Sistema de Web Scraping orientado a portales del ámbito inmobiliario - Álvaro Torrente Patiño
←
→
Transcripción del contenido de la página
Si su navegador no muestra la página correctamente, lea el contenido de la página a continuación
Sistema de Web Scraping orientado a portales
del ámbito inmobiliario
Álvaro Torrente Patiño
Tutores: Adrián Carballal Mato y Juan Jesús Romero Cardalda
Curso 2020/2021
Álvaro Torrente Patiño Sistema de Web Scraping orientado a portales del ámbito inmobi- liario Trabajo Fin de Máster. Curso 2020/2021 Tutores: Adrián Carballal Mato y Juan Jesús Romero Cardalda Máster Inter-Universitario en Ciberseguridade Universidade da Coruña Facultade de Informática Coruña Campus de Elviña s/n 15071, A Coruña
Abstract
In this project we have implemented a Web Scraping system that obtains information
from real estate portals, as well as downloading images of the properties.
This project has been developed in connection with the internship for the University
of A Coruña (UDC) in the department of the Research Center for ICT (CITIC).
The Web Scraping system has been developed in the Python programming language
and integrated into the PhotoILike web tool with the help of Docker technology.
Keywords — web scraping, real estate, python, docker
iii
Resumen
En este proyecto se ha implementado un sistema de Web Scraping que obtiene
información de portales inmobiliarios, así como la descarga de las imágenes de los
inmuebles.
Este proyecto se ha desarrollado en relación con la realización de las prácticas en
empresa para la Universidade da Coruña (UDC) en el departamento del Centro de
Investigación en Tecnologías de la Información y las Comunicaciones (CITIC).
El sistema de Web Scraping se ha desarrollado en el lenguaje de programación
Python e integrado en la herramienta web PhotoILike con la ayuda de la tecnología
Docker.
Palabras clave — web scraping, web crawlers, data mining, portales inmobiliarios,
python, docker
v
Índice general
Índice de figuras ix
Índice de tablas xi
Listado de extractos de código xiii
1. Introducción 1
1.1. Motivación . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2. Objetivos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.3. Organización de la memoria . . . . . . . . . . . . . . . . . . . . . . . 2
2. Fundamentos tecnológicos 3
2.1. Python . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2.2. Scrapy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.2.1. scrapy-fake-useragent . . . . . . . . . . . . . . . . . . . . . . 5
2.3. Requests . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.4. Pillow . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.5. Docker . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.6. GitHub . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.7. Microsoft Teams . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.8. Trello . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
3. Situación actual 17
3.1. Marco teórico . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
3.1.1. Web Crawlers (Rastreadores Web) . . . . . . . . . . . . . . . 17
3.1.2. Web Scraping . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
3.1.3. Defensa y prevención contra el Web Scraping . . . . . . . . . 18
3.1.4. Legalidad del Web Scraping . . . . . . . . . . . . . . . . . . . 21
3.1.5. Consecuencias legales del Web Scraping . . . . . . . . . . . . 22
3.1.6. Data Mining (Minería de Datos) . . . . . . . . . . . . . . . . 24
3.2. Tecnologías base . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
3.2.1. Herramientas de línea de comandos: Wget y cURL . . . . . . 25
3.2.2. Librerías para Python: Requests, Scrapy, Selenium y Beautiful
Soup . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
vii
3.3. Trabajos relacionados . . . . . . . . . . . . . . . . . . . . . . . . . . 26
3.3.1. ParseHub . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
3.3.2. Webhose.io . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
3.3.3. Octoparse . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
3.3.4. OutWit Hub . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
4. Metodología 33
4.1. Planificación . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
4.2. Análisis de riesgos . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
4.3. Costes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
4.3.1. Recursos humanos . . . . . . . . . . . . . . . . . . . . . . . . 37
4.3.2. Recursos materiales . . . . . . . . . . . . . . . . . . . . . . . 37
4.4. Seguimiento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
5. Trabajo realizado 41
5.1. Configuración del entorno de trabajo y herramientas . . . . . . . . . 41
5.2. Análisis de portales inmobiliarios . . . . . . . . . . . . . . . . . . . . 42
5.3. Diseño e implementación del sistema de Web Scraping . . . . . . . . 49
5.4. Pruebas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
5.5. Implantación del sistema . . . . . . . . . . . . . . . . . . . . . . . . . 57
6. Resultados 61
6.1. Funcionalidades . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
6.2. Problemas encontrados . . . . . . . . . . . . . . . . . . . . . . . . . . 62
6.3. Soluciones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
7. Conclusiones 65
7.1. Resumen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
