Informe de tendencias tecnológicas en el ámbito del proyecto 31/12/2017
←
→
Transcripción del contenido de la página
Si su navegador no muestra la página correctamente, lea el contenido de la página a continuación
Entregable E2.2
Informe de tendencias tecnológicas
en el ámbito del proyecto
HELPSALUD: Investigación en técnicas de Machine
Learning aplicadas a problemáticas reales del sector Salud
31/12/2017
PROYECTO COFINANCIADO POR: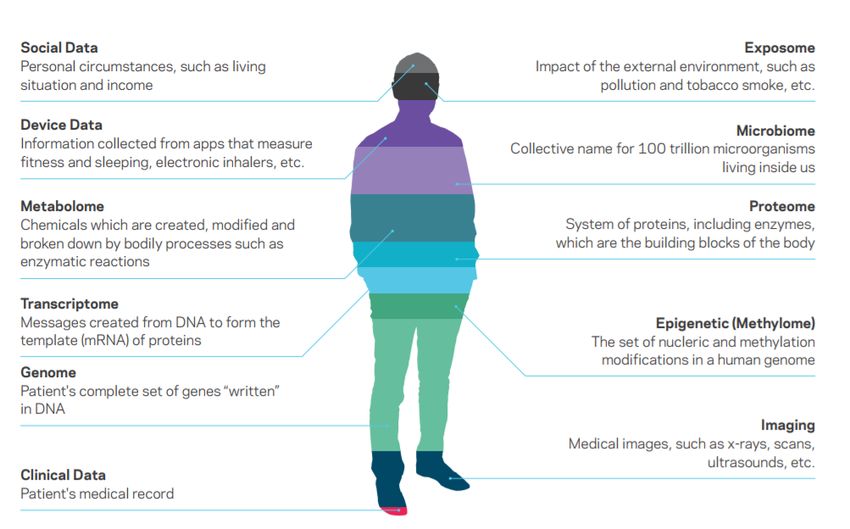
Información del documento
Título: Informe de tendencias tecnológicas en
el ámbito del proyecto
Title: Report of technological trends in the context
of the project
Cod. documento: Entregable E2.2
Proyecto: “HELPSALUD: Investigación en técnicas
de Machine Learning aplicadas a
problemáticas reales del sector Salud”
Fecha publicación: 31/12/2017
Palabras clave: Machine Learning, Aprendizaje
Automático, Inteligencia Artificial,
Diagnóstico temprano, Medicina
personalizada, Clasificador automático,
Aprendizaje Profundo, Redes
Neuronales, Análisis Predictivo
ITI - Instituto Tecnológico de Informática
Camino de Vera, s/n. Edif. 8G. Acc. B – 4ª planta
46022 Valencia - España / Spain
www.iti.es
Personas de Javier Cano Pérez, Principal Engineer
contacto: Depto. PRAIA
TLF: +34 963 877 069; Email: jcano@iti.es
Agradecimientos: Las actividades descritas en este documento se encuadran en el proyecto “HELPSALUD: Investigación
en técnicas de Machine Learning aplicadas al sector salud”, que está cofinanciado por el Instituto Valenciano de
Competitividad Empresarial (IVACE) y por la Unión Europea a través del Fondo Europeo de Desarrollo Regional (FEDER), a
través de la convocatoria de ayudas dirigidas a centros tecnológicos de la Comunidad Valenciana para proyectos de I+D
en cooperación con empresas 2017, con nº expediente IMDEEA/2017/97
Nota legal
Este documento está bajo una Licencia Creative Commons Atribución-NoComercial-
SinDerivar 4.0 Internacional. Se permite libremente copiar, distribuir y comunicar
públicamente esta obra siempre y cuando se reconozca la autoría y no se use para fines
comerciales. No se puede alterar, transformar o generar una obra derivada a partir de esta obra. Los
derechos de autor de todas las marcas, nombres comerciales, marcas registradas, logos e imágenes
pertenecen a sus respectivos propietarios.
