data.py: Clase que lee la base de datos proporcionada.
Se instalan en el entorno virtual,los paquetes de librerías necesarios para que funcione
correctamente nuestra aplicación.
21Técnicas de aprendizaje para la identificación de rapaces por restos óseos UCM
et-xmlfile, xlrd, openpyxl: Librerías que permiten abrir la base de datos creada
en excel, con extensión “.xlsx”.
imbalanced-learn, imblearn: Librería utilizada para la aplicación del SMOTE.
numpy: Librería de Python que proporciona un objeto de matriz multidimensional,
y el el objeto ndarray [16].
pandas: Librería que proporciona estructuras de datos y herramientas de análisis
de datos de alto rendimiento [17].
scikit-learn: Librería que proporciona herramientas simples y eficientes para el
análisis predictivo de datos [18].
En el proyecto hay otras librerías que se descargan al instalar alguna de las mencionadas
anteriormente, por eso no son comentadas. Las importantes son de las que ya he hablado.
4.3.2. Fronted
Las plantillas se han desarrollado con HTML5 y CSS3 [19]. Lo más característico de estas
plantillas es el uso de herencia entre las plantillas para evitar la duplicidad del código. Hay
una plantilla “padre” que contiene el encabezado, barra de navegación y pie de pagina, y
el resto de plantillas heredan de ella.
Con CSS3 se ha dado todo el estilo a la pagina web y se ha hecho una web responsive, es
decir, cambia según el tamaño del dispositivo.
4.4. Despliegue
Para el despliegue del servidor del proyecto se ha utilizado Pythonanywhere [20], por
su comodidad al ser un servidor exclusivamente de python. Tiene accesos a la versión
mas actual de python y se le pueden instalar todas las librerías necesarias para que la
aplicación funcione correctamente.
Pythonanywhere permite un hospedaje gratuito, de hasta 512MB, al crear una cuenta
con ellos, y una enlace para la aplicación web. Para este proyecto se ha tenido que ampliar
el almacenamiento en disco para facilitar la subida de elementos estáticos y la instalación
de las librerías.
Los pasos a seguir para hacer el despliegue son muy sencillos:
1. Crear una cuenta en Github, repositorio online gratuito para la gestión y el control
de versiones dentro de tu proyecto.
2. Crear un repositorio para guardar el proyecto.
3. Crear una cuenta de Pythonanywhere.
4. Desde la “API Token” , crear nueva API Token.
5. Abrir una terminal Bash donde descargarás tu código de GitHub en Pythonanywhe-
re.
6. Instalar los paquetes necesarios para el correcto funcionamiento de la aplicación.
22Técnicas de aprendizaje para la identificación de rapaces por restos óseos UCM
4.5. Herramientas de trabajo
A continuación se describen las distintas herramientas que se han utilizado en la imple-
mentación de la aplicación web.
Visual Studio Code: Visual Studio Code es un editor de texto sin formato, de
código abierto y gratuito. Desarrollado por Microsoft, proporciona a los usuarios
herramientas de programación avanzadas. A través de comandos de Git le da al
editor un verificador de versión completo.
Por esta razón, Microsoft ha decidido hacer de Visual Studio Code un editor modu-
lar totalmente personalizable a través de complementos. Microsoft y otros desarro-
lladores pueden compartir el complemento y extender Visual Studio Code a través
de un repositorio de extensiones.
Ha sido utilizado para la programación de la aplicación web y de los prototipos, ya
que permite la compatibilidad entre muchos lenguajes de programación.
Anaconda Navigator - Jupyter Notebook: Navigator Anaconda es un espacio
de trabajo de ciencia de datos que permite ejecutar aplicaciones y administrar fácil-
mente varios paquetes. El navegador Anaconda te permite trabajar con el lenguaje
Python de una manera más amigable, pero gracias a Jupyter Notebook, puedes
crear bloques de programa en Python y controlarlos de forma interactiva bloque a
bloque. Ha sido utilizado para la creación de los modelos y comparar sus grados de
ajuste.
GitHub: Repositorio online gratuito para la gestión y el control de versiones dentro
de tu proyecto. Ha sido utilizado para el almacenamiento de todo el código de la
aplicación web.
Google Drive: Servicio de almacenamiento en la nube, que proporciona Google.
Ha sido utilizado para compartir archivos de interés para la realización del proyecto,
y la base de datos utilizada.
Pythonanywhere: Servicio de hospedaje exclusivamente para aplicaciones python.
Se ha utilizado como servidor Python para desplegar la aplicación web.