7.2. Limitaciones y trabajo futuro . . . . . . . . . . . . . . . . . . . . . . 65
Bibliografía 67
A. Apéndice 71
A.1. Terminología . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71
A.2. Acrónimos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71
viii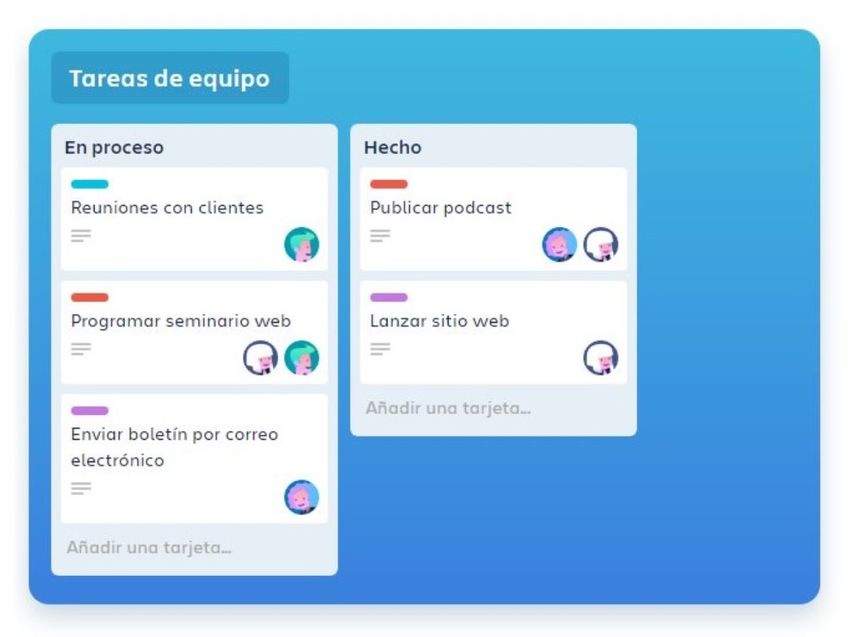
Índice de figuras
2.1. Análisis en detalle de un User-Agent a través de UserAgentString.com. 5
2.2. Imagen original cargada con Pillow. . . . . . . . . . . . . . . . . . . . . . 8
2.3. Imagen redimensionada y girada con Pillow. . . . . . . . . . . . . . . . . 8
2.4. Funcionamiento de la herramienta Docker. . . . . . . . . . . . . . . . . . 9
2.5. Diferencias entre arquitecturas. . . . . . . . . . . . . . . . . . . . . . . . 11
2.6. Ejemplo de una rama (branch) en un proyecto de desarrollo. . . . . . . . 12
2.7. Plataforma de comunicación Microsoft Teams. . . . . . . . . . . . . . . . 13
2.8. Tablero de tareas de Trello con dos columnas. . . . . . . . . . . . . . . . 15
3.1. CAPTCHA textual (reCAPTCHA v1). . . . . . . . . . . . . . . . . . . . 19
3.2. CAPTCHA visual (reCAPTCHA v2). . . . . . . . . . . . . . . . . . . . 20
3.3. CAPTCHA “no soy un robot” (reCAPTCHA v2+). . . . . . . . . . . . . 20
3.4. CAPTCHA invisible (reCAPTCHA v3). . . . . . . . . . . . . . . . . . . 21
3.5. Planes de pago de ParseHub. . . . . . . . . . . . . . . . . . . . . . . . . 26
3.6. Uso de ParseHub sobre un comercio electrónico. . . . . . . . . . . . . . . 27
3.7. Planes de pago de Webhose. . . . . . . . . . . . . . . . . . . . . . . . . . 27
3.8. Uso de Octoparse sobre un comercio electrónico. . . . . . . . . . . . . . . 29
3.9. Uso de OutWit Hub sobre una entrada de Wikipedia. . . . . . . . . . . . 31
4.1. Ciclo de desarrollo SCRUM. . . . . . . . . . . . . . . . . . . . . . . . . . 33
4.2. Diagrama de Gantt. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
4.3. Recursos hardware. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
4.4. Diagrama de Gantt de seguimiento. . . . . . . . . . . . . . . . . . . . . . 39
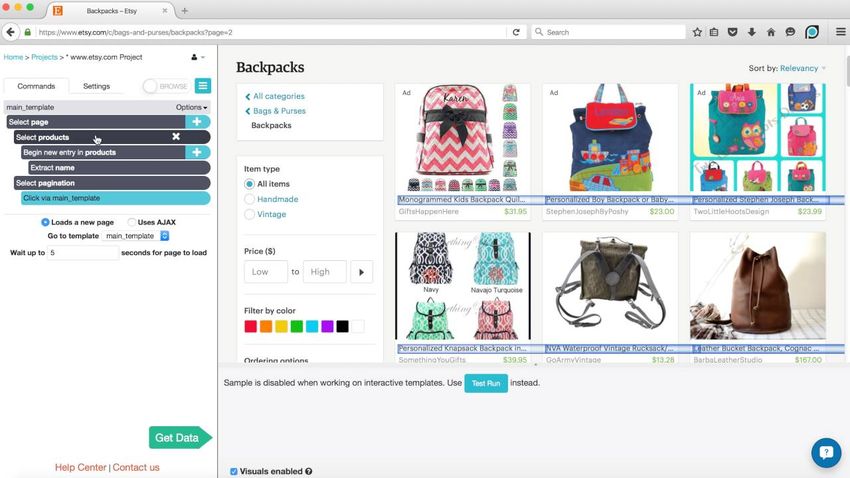
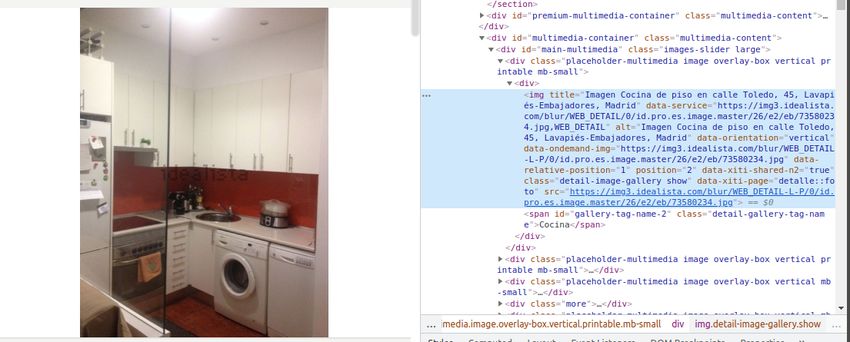
5.1. Inspección de elementos de Idealista. . . . . . . . . . . . . . . . . . . . . 42
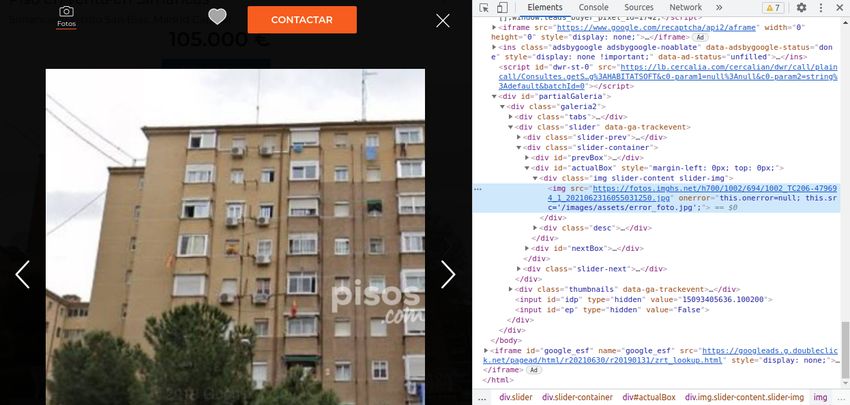
5.2. Inspección de elementos de Fotocasa. . . . . . . . . . . . . . . . . . . . . 44
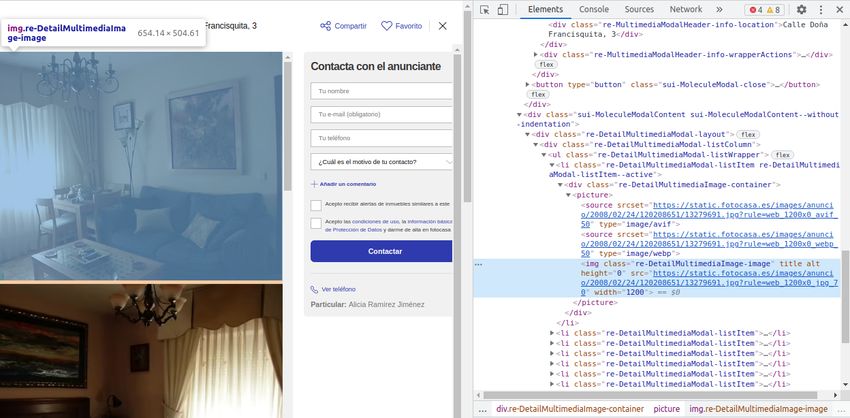
5.3. Inspección de elementos de Pisos.com. . . . . . . . . . . . . . . . . . . . 47
5.4. Funcionamiento básico del sistema de Web Scraping. . . . . . . . . . . . 51
5.5. Esquema de integración del sistema de Web Scraping con PhotoILike. . . 57
5.6. Web Scraping integrado en PhotoILike.com. . . . . . . . . . . . . . . . . 58
5.7. Correo electrónico con los resultados del Web Scraping. . . . . . . . . . . 58
6.1. Correlación del precio y la superficie de los inmuebles. . . . . . . . . . . 61
6.2. Correlación del precio y la puntuación media de las imágenes. . . . . . . 62
ix
6.3. reCAPTCHA (v3) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63 x
Índice de tablas
4.1. Tareas del proyecto. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
4.2. Análisis de riesgos. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
4.3. Coste personal del proyecto. . . . . . . . . . . . . . . . . . . . . . . . . . 37
4.4. Presupuesto materiales. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
4.5. Reestructuración tareas del proyecto. . . . . . . . . . . . . . . . . . . . . 38
5.1. Pruebas de rendimiento para Pisos.com. . . . . . . . . . . . . . . . . . . 55
5.2. Pruebas de rendimiento para Fotocasa. . . . . . . . . . . . . . . . . . . . 55
5.3. Pruebas de rendimiento para Pisos.com con PhotoILike. . . . . . . . . . 56
5.4. Pruebas de rendimiento para Fotocasa con PhotoILike. . . . . . . . . . . 56
xiListado de extractos de
código
2.1. Instalación de Python en Ubuntu. . . . . . . . . . . . . . . . . . . . . . 3
2.2. Comprobación de la versión de Python en Ubuntu. . . . . . . . . . . . . 3
2.3. Instalación de Scrapy con pip. . . . . . . . . . . . . . . . . . . . . . . . 4
2.4. Comandos y uso de Scrapy. . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.5. Instalación de scrapy-fake-useragent con pip. . . . . . . . . . . . . . . . 6
2.6. Configuración básica de un User-Agent. . . . . . . . . . . . . . . . . . . 6
2.7. Instalación de Requests con pip. . . . . . . . . . . . . . . . . . . . . . . 7
2.8. Uso de Requests con Python. . . . . . . . . . . . . . . . . . . . . . . . . 7
2.9. Instalación de Pillow con pip. . . . . . . . . . . . . . . . . . . . . . . . . 7
2.10. Uso de Pillow con Python (1). . . . . . . . . . . . . . . . . . . . . . . . 8
2.11. Uso de Pillow con Python (2). . . . . . . . . . . . . . . . . . . . . . . . 8
2.12. Instalación de Docker en Ubuntu. . . . . . . . . . . . . . . . . . . . . . 9
2.13. Comprobación de la versión e información de Docker. . . . . . . . . . . 9
2.14. Ejemplo de un fichero Dockerfile. . . . . . . . . . . . . . . . . . . . . . . 10
2.15. Contenido de requirements.txt. . . . . . . . . . . . . . . . . . . . . . . . 10
2.16. Creación de la imagen y ejecución del contenedor con Docker. . . . . . 11
2.17. Descarga del repositorio. . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2.18. Commit de los cambios en el repositorio. . . . . . . . . . . . . . . . . . 12