E.2.2 Informe de tendencias tecnológicas en el ámbito del proyecto 1
Resumen Abstract
HELPSALUD (Investigación en técnicas de HELPSALUD (Research in Machine Learning
Machine Learning aplicadas a problemáticas techniques applied to real problems in the
reales del sector Salud) es un proyecto Health sector) is a project funded by the
financiado por el Instituto Valenciano de Valencian Institute for Business
Competitividad Empresarial (IVACE) y la Unión Competitiveness (IVACE) and the European
Europea a través del Fondo Europeo de Union through the European Regional
Desarrollo Regional (FEDER). Development Fund (FEDER).
El objetivo general del proyecto es avanzar en The general objective of the project is to
la digitalización del sector sanitario a través de advance in the digitization of the health sector
la aplicación de técnicas de Inteligencia through the application of Artificial
Artificial, como el aprendizaje automático y el Intelligence techniques, such as Machine
reconocimiento de patrones e imágenes, al Learning and Pattern Recognition, to the early
diagnóstico precoz del cáncer de mama, la diagnosis of breast cancer, the non-invasive
detección no invasiva de endometriosis y la detection of endometriosis and the prediction
predicción de los efectos del tratamiento de la of the effects of leukaemia treatment for
leucemia para un tratamiento personalizado. personalized treatment. With the application
Con la aplicación de estas técnicas y de la of these techniques and the combination of
combinación diferentes fuentes de different sources of information, software
información se desarrollarán una serie de solutions will be developed to help the clinical
soluciones software que ayuden al personal staff in the decision-making process, allowing
clínico en el proceso de toma de decisiones, cost savings and improvement of the health
permitiendo el ahorro de costes y la mejora del service.
servicio de salud.
This document is a report of technological
El presente documento es un informe de trends in the context of the project, within the
tendencias tecnológicas en el ámbito del scope of the transfer and promotion of the
proyecto, enmarcado dentro del ámbito de la results of the project. The report includes the
transferencia y promoción de los resultados analysis of the follow-up of new technological
del proyecto. El informe recoge el análisis del developments related to the project to allow
seguimiento realizado de las novedades the research team involved to be aware of the
tecnológicas relacionadas con el contexto del latest developments that may affect the
proyecto para permitir al equipo de results of the project.
investigación involucrado estar al corriente de
los últimos avances que pueden afectar a los
resultados del mismo.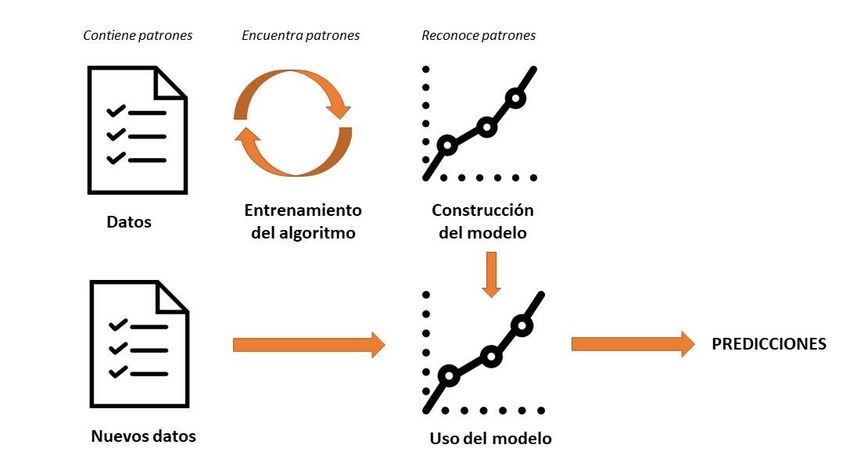
E.2.2 Informe de tendencias tecnológicas en el ámbito del proyecto 2
Contenido
Resumen .......................................................................................................................... 1