23Capítulo 5
Descripción de la aplicación web
Este capítulo trata el diseño de la aplicación web. Primero se realiza un análisis de la
competencia mediante el cual se estudiarán otras aplicaciones web con funcionalidades
parecidas, es decir, la competencia del mercado. Continúa describiendo posibles escenarios
reales en los que la aplicación podría ser usada, y a partir de estos escenarios se extraen
los requisitos funcionales. Por último, detallaremos con imágenes las interfaces de usuario
que presenta la aplicación.
5.1. Análisis de la competencia
Para hacer un estudio de mercado más específico, se necesita saber las principales ventajas
que presenta la aplicación web frente a la competencia.
Identificación rápida y fiable.
Adaptación a móviles, tabletas por su cómoda visualización.
Interfaz intuitiva.
La competencia se caracteriza por la ornitología, estudio de las aves. Y las principales
características que presenta son:
Gran variedad de aves para el estudio.
La exploración se basa en la observación de aves en su entorno natural, ecosistema.
Las diferencias entre la aplicación y la competencia son muy evidentes, por tanto, no
encontramos un mercado que presente una amenaza para la aplicación, ya que ésta es
diferente a las demás páginas webs. Se centra en los restos óseos, no influyen características
como el color, las plumas, entre otras.
Además, la aplicación consta de una sección donde puedes conseguir información sobre
las aves analizadas e incluso instrucciones para identificar cada hueso y cómo se realizan
las mediciones por expertos.
5.2. Escenarios de uso
Antes del desarrollo de la implementación se decidió establecer una serie de escenarios en
los que la aplicación fuese usada. Así, se pudo describir que funcionalidades eran las más
necesarias para los usuarios.
24Técnicas de aprendizaje para la identificación de rapaces por restos óseos UCM
Los escenarios descritos a continuación son distintas situaciones del mundo real en las que
los futuros usuarios de nuestra aplicación se podrían encontrar y necesitar la aplicación
para darle solución a su problema.
Escenario 1. Reconocimiento al aire libre.
Un senderista o grupo de senderistas realizan una ruta cuando se percatan de un
ave en estado de descomposición. Antes de llamar al Servicio de Protección de la
Naturaleza (SEPRONA), el caminante desea saber de qué ave se trata. Por tanto,el
usuario puede lanzar la aplicación desde su móvil, poner los datos de los huesos
que haya podido medir para saber de qué ave se trata y así proporcionar más
información al SEPRONA cuando llamen.
Escenario 2. Reconocimiento cultural y/o científico.
En el caso de casas museo, colegios que tiene aves disecadas o disponen de restos
óseos sin identificar. Entonces, el usuario con un dispositivo con acceso a internet
podrá acceder a la aplicación y meter los datos e incluso se puede consultar las
guías de identificación de restos óseos [21], [22]. Y así, se podrán poner los restos
de exposición o enseñárselos a visitantes, alumnos o cualquier persona que quiera
aprender más sobre las aves.
Escenario 3. Reconocimiento policial.
El SEPRONA tiene que lidiar diariamente contra la caza furtiva, y esta aplicación
puede serles muy útil para la identificación del ave al momento de encontrarlo y así
acelerar el proceso de detención de los cazadores o encontrar a los culpables.
5.3. Requisitos funcionales
En esta sección se describe los requisitos funcionales de la aplicación. Con estos requisitos
se pretende mostrar los servicios que proporciona la aplicación. Se han dividido en tres
servicios:
Servicio de contacto: Zona de la aplicación donde aparecen los datos de contacto
de la Universidad Complutense, guía de aves cedida para este proyecto, el Ministerio
para la Transición Ecológica y el Reto Demográfico (MITECO) y los autores de las
fotografías que aparecen en la aplicación.
Servicio de información: Zona de la aplicación donde los usuarios pueden des-
cargar las dos guías creadas por Víctor García Matarraz para aprender más sobre
la medición e identificación de restos óseos. Así, como un archivo con una serie de
números telefónicos para llamar en caso de encontrarse algún ave muerto.
Servicio de predicción de aves rapaces emblemáticas según sus restos
óseos: Zona de la aplicación donde reside el algoritmo de predicción de aves rapaces
a partir de sus restos óseos descrito en el Capítulo 3, que a partir de una interfaz
intuitiva para los usuarios se facilita su uso.
25Técnicas de aprendizaje para la identificación de rapaces por restos óseos UCM
5.4. Interfaz de usuario
La descripción de las distintas interfaces que forman la aplicación web se hará en base
al diseño web para un monitor, para dispositivos como móviles y tabletas, se mostrará
una imagen, su funcionamiento es igual pero la vista cambia dependiendo del dispositivo
desde el que se accede.
5.4.1. Interfaz Principal
Es la interfaz “base” de nuestra aplicación, se puede ver en la Figura 5.1, ya que en ella
se presentan las distintas características que se repetirán también en el resto de vistas.