2.19. Creación de la rama “develop”. . . . . . . . . . . . . . . . . . . . . . . . 12
2.20. Fusión de ramas y etiquetado de versión. . . . . . . . . . . . . . . . . . 13
3.1. Ejemplo de un fichero ‘robots.txt’ con dos reglas definidas. . . . . . . . 19
5.1. Fragmento del código fuente de Idealista (imágenes). . . . . . . . . . . . 42
5.2. Patrón en las URL de las imágenes de Idealista. . . . . . . . . . . . . . 43
5.3. Fragmento del código fuente de Idealista (características). . . . . . . . . 43
5.4. Fragmento del código fuente de Fotocasa (imágenes). . . . . . . . . . . 44
5.5. Patrones en las URL de las imágenes de Fotocasa. . . . . . . . . . . . . 45
5.6. Fragmento del código fuente de Fotocasa (precio). . . . . . . . . . . . . 45
5.7. Fragmento del código fuente de Fotocasa (características). . . . . . . . 46
5.8. Fragmento del código fuente de Fotocasa (características extra). . . . . 46
xiii5.9. Fragmento del código fuente de Pisos.com (imágenes). . . . . . . . . . . 47
5.10. Patrón en las URL de las imágenes de Pisos.com. . . . . . . . . . . . . 47
5.11. Fragmento del código fuente de Pisos.com (características). . . . . . . . 48
5.12. Creación del proyecto ‘realestate’. . . . . . . . . . . . . . . . . . . . . . 49
5.13. Contenido del proyecto ‘realestate’. . . . . . . . . . . . . . . . . . . . . . 49
5.14. Esqueleto de un ‘spider’. . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
5.15. Comando de scrapy. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
5.16. Datos almacenados en el fichero JSON. . . . . . . . . . . . . . . . . . . 51
5.17. Inicialización del scraper al ejecutarse. . . . . . . . . . . . . . . . . . . . 52
5.18. Resultado del comando de scrapy. . . . . . . . . . . . . . . . . . . . . . 53
5.19. Contenido del fichero ‘fotocasa-158207288.txt’. . . . . . . . . . . . . . . 54
5.20. Contenido del fichero ‘fotocasa-158207288-features.txt’. . . . . . . . . . 54
5.21. Contenido del fichero ‘fotocasa-158207288-price.txt’. . . . . . . . . . . . 54
5.22. Datos obtenidos con el API de PhotoILike. . . . . . . . . . . . . . . . . 59
5.23. Características obtenidas del inmueble. . . . . . . . . . . . . . . . . . . 60
6.1. Ejecución de scrapy sobre el portal Idealista. . . . . . . . . . . . . . . . 63
xivIntroducción 1
1.1 Motivación
Este proyecto se realiza en relación con las prácticas en empresa del Máster para la
Universidade da Coruña (UDC) en el departamento del Centro de Investigación en
Tecnologías de la Información y las Comunicaciones (CITIC).
El proyecto de investigación Indest (Progama IGNICIA) llevado a cabo en la
Universidade da Coruña, tiene como objetivo crear un sistema de predicción estética
para las imágenes de un inmueble, y de esta forma seleccionar aquellas imágenes
más atractivas para los posibles compradores que visiten un portal inmobiliario.
Este sistema de predicción estética recibe el nombre de PhotoILike.
A raíz de esto, surgió la necesidad de la creación de la herramienta de Web Scraping
para complementar al sistema de predicción, para lo cual se contrató al alumno.
1.2 Objetivos
El objetivo principal del trabajo a realizar es el diseño, implementación, pruebas
e implantación de un sistema de Web Scraping orientado a portales del ámbito
inmobiliario. El Web Scraping o raspado web, es una técnica utilizada para extraer
información de sitios web simulando la navegación de un humano. Esta herramienta
deberá permitir evadir los distintos métodos existentes para evitar la adquisición
automatizada de información en este tipo de portales.
El desarrollo de dicha herramienta estará basada en el lenguaje de programación
Python y focalizada para su implantación en una infraestructura cloud (p.e. AWS)
con ayuda de la tecnología Docker para automatizar el despliegue de la herramienta.
Como objetivos secundarios se contempla el aprendizaje de los conceptos que abarcan
los ámbitos de seguridad y legislativo sobre el Web Scraping, es decir, qué medidas
de seguridad protegen frente al Web Scraping y cómo evitarlas, y hasta qué punto
es legal realizarlo y sus consecuencias.
11.3 Organización de la memoria
En el Capítulo 1 “Introducción”, se expone la motivación y los objetivos que se
buscan conseguir con la realización de este proyecto.
En el Capítulo 2 “Fundamentos tecnológicos”, se indican cuales han sido las tecno-
logías empleadas para conseguir los objetivos que han sido expuestos en el primer
capítulo.
En el Capítulo 3 “Situación actual”, se evalúa el estado de la cuestión en lo referente
al Web Scraping.
En el Capítulo 4 “Metodología”, se indica cómo se ha estructurado el proyecto y la
elección de la metodología de trabajo.
En el Capítulo 5 “Trabajo realizado”, se realiza el análisis de requisitos y se detalla
cada una de las fases de desarrollo según la metodología escogida.
En el Capítulo 6 “Resultados”, se exponen los resultados obtenidos al finalizar el
desarrollo del proyecto junto con el grado de satisfacción de sus funcionalidades.
En el Capítulo 7 “Conclusiones”, se comentan los puntos positivos y negativos del
proyecto, así como las posibilidades de mejora que se podrían añadir a partir del
desarrollo realizado en este proyecto.
2 Capítulo 1 IntroducciónFundamentos tecnológicos 2
En este capítulo se realiza una revisión de las tecnologías que se emplean para el
desarrollo de la solución al problema a resolver.