Abstract ........................................................................................................................... 1
1 Introducción .............................................................................................................. 4
1.1 Breve introducción a “Machine Learning”................................................................... 4
1.2 Grado de adopción y sectores de aplicación ............................................................... 8
2 “Machine Learning” en el sector Salud ......................................................................15
2.1 Contexto y oportunidades ......................................................................................... 15
2.2 Retos de investigación y desarrollo tecnológico ....................................................... 17
2.3 Revisión sistemática de tendencias tecnológicas ...................................................... 20
3 Conclusiones ............................................................................................................28
4 Referencias ..............................................................................................................29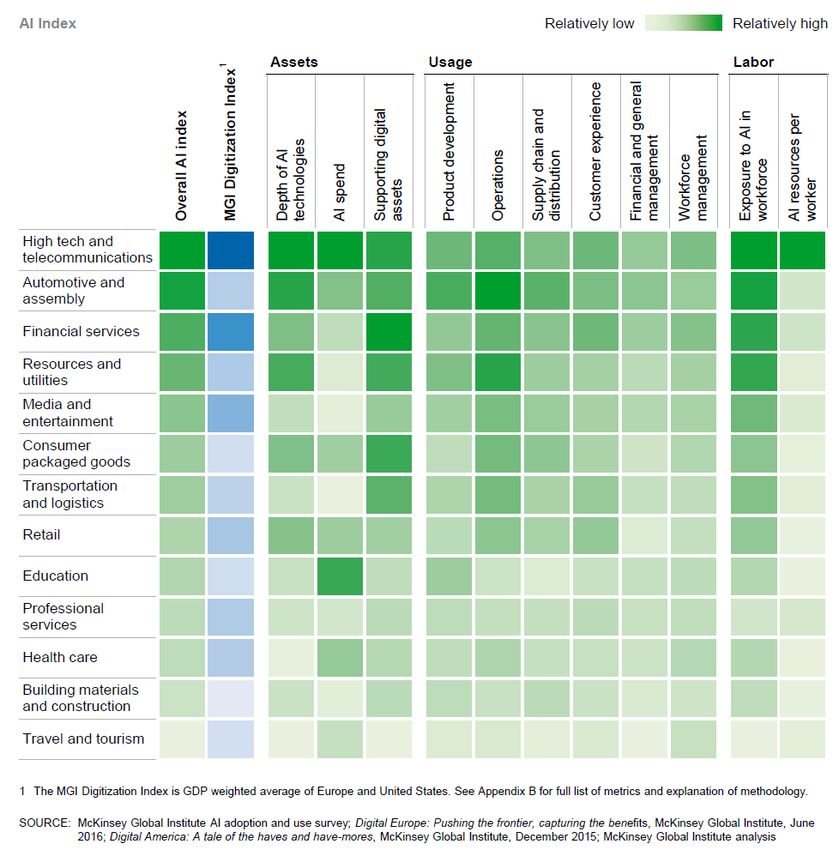
E.2.2 Informe de tendencias tecnológicas en el ámbito del proyecto 3 Índice de figuras Figura 1. Top 10 Tendencias Tecnológicas Estratégicas para 2018 (Fuente: Gartner) ...................................... 4 Figura 2. Evolución temporal del Aprendizaje Automático (Fuente: Orion Health)........................................... 4 Figura 3. Funcionamiento básico del Aprendizaje Automático (Fuente: Basado en DZone.com) ..................... 5 Figura 4. Aprendizaje Automático supervisado y no supervisado (Fuente: DZone.com) ................................... 5 Figura 5. Arquitecturas de Redes de Neuronas para Aprendizaje Profundo (Fuente: DZone.com) ................... 7 Figura 6. Adopción de IA por sectores versus nivel de digitalización (Fuente: McKinsey Global Institute) ....... 9 Figura 7. Grado de adopción de IA por sectores y en la cadena de valor (Fuente: McKinsey Global Institute) . 9 Figura 8. Áreas de la organización donde ya se están obteniendo beneficios por la IA (Fuente: Teradata) ... 10 Figura 9. Áreas de la organización donde ya se están obteniendo beneficios por la IA por región (Fuente: Teradata) ......................................................................................................................................................... 10 Figura 10. Barreras a la adopción de la IA en las empresas (Fuente: Teradata) ............................................. 14 Figura 11. Datos útiles para la Medicina Personalizada (Fuente: Orion Health) ............................................ 15 Índice de tablas Tabla 1. Escenarios de aportación de valor de la IA en los principales sectores de aplicación (Fuente: McKinsey Global Institute) ............................................................................................................................... 11 Tabla 2. Ejemplos de impactos en el negocio relacionados con la IA de casos de uso actuales (Fuente: McKinsey Global Institute) ............................................................................................................................... 13