En la parte superior se presenta el nombre de la aplicación web.
Debajo del nombre se puede observar la barra de navegación, desde la cual podremos
acceder a cualquiera de las otras interfaces restantes.
En la parte inferior de la vista se encuentra el pie de página con el logotipo de la
Universidad Complutense de Madrid y el correspondiente con MITECO.
La diferencia con el resto de vistas es la presentación de bienvenida al usuario, un pequeño
muestrario de aves (con sus respectivos nombres) y un botón que nos dirige directamente
a la interfaz de identificación, Figura ??.
Figura 5.1: Página inicio de la aplicación. Formato monitor. (Fuente: Elaboración propia)
5.4.2. Interfaz Identificación
En esta interfaz se puede observar las mismas características presentadas en la interfaz
principal 5.4.1. Esta vista se presenta en formato “pantalla dividida”, en la que cada
división cambiara dependiendo de la interacción del usuario:
26Técnicas de aprendizaje para la identificación de rapaces por restos óseos UCM
1. Todavía no se ha introducido ningún dato 5.2:
La parte de la izquierda observamos el formulario que podrán rellenar (entero o no)
con los datos de los restos óseos.
La parte de la derecha, se muestra con una imagen de un esqueleto de ave rapaz en
el cual se han asignado los nombres de los huesos correspondientes, para permitir
al usuario localizarlos mas fácilmente.
Figura 5.2: Página de identificación de la aplicación antes de introducir valores. Formato
monitor.(Fuente: Elaboración propia)
2. Se ha calculado la predicción 5.3:
La parte de la izquierda se mantiene igual, borrándose los datos de entrada.
La parte de la derecha, donde antes veíamos la imagen del esqueleto, ahora se
mostrara los resultados obtenidos de la predicción.
5.4.3. Interfaz Contacto
En esta interfaz se puede observar las mismas características presentadas en la interfaz
principal 5.4.1. En esta vista se pueden leer los datos de contacto de las personas encarga-
das de la investigación y de la idea en el tema de la identificación de restos óseos. También
se cuenta brevemente el motivo que impulso esta aplicación web y el reconocimiento a los
autores de las fotografías y documentos utilizados en la aplicación. Véase la Figura 5.4.
27Técnicas de aprendizaje para la identificación de rapaces por restos óseos UCM
Figura 5.3: Página de identificación de la aplicación mostrando los resultados obtenidos.
Formato monitor.(Fuente: Elaboración propia)
Figura 5.4: Página de contacto. Formato monitor.(Fuente: Elaboración propia)
28Técnicas de aprendizaje para la identificación de rapaces por restos óseos UCM
5.4.4. Interfaz Recursos
En esta interfaz se puede observar las mismas características presentadas en la interfaz
principal 5.4.1. En esta vista se muestran varios enlaces de descarga, para poder visualizar
desde nuestro dispositivo o descargar los documentos presentes. Véase la Figura 5.5.
Figura 5.5: Página de recursos para descargar. Formato monitor.(Fuente: Elaboración
propia)
5.5. Navegación entre interfaces
A continuación, se explicará el diagrama mostrado en la [figura]. Este diagrama muestra
la manera en que se puede navegar entre las distintas interfaces de la aplicación.
1. El usuario accede a la aplicación y se encuentra la página de inicio con tres opciones
a elegir, podrá ir a “recursos”, “contacto” o pulsar el botón comenzar si quiere ir a
la pantalla de “identificación”. Desde cualquier pantalla se podrá volver a la anterior
u otra cualquiera.
2. Si elige ir a “recursos”, solo tendrá que seleccionar en el menú de arriba de la
aplicación la opción “recursos” que le llevará a esa pantalla. Una vez ahí, podrá
descargar los archivos que desee. Si después desea ir a “contacto” mira el paso 3,
por el contrario si quiere navegar al “inicio” mire el paso 1.
3. Si elige ir a “contacto”, solo tendrá que seleccionar en el menú de arriba de la
aplicación la opción ir a “contacto” que le llevará a esa pantalla. Una vez ahí, podrá
leer la información de contacto de los autores que han colaborado en la aplicación.
Si después desea ir a “recursos” mira el paso 2, por el contrario si quiere navegar al
“inicio” mire el paso 1.
4. Si elige pulsar el botón “comenzar”, irá directamente a la pantalla de “identifica-
ción” allí podrá ingresar en el formulario los datos correspondientes a los restos
óseos que haya medido. Una vez introducidos, podrá realizar tres opciones: “res-
taurar”,“limpiar” o “calcular”.
29También puede leer

















