2.1 Python
Python [Pyt20] es un lenguaje de programación interpretado y orientado a objetos
disponible prácticamente para cualquier sistema operativo actual. Es un lenguaje
muy potente y versátil debido a su tipado dinámico1 , dispone de gran cantidad de
librerías y gestión automática de la memoria.
Es un lenguaje muy popular en la comunidad científica ya que es una alterna-
tiva libre a MatLab y R (herramientas software matemáticas). También es muy útil
para el desarrollo de páginas web gracias a frameworks como Django o Flask. Puede
integrarse fácilmente con otros lenguajes de programación como C/C++ o Fortran
(entre otros).
Actualmente se encuentra en la versión 3.9, sin embargo se ha establecido como
requisito mínimo la versión 3.6, ya que es la mínima para las librerías necesarias
para el funcionamiento de la herramienta.
Cód. 2.1: Instalación de Python en Ubuntu.
sudo apt update
sudo apt install python3-pip
Cód. 2.2: Comprobación de la versión de Python en Ubuntu.
$ python3 --version
Python 3.6.9
$ python3 -m pip --version
pip 9.0.1 from /usr/lib/python3/dist-packages (python 3.6)
1
La comprobación del tipo de los datos se produce durante la ejecución del programa en vez de
durante la compilación del mismo como ocurre con el tipado estático de otros lenguajes.
32.2 Scrapy
Scrapy [dev08] es un framework de scraping y crawling para el lenguaje de programa-
ción Python. Hace uso de rastreadores web que siguen un conjunto de instrucciones
para obtener información de páginas web.
Ha sido desarrollado por las compañías Mydeco e Insophia, dedicadas al e-commerce
y a la consultoría web respectivamente. Actualmente lo mantiene la empresa de
servicios de Web Scraping Scrapinghub.
A parte de la extracción y minería de datos puede utilizarse para otros propósitos
como monitorizar sitios web o realizar pruebas automatizadas. Se puede utilizar
mediante línea de comandos o como una librería más de Python.
Cód. 2.3: Instalación de Scrapy con pip.
python3 -m pip install scrapy
Cód. 2.4: Comandos y uso de Scrapy.
$ scrapy --help
Scrapy 2.5.0 - no active project
Usage:
scrapy [options] [args]
Available commands:
bench Run quick benchmark test
commands
fetch Fetch a URL using the Scrapy downloader
genspider Generate new spider using pre-defined templates
runspider Run a self-contained spider (without creating a project
)
settings Get settings values
shell Interactive scraping console
startproject Create new project
version Print Scrapy version
view Open URL in browser, as seen by Scrapy
[ more ] More commands available when run from project directory
Use "scrapy -h" to see more info about a command
4 Capítulo 2 Fundamentos tecnológicos2.2.1 scrapy-fake-useragent
Scrapy se apoya en el middleware scrapy-fake-useragent [Afa14] para obtener de
forma aleatoria2 distintos User-Agent o generar nuevos User-Agent falsos. Estos
User-Agent permiten realizar consultas a gran velocidad para agilizar el proceso de
análisis web y extracción de datos.
Los User-Agent son cadenas de caracteres que hacen referencia a una versión
concreta de un navegador web (real o no) para hacer creer que una persona real está
usando dicho navegador. A continuación podemos ver ejemplos de algunos de estos
User-Agent:
• Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/91.0.4472.77 Safari/537.36: navegador web Chrome versión 91.0.4472.77
corriendo en un sistema Linux.
• Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:89.0) Gecko/20100101 Firefo-
x/89.0: navegador web Firefox versión 89.0 corriendo en un sistema Linux.
• Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/605.1.15
(KHTML, like Gecko) Version/14.1.1 Safari/605.1.15: navegador web Safari
corriendo en un sistema Macintosh.
Fig. 2.1.: Análisis en detalle de un User-Agent a través de UserAgentString.com.
2
Obtiene User-Agent de forma aleatoria basada en estadísticas de uso reales.
2.2 Scrapy 5Cód. 2.5: Instalación de scrapy-fake-useragent con pip.
python3 -m pip install scrapy-fake-useragent
A la hora de configurar los middlewares hay que tener en cuenta los siguientes
parámetros:
• UserAgentMiddleware: permite a los spiders anular el User-Agent por defecto.
• RetryMiddleware: permite reintentar las peticiones fallidas a causa de proble-
mas temporales como un HTTP 500 Error Interno del Servidor.
Estos middlewares son los propios de Scrapy, que se deshabilitarán para dar prioridad
absoluta a los correspondientes proporcionados por scrapy-fake-useragent (ver Cód.
2.6).
Cód. 2.6: Configuración básica de un User-Agent.
DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
'scrapy.downloadermiddlewares.retry.RetryMiddleware': None,
'scrapy_fake_useragent.middleware.RandomUserAgentMiddleware': 400,
'scrapy_fake_useragent.middleware.RetryUserAgentMiddleware': 401,
}
2.3 Requests
Requests [Rei11] es una librería de Python que proporciona, de forma simplificada, las
funcionalidades necesarias para realizar peticiones HTTP a través de los métodos:
• POST: envía los datos al servidor para que los procese (en el cuerpo de la
petición). Está orientado a crear un nuevo recurso.
• GET: solicita una representación del recurso especificado. No debe causar
modificaciones del recurso.
• PUT: carga en el servidor una representación del recurso. A diferencia de
POST, PUT está orientado a actualizar un recurso ya existente.
• DELETE: elimina el recurso especificado.
Además Requests dispone de importantes características entre las que cabe desta-
car:
• Keep-Alive (mantiene la sesión activa)
6 Capítulo 2 Fundamentos tecnológicos• Pool de conexiones
• Sesiones con cookies permanentes
• Verificación SSL
• Peticiones con autenticación (p.e. solicitar inicio de sesión indicando usuario y
contraseña)
• Descargas en streaming
Cód. 2.7: Instalación de Requests con pip.
python3 -m pip install requests
Cód. 2.8: Uso de Requests con Python.
>>> import requests
>>> url = "https://i.picsum.photos/id/309/200/300.jpg?hmac=gmsts4-400
Ihde9dfkfZtd2pQnbZorV4nBKlLOhbuMs"
>>> r = requests.get(url)
>>> r.status_code
200
>>> r.headers['Content-Type']
'image/jpeg'
2.4 Pillow
Pillow [Cla11] es un fork de la librería PIL (Python Imaging Library) para el
procesamiento de imágenes, incluyendo diversas operaciones, como redimensiona-
do, rotación, transformaciones arbitrarias, conversión del formato, obtención de
estadísticas (histograma), etc.
El proyecto nació en 2009 como “Python Imaging Library” (PIL) de manos de
Fredrik Lundh pero en 2011 fue abandonado y continuado por Alex Clark que creo
el fork que actualmente conocemos como Pillow y convirtiendose en el oficial que
utilizan distribuciones Linux como Debian o Ubuntu desde 2012.
Soporta gran cantidad de formatos de imagen, desde los más habituales como
BMP, GIF, ICO, JPEG, PNG o TIFF, pero además también admite PSD (Adobe
Photoshop), PDF (Acrobat), HDF5 (Hierarchical Data Format) o MPEG (Moving
Picture Experts Group).
Cód. 2.9: Instalación de Pillow con pip.
python3 -m pip install Pillow
2.4 Pillow 7Cód. 2.10: Uso de Pillow con Python (1).
>>> import requests
>>> from PIL import Image
>>> url = "https://i.picsum.photos/id/309/200/300.jpg?hmac=gmsts4-400
Ihde9dfkfZtd2pQnbZorV4nBKlLOhbuMs"
>>> img = Image.open(requests.get(url, stream=True).raw)
>>> w,h = img.size
>>> w,h
(200, 300)
>>> img.show()
Fig. 2.2.: Imagen original cargada con Pillow.
Cód. 2.11: Uso de Pillow con Python (2).
>>> tmp = img.resize((224,224))
>>> img = tmp.rotate(90)
>>> img.show()
Fig. 2.3.: Imagen redimensionada y girada con Pillow.
8 Capítulo 2 Fundamentos tecnológicos2.5 Docker
Docker [Hyk13] es una herramienta de virtualización ligero que permite levantar
máquinas independientes con sistemas operativos ligeros. Utiliza un sistema de
imágenes que crean contenedores para virtualizar el sistema operativo. Estas imá-
genes se pueden almacenar en Docker Hub de manera privada o pública para la
comunidad.
Una imagen es una colección de archivos comprimidos que contienen toda la infor-
mación que se necesita para poder ejecutar un contenedor (librerías, directorios,
ejecutables, etc.).
Por otro lado, un contenedor es una instancia de una imagen. Se pueden crear varios
contenedores independientes a partir de una misma imagen, ya que cada contenedor
está aislado del resto de procesos del sistema y de contenedores.
Fig. 2.4.: Funcionamiento de la herramienta Docker.
Cód. 2.12: Instalación de Docker en Ubuntu.
sudo apt-get update
sudo apt-get install docker-ce docker-ce-cli containerd.io
Cód. 2.13: Comprobación de la versión e información de Docker.
$docker --version
Docker version 20.10.2, build 20.10.2-0ubuntu1~18.04.2
$ docker info
Client:
Context: default
Debug Mode: false
Server:
Containers: 5
Running: 0
Paused: 0
2.5 Docker 9Stopped: 5
Images: 15
Server Version: 20.10.2
...
Otros componentes muy importante en Docker es el Dockerfile. El Dockerfile es un
script que contiene los comandos necesarios para crear una imagen de Docker (ver
Cód. 2.14). Para crear una imagen se utiliza el comando “docker build” (ver Cód.
2.16).
Cód. 2.14: Ejemplo de un fichero Dockerfile.
### 1. Get Linux
FROM alpine:3.7
### 2. Get Python, PIP
RUN apk add --no-cache python3 \
&& python3 -m ensurepip \
&& pip3 install --upgrade pip setuptools \
&& rm -r /usr/lib/python*/ensurepip \
&& if [ ! -e /usr/bin/pip ]; then ln -s pip3 /usr/bin/pip ; fi \
&& if [[ ! -e /usr/bin/python ]]; then ln -sf /usr/bin/python3 /usr/
bin/python; fi \
&& apk add --no-cache python3-dev
### scrapy
RUN apk add --no-cache gcc linux-headers musl-dev libffi-dev libxml2-
dev libxslt-dev openssl-
dev python3-dev
### Pillow
RUN apk add build-base python-dev py-pip jpeg-dev zlib-dev
ENV LIBRARY_PATH=/lib:/usr/lib
### 3. Install requirements
COPY requirements.txt /tmp/requirements.txt
RUN pip3 install --quiet -r /tmp/requirements.txt
### 4. Copy files
RUN mkdir -p /tmp/scraper-test
WORKDIR /tmp/scraper-test
COPY realestate/ /tmp/scraper-test/realestate/
Cód. 2.15: Contenido de requirements.txt.
scrapy>=1.7.4
scrapy-fake-useragent>=1.1.0
requests>=2.22.0
Pillow>=6.2.1
argparse>=1.4.0
10 Capítulo 2 Fundamentos tecnológicosCód. 2.16: Creación de la imagen y ejecución del contenedor con Docker.
docker build --tag=scraper-test .
docker run -it --rm --name=scrapercontainer scraper-test sh
La principal diferencia entre Docker y una máquina virtual es que los contenedores
de Docker son mucho más ligeros y flexibles que las máquinas virtuales. Como se ha
dicho antes, los contenedores de Docker están aislados entre si, pero pueden compartir
librerías y procesos entre ellos modificando el nivel de aislamiento, mientras que las
máquinas virtuales aislan el sistema operativo completo, por lo que dos aplicaciones
en dos máquinas virtuales distintas no podrán compartir librerías ni procesos.
Otra diferencia importante es que mientras que las máquinas virtuales son contro-
ladas por el hipervisor del sistema operativo anfitrión, los contenedores de Docker
son controlados por el Docker Engine (o Docker Daemon) y es independiente del
sistema operativo, por lo que se puede ejecutar cualquier contenedor Docker inde-
pendientemente del sistema operativo anfitrión.
(a) Arquitectura VMs (b) Arquitectura contenedores
Fig. 2.5.: Diferencias entre arquitecturas.
2.6 GitHub
GitHub [Wan+11] es una plataforma de desarrollo colaborativo que se utiliza para
alojar proyectos utilizando el sistema de control de versiones Git. Se ha utilizado
para almacenar y compartir (en privado) el código fuente de la herramienta a
desarrollar.
El control de versiones Git permite administrar los cambios que se realizan en
el código según se va desarrollando el proyecto. Al subir a GitHub una versión
modificada esta no sobreescribe a la anterior, sino que se almacenan como versiones
independientes, pudiendo así volver a versiones anteriores si la nueve tiene fallos o
no funciona como se esperaba.
2.6 GitHub 11Cada proyecto se almacena en lo que se conoce como “repositorio”. Cada repositorio
y su correspondiente URL son únicos.
Durante el desarrollo de un proyecto se pueden crear ramificaciones o “branches”,
que crean una copia de la rama principal del proyecto y así poder hacer pruebas sin
que esto modifique a la rama principal. Si una ramificación en la que se realizan
pruebas tiene un resultado satisfactorio, esta se puede fusionar con la rama principal
creando una nueva versión
Fig. 2.6.: Ejemplo de una rama (branch) en un proyecto de desarrollo.
Una vez se crea el proyecto en GitHub, este se puede descargar en el equipo de
desarrollo mediante el comando “git clone”:
Cód. 2.17: Descarga del repositorio.
git clone https://github.com/usuario/nombreproyecto.git
Cada vez que se realizan cambios y se quieren guardar en el repositorio, se añaden
los archivos correspondientes con el comando “git add”, se crea una instantánea de
los cambios con el comando “git commit” y se envían al repositorio remoto con el
comando “git push”:
Cód. 2.18: Commit de los cambios en el repositorio.
git add
git commit [-m ]
git push origin
Para crear una ramificación (branch) se utiliza el comando “git checkout”, por
ejemplo, si se quiere crear una rama “develop” a partir de la rama “master”:
Cód. 2.19: Creación de la rama “develop”.
git checkout -b develop master
Tras realizar cambios satisfactorios en la rama “develop” y realizar el “commit” en
dicha rama, se cambia a la rama principal (master) con el comando “git checkout” y
12 Capítulo 2 Fundamentos tecnológicosse fusionan los cambios con el comando “git merge”3 . A mayores se puede usar el
comando “git tag” para añadir una etiqueta de la versión.
Cód. 2.20: Fusión de ramas y etiquetado de versión.
# Estando en la rama 'develop':
git add
git commit [-m ]
git checkout master
git merge --no-ff develop
git tag -a v1.0.0 -m "Nueva versión v1.0.0"
git push origin master
git push origin master --tags
2.7 Microsoft Teams
Microsoft Teams [Mic17] es una plataforma de comunicación y colaboración en el
entorno laboral que combina chat, videollamada grupal, almacenamiento de archivos
en la nube (OneDrive) e integración de aplicaciones (MS Office, GitHub, Trello,
etc.). Se ha utilizado esta herramienta para las sesiones de control semanales.
Fig. 2.7.: Plataforma de comunicación Microsoft Teams.
3
Se puede añadir la opción “--no-ff” para evitar que se ejecute un “fast-forward” y asegurarse de
que se registran todos los cambios.
2.7 Microsoft Teams 13Entre las características que ofrece Microsoft Teams se han utilizado frecuentemente
las funciones de chat entre el alumno y los tutores, las llamadas tanto de voz como
videollamadas y el uso compartido de pantalla para poder mostrar en tiempo real la
situación del proyecto y los avances en las tareas semanales.
Se han programado en el calendario integrado de Teams las reuniones semanales y
este calendario también ha ayudado a establecer otras reuniones puntuales gracias a
la facilidad de creación e interacción con la aplicación para concretar el momento de
disponibilidad de alumno y tutores.
Otra característica que se ha utilizado bastante es la compartición segura de archivos,
que se ha utilizado en combinación con el uso compartido de pantalla para realizar
explicaciones y consultas. Además, como Microsoft Teams proporciona integración
con Office 365, se ha podido potenciar la compartición de archivos en formato CSV
a través de la herramienta Microsoft Excel online.
En cuanto a la asignación de tareas, aunque Microsoft Teams dispone de un apartado
dedicado para ello, se ha preferido utilizar la herramienta Trello, la cual se puede
integrar con Microsoft Teams.
2.8 Trello
Trello [Spo11] es un software de administración y organización de proyectos que utiliza
tarjetas virtuales para organizar tareas y eventos. Se ha utilizado esta herramienta
para la asignación de tareas, que se han ido actualizando en cada sesión de control
semanal.
El elemento principal de Trello se denomina “tablero”, el cual se divide en “columnas”
que a su vez contienen “tarjetas” con las tareas a realizar. Las tarjetas pueden pasar
de una columna a otra simplemente arrastrándolas con el ratón (o el dedo en la
versión móvil).
A cada tarjeta se le pueden asignar miembros, que serán los responsables de realizar
la tarea o supervisarla, etiquetas personalizables identificadas por colores para indicar
por ejemplo una temática o su grado de importancia, “checklists” con subtareas
o pasos para realizar la tarea principal, fecha límite de finalización y adjuntar
archivos.
14 Capítulo 2 Fundamentos tecnológicosFig. 2.8.: Tablero de tareas de Trello con dos columnas.
A la hora de organizar el tablero, una configuración recomendable es dividirlo en las
siguientes columnas:
• INFO: columna que contendrá tarjetas puramente informativas (no son tareas
a realizar), por ejemplo, con la normativa del TFM, el calendario oficial del
máster y otros documentos importantes para tener a mano. Esta columna es
opcional.
• TO DO: contiene las tarjetas con las tareas pendientes a realizar por el alumno.
En cada sesión de control semanal se añadirán nuevas tarjetas.
• IN PROGRESS: en esta columna se encuentran las tarjetas con las tareas que
está llevando a cabo el alumno en ese momento.
• READY TO VERIFY: aquí se pondrán las tarjetas cuyas tareas ha terminado
de hacer el alumno pero que aún tienen que ser revisadas por los tutores.
• DONE: en esta columna se encuentran las tarjetas con las tareas que han
finalizado y han sido revisadas y aprobadas por los tutores.
2.8 Trello 15Situación actual 3
En este capítulo se realiza una revisión de los conceptos tratados en este trabajo,
así como de aquellos trabajos o tecnologías que, por tener finalidades similares a las
de este, pudiesen servir como base de discusión para el desarrollo de una solución al
problema a resolver.
3.1 Marco teórico
En esta sección se explican los conceptos teóricos sobre el Web Scraping, tratando
todos aquellos elementos que lo conforman o que están relacionados en mayor o
menor medida.
3.1.1 Web Crawlers (Rastreadores Web)
Los Web Crawlers o rastreadores web son herramientas informáticas que recopilan
toda la información que contiene una página web de manera automática. Estos
rastreadores web son uno de los componentes principales de los motores de búsqueda
web, realizando las tareas de recopilación de datos para crear índices y así poder
permitir a los usuarios realizar consultas para buscar información o páginas web.
[ON10]
Otro uso habitual es en el “Archivo de Internet” (Internet Archive) [Kah96], la
biblioteca digital sin ánimo de lucro que recopila páginas web de manera periódica
para la posteridad bajo licencias que permiten su distribución gratuita.
También se utilizan para realizar minería de datos, con la finalidad de analizar
páginas web con fines estadísticos, estudios de mercado o para detectar anomalías
o infracciones. Un ejemplo muy conocido es “Attributor”, una empresa encargada
de buscar infracciones de derechos de autor y marcas registradas (actualmente
propiedad de Digimarc Corporation).
173.1.2 Web Scraping
El Web Scraping (o raspado web) es una técnica que hace uso de Web Crawlers
para extraer información de páginas web. Esta técnica simula la navegación de un
usuario en Internet haciendo uso de los protocolos HTTP o de un navegador web
automatizado.
Tras obtener los datos de las páginas web en formato HTML, el Web Scraping los
transforma de forma estructurada para ser almacenados y analizados posteriormente.
Esta técnica se utiliza habitualmente para la comparación de precios de un producto
o servicio en diversas tiendas online, detectar cambios en sitios webs o monitorizar
datos para diversos propósitos, como por ejemplo, para mejorar el posicionamiento
de un sitio web en la lista de resultados de buscadores de internet.
El Web Scraping puede realizarse de diversas maneras, a continuación se detallan
algunas de ellas:
• Protocolo HTTP: se pueden obtener páginas webs estáticas y dinámicas
completas realizando peticiones HTTP con el método GET (solo para obtener
datos).
• Parsers de HTML: se pueden utilizar languajes de consulta específicos para
colecciones de datos como XQuery y con ello parsear documentos para obtener
y transformar el contenido de documentos HTML de forma estructurada.
• Uso de expresiones regulares: aunque no es el mejor método para parsear un
documento HTML, puede utilizarse de forma complementaria.
• Algoritmos de minería de datos: cuando las páginas web se generan dinámi-
camente, es más difícil obtener los datos, por lo tanto hay que hacer uso de
técnicas o herramientas más potentes para extraer el contenido.
• Aplicaciones para Web Scraping: dedicadas específicamente para este cometido.
Es habitual que estas aplicaciones muestren la página web objetivo para
seleccionar los campos de forma interactiva y así ser más fácil de utilizar para
el usuario, evitando hacer uso de código de programación.
3.1.3 Defensa y prevención contra el Web Scraping
Existen diversas técnicas para que un sitio web pueda evitar que realicen Web
Scraping sobre él entre las que cabe destacar:
18 Capítulo 3 Situación actual• Uso del “protocolo de la exclusión de robots” (robots.txt): es el método más
sencillo para protegerse de bots que realizan Web Scraping u otro tipo de
análisis web. Se trata de un fichero ‘robots.txt’ que contiene un conjunto de
reglas para bloquear a los bots. En el fragmento de código Cód. 3.1 podemos
ver en la primera regla definida a un User-Agent ‘AdsBot-Google’ que no
puede rastrear el directorio ‘noadsgooglebot’ del sitio web ni ninguno de los
subdirectorios contenidos en él. Como segunda regla está definido que el resto
de User-Agents (*) pueden acceder a todos los directorios del sitio web (/).
Cód. 3.1: Ejemplo de un fichero ‘robots.txt’ con dos reglas definidas.
# Group 1
User-agent: AdsBot-Google
Disallow: /noadsgooglebot/
# Group 2
User-agent: *
Allow: /
• Uso de cookies: con esto se comprueba que la petición se realiza en un navegador
web.
• Uso de CAPTCHA: ayudan a verificar que el usuario no es un bot. Existen
distintos tipos, desde los más sencillos basados en introducir texto o en selec-
cionar imágenes, a otros más sofisticados basados en el comportamiento del
usuario (p.e. movimiento del ratón). Entre los más habituales cabe destacar:
– CAPTCHAs textuales y/o auditivos: se muestra la imagen de un texto
con caracteres alfanuméricos que el usuario tiene que introducir para
poder continuar. El texto puede ser reproducido en audio si el usuario
tiene dificultades para interpretarlo. A parte de texto simple, se le puede
pedir al usuario que resuelva una sencilla operación matemática. En el
sistema reCAPTCHA equivalen a la versión 1 (v1).
Fig. 3.1.: CAPTCHA textual (reCAPTCHA v1).
3.1 Marco teórico 19– CAPTCHAs visuales: muestra diversas imágenes y le solicita al usuario
que haga click aquellas en las que se encuentre algo determinado (p.e.
bicicletas, semáforos, paso de peatones, etc.). En el sistema reCAPTCHA
equivalen a la versión 2 (v2).
Fig. 3.2.: CAPTCHA visual (reCAPTCHA v2).
– CAPTCHAs “no soy un robot”: también conocido como “no CAPTCHA”,
es tan sencillo como hacer click en una casilla que dice “no soy un robot”,
ya que la probabilidad de que un humano haga click en el centro de la
casilla es muy baja, mientras que un bot hará siempre click en el centro.
En el sistema reCAPTCHA equivalen a la versión 2+ (v2+).
Fig. 3.3.: CAPTCHA “no soy un robot” (reCAPTCHA v2+).
20 Capítulo 3 Situación actual– CAPTCHAs invisible: es el primer CAPTCHA con el que el usuario no
tiene que interactuar explícitamente, ya que este CAPTCHA está oculto
y se basa en el comportamiento del usuario. En el sistema reCAPTCHA
equivalen a la versión 3 (v3).
Fig. 3.4.: CAPTCHA invisible (reCAPTCHA v3).
• Uso de JavaScript: los scrapers más sencillos no son capaces de procesar código
JavaScript, por lo tanto la presentación de los datos de la página web puede
ser generado por código JavaScript. Este método sin embargo cada vez es
menos efectivo.
• Limitar el número de peticiones: ya que una máquina es capaz de realizar un
gran número de peticiones en pocos segundos y un humano no, es una buena
estrategia limitar el número de peticiones por segundo.
• Bloquear direcciones IP: si se detectan muchas peticiones seguidas desde la
misma dirección IP, se puede añadir a una lista negra para evitar que realice
más peticiones.
3.1.4 Legalidad del Web Scraping
En España el Web Scraping es legal siempre que:
• No se incurra en un delito contra la propiedad intelectual o competencia
desleal.
• Se practique dentro del marco de la Ley Orgánica de Protección de Datos y
Garantía de Derechos Digitales (LOPDGDD) [Tab19]:
– Los datos son de fuentes de acceso público.
– Los datos se obtienen con fines de interés público general.
3.1 Marco teórico 21– Prevalece el interés del responsable del tratamiento sobre el derecho a la
protección de datos.
– En caso de recabar datos sobre una persona, esta da su consentimiento.
• No se produzca una violación de seguridad de un sitio web y no se dañe el
servidor del sitio web por cualquier medio, influyendo en su rendimiento y/o
funcionamiento.
En el Espacio Económico Europeo (EEE) no hay ninguna ley que estipule si el Web
Scraping es legal o ilegal. Sin embargo, ha habido sentencias judiciales de pleitos
entre los propietarios de sitios web y los responsables de realizar Web Scraping sobre
dicho sitio web en los que se hace referencia al Reglamento General de Protección
de Datos (RGPD).
El Reglamento General de Protección de Datos (RGPD) establece normas para la
protección de la información personal que coinciden con las anteriormente citadas
para España, ya que la Ley Orgánica de Protección de Datos y Garantía de Derechos
Digitales (LOPDGDD) adapta el Derecho interno español al Reglamento General de
Protección de Datos (RGPD). También establece que cualquier empresa, sin importar
si están físicamente presentes en la Unión Europea, está sujeta al Reglamento General
de Protección de Datos (RGPD) si los datos obtenidos son sobre sujetos europeos.
Por último, hay que tener en cuenta los Términos y Condiciones del sitio web, en
los que el titular puede incluir la prohibición expresa de realizar Web Scraping.
3.1.5 Consecuencias legales del Web Scraping
Como se ha comentado anteriormente, no hay ninguna ley que regule directamente
el Web Scraping, sin embargo si la acción de realizarlo incurre en otros delitos se
aplicarán sus correspondientes sanciones.
A continuación se repasan los artículos del Código Penal español que tratan estos
delitos relacionados con el mal uso del Web Scraping.
Si se produce un delito de suplantación de identidad sobre una persona física, el
Artículo 197 del Código Penal español [BOE95a] dice:
22 Capítulo 3 Situación actual1. El que, para descubrir los secretos o vulnerar la intimidad de otro, sin su
consentimiento, se apodere de sus papeles, cartas, mensajes de correo elec-
trónico o cualesquiera otros documentos o efectos personales, intercepte sus
telecomunicaciones o utilice artificios técnicos de escucha, transmisión, graba-
ción o reproducción del sonido o de la imagen, o de cualquier otra señal de
comunicación, será castigado con las penas de prisión de uno a cuatro años y
multa de doce a veinticuatro meses.
2. Las mismas penas se impondrán al que, sin estar autorizado, se apodere, utilice
o modifique, en perjuicio de tercero, datos reservados de carácter personal o
familiar de otro que se hallen registrados en ficheros o soportes informáticos,
electrónicos o telemáticos, o en cualquier otro tipo de archivo o registro público
o privado. Iguales penas se impondrán a quien, sin estar autorizado, acceda
por cualquier medio a los mismos y a quien los altere o utilice en perjuicio del
titular de los datos o de un tercero.
3. Se impondrá la pena de prisión de dos a cinco años si se difunden, revelan o
ceden a terceros los datos o hechos descubiertos o las imágenes captadas a que
se refieren los números anteriores.
De cometerse delitos contra la propiedad intelectual, el Artículo 270.1 del Código
Penal español [BOE95b] dice: “Será castigado con la pena de prisión de seis meses
a cuatro años y multa de doce a veinticuatro meses el que, con ánimo de obtener
un beneficio económico directo o indirecto y en perjuicio de tercero, reproduzca,
plagie, distribuya, comunique públicamente o de cualquier otro modo explote econó-
micamente, en todo o en parte, una obra o prestación literaria, artística o científica,
o su transformación, interpretación o ejecución artística fijada en cualquier tipo
de soporte o comunicada a través de cualquier medio, sin la autorización de los ti-
tulares de los correspondientes derechos de propiedad intelectual o de sus cesionarios”.
En el caso de producirse un delito de daños contra la propiedad (p.e. denegación de
servicio a un sitio web), el Artículo 264 bis del Código Penal español [BOE95c] dice:
“Será castigado con la pena de prisión de seis meses a tres años el que, sin estar
autorizado y de manera grave, obstaculizara o interrumpiera el funcionamiento de
un sistema informático ajeno”.
En cuanto a los delitos relativos al mercado y a los consumidores, si se producen
delitos de espionaje empresarial, el Artículo 278.1 del Código Penal español [BOE95d]
3.1 Marco teórico 23dice: “El que, para descubrir un secreto de empresa se apoderare por cualquier
medio de datos, documentos escritos o electrónicos, soportes informáticos u otros
objetos que se refieran al mismo, o empleare alguno de los medios o instrumentos
señalados en el apartado 1 del artículo 1971 , será castigado con la pena de prisión
de dos a cuatro años y multa de doce a veinticuatro meses”.
3.1.6 Data Mining (Minería de Datos)
La minería de datos surgió de la necesidad de manejar y comprender una gran
cantidad de datos para poder utilizarlos con la finalidad de mejorar y hacer crecer
a las empresas para alcanzar sus objetivos y proporcionar mejores servicios a sus
clientes.
Utiliza distintas técnicas y herramientas para explotar grandes bases de datos de
manera automática, en busca de patrones o reglas que de alguna forma expliquen el
comportamiento de los datos recopilados a través del tiempo. Es habitual es uso de
la Inteligencia Artificial y redes neuronales que ayudan a que las tareas de búsqueda
sean más eficientes, eficaces y rápidas.
En la minería de datos no basta con recopilar miles de datos, es necesario saber
transformar estos datos y convertirlos en información que pueda ser relevante para
la empresa y le ayuden a obtener soluciones. Para ello, la minería de datos debe
seguir los siguientes pasos:
1. Establecer objetivos claros: el cliente establece los objetivos que desea alcanzar.
2. Procesar eficazmente los datos: seleccionar, obtener, estructurar, limpiar y
transformar los datos obtenidos.
3. Determinar el modelo: tras realizar un análisis estadístico de los datos, decidir
cual es el modelo a aplicar en función de dichos datos.
4. Analizar los resultados: verificar la validez y coherencia de los resultados y la
información obtenida.
1
“[...] artificios técnicos de escucha, transmisión, grabación o reproducción del sonido o de la imagen,
o de cualquier otra señal de comunicación”
24 Capítulo 3 Situación actual3.2 Tecnologías base
En esta sección se tratan tecnologías que están relacionadas con el Web Scraping o
que tienen un comportamiento similar en cuanto a protocolos o finalidad, que es la
de obtener información.
3.2.1 Herramientas de línea de comandos: Wget y cURL
Wget [Cow96] es una herramienta de software libre que permite la descarga de
contenidos a través de los protocolos HTTP, HTTPS y FTP.
cURL [Ste98] es una herramienta de código abierto que se utiliza por línea de
comandos o scripts para la transferencia de datos. Soporta diversos protocolos (FTP,
HTTP, HTTPS, IMAP, POP3, SMTP, etc.) y certificados SSL. Esta herramienta
es mucho más completa que Wget, ya que soporta más protocolos y puede realizar
transferencia de datos de forma bidireccional, no solo para descarga.
Tanto Wget como cURL por si solas son ineficaces para el Web Scraping, ya que no
son Web Crawlers como tal, por lo que serán detectadas y dejarán de funcionar si
se utilizan de forma repetida.
3.2.2 Librerías para Python: Requests, Scrapy, Selenium y
Beautiful Soup
Requests [Rei11] y Scrapy [dev08] son dos librerías de Python que permiten realizar
peticiones HTTP para obtener datos de páginas web (ver apartados 2.2 y 2.3). Al
igual que Wget y cURL, Request utilizada por si sola será ineficaz para el Web
Scraping.
Selenium [Hug04] destaca por disponer de un entorno de desarrollo integrado (IDE)
que permite ejecutar pruebas automatizadas en un navegador web. También dispone
de un WebDriver que puede ser utilizado con diversos lenguajes de programación
(entre ellos Python) para simular el comportamiento de un usuario en un navegador
web y con ello realizar Web Scraping en páginas web dinámicas gracias a las múltiples
opciones de interacción con la página a analizar.
Beautiful Soup [Ric04] es un parser de documentos HTML. Analiza este tipo de
documentos y genera un árbol con todos los elementos que contiene para de esta
forma extraer datos de páginas web.
3.2 Tecnologías base 25Estas herramientas disponen de equivalentes o similares en otros lenguajes de
programación. Por ejemplo en el caso del WebDriver de Selenium tambien es
compatible con Java, Perl o Ruby entre otros. O en el caso de Beautiful Soup existe
su equivalente en Java, JSoup.
3.3 Trabajos relacionados
En esta sección se analizan los productos o tecnologías existentes en el mercado cuya
función es la misma (o similar) que la que se pretende desarrollar, el Web Scraping
a sitios web.
3.3.1 ParseHub
ParseHub [FPT15] es una herramienta de Web Scraping creada en Canadá en el
año 2015. Es una herramienta freemium2 que permite analizar hasta 200 páginas
por ejecución y almacena los datos obtenidos durante un máximo de 14 días. Este
servicio se puede mejorar con planes de pago (ver Fig. 3.5).
Fig. 3.5.: Planes de pago de ParseHub.
El uso de esta herramienta está enfocado al análisis industrial y marketing, extrayendo
datos de todo tipo de páginas web para obtener información de productos, noticias o
perfiles de redes sociales y con ello mejorar la competencia comercial de la empresa.
2
Modelo de negocio que ofrece los servicios básicos de forma gratuita y permite acceder a otros
servicios de pago que proporcionan más funcionalidades.
26 Capítulo 3 Situación actualDispone de una aplicación de escritorio de fácil uso en la que solo es necesario
añadir los enlaces de las páginas web a analizar o realizar las búsquedas en la propia
aplicación, y además ofrece una API REST que permite a desarrolladores crear
aplicaciones web propias.
Fig. 3.6.: Uso de ParseHub sobre un comercio electrónico.
3.3.2 Webhose.io
Webhose [MG16] es una herramienta de Web Scraping creada en Israel en el año
2016. Se caracteriza por monitorizar tanto las páginas de uso cotidiano como las de
la Deep Web y Dark Web a través de sus correspondientes planes de pago (ver Fig.
3.7).
Fig. 3.7.: Planes de pago de Webhose.
3.3 Trabajos relacionados 27Dispone de APIs individuales según el tipo de páginas que se quieran analizar:
noticias, blogs, redes sociales, Dark Web o detección de brechas de seguridad. De esta
forma abarca distintos sectores de la industria de la información: análisis financiero,
ciberseguridad, investigación de mercado, machine learning y monitorización de
medios.
3.3.3 Octoparse
Octoparse [HL16] es una herramienta de Web Scraping creada en San Francisco
(EE.UU.) en 2016. Al igual que ParseHub es una herramienta freemium limitada a
10.000 registros por exportación y hasta un máximo de 10 Crawlers. El API solo es
accesible a través de los planes de pago, los cuales se detallan a continuación:
• Plan Estándar:
– Precio: 89 dólares/mes.
– Exportaciones ilimitadas.
– 100 Crawlers.
– 6 extracciones simultáneas en la Nube.
– Extracción de velocidad media.
– Rotación automática de IP.
– Acceso al API.
• Plan Profesional:
– Precio: 249 dólares/mes.
– Exportaciones ilimitadas.
– 250 Crawlers.
– 20 extracciones simultáneas en la Nube.
– Extracción de alta velocidad.
– Rotación automática de IP.
– Acceso avanzado al API.
– Prioridad en el soporte técnico.
28 Capítulo 3 Situación actualTambién puede leer

















