E.2.2 Informe de tendencias tecnológicas en el ámbito del proyecto 4
1 Introducción
1.1 Breve introducción a “Machine Learning”
Machine Learning (ML) o Aprendizaje Automático es la fuerza conductora de la corriente de la
Inteligencia Artificial (IA), una de las tendencias tecnológicas estratégicas del 2018 que va a marcar
los próximos cinco años, según la consultora Gartner. Así, crear sistemas capaces de aprender
adaptarse y actuar de forma autónoma será el principal campo de batalla de los proveedores de
tecnología hasta al menos 2020. La utilización de Inteligencia Artificial para mejorar la toma de
decisiones, reinventar los modelos y ecosistemas de negocio, y rehacer la experiencia del cliente,
impulsará la rentabilidad de las iniciativas digitales hasta 20251.
Figura 1. Top 10 Tendencias Tecnológicas Estratégicas para 2018 (Fuente: Gartner)
Según los expertos, ya en los años 50 se dieron los primeros atisbos de optimismo en cuanto a las
posibilidades que ofrecía la inteligencia artificial y, desde entonces, se han ido generando
“subconjuntos” que han ido creando incluso disrupciones más importantes. Primero fue el
Aprendizaje Automático a partir de los años 80 y, después, el Aprendizaje Profundo, que es el eje
impulsor de la explosión de la Inteligencia Artificial, principalmente a partir de 2015.
Figura 2. Evolución temporal del Aprendizaje Automático (Fuente: Orion Health)
1 “Gartner Identifies the Top 10 Strategic Technology Trends for 2018”. Octubre 2017
https://www.gartner.com/newsroom/id/3812063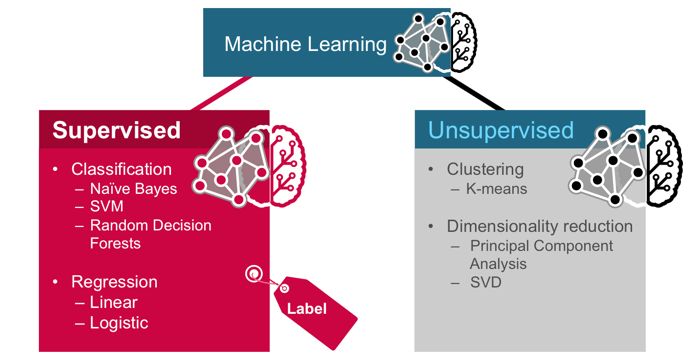
E.2.2 Informe de tendencias tecnológicas en el ámbito del proyecto 5
De forma muy básica podemos decir que Machine Learning consiste en la utilización de algoritmos
para encontrar patrones en unos datos de entrada y después usar el modelo que reconoce dichos
patrones para hacer predicciones sobre nuevos datos, tal y como muestra la siguiente figura2.
Figura 3. Funcionamiento básico del Aprendizaje Automático (Fuente: Basado en DZone.com)
En general, se suele clasificar en dos tipos: supervisado y no supervisado. En el aprendizaje
automático supervisado, los algoritmos utilizan datos etiquetados por expertos, mientras que, en
el no supervisado, los algoritmos encuentran patrones sobre datos no etiquetados. Existe una
modalidad en medio que se conoce como semi-supervisado, donde se mezclan datos etiquetados
y no etiquetados.
El aprendizaje automático supervisado también se conoce como modelado predictivo o análisis
predictivo, puesto que se construye un modelo capaz de hacer predicciones. Algunos ejemplos de
este tipo son los modelos de clasificación, en los que se identifica la categoría a la que pertenece
un elemento basándose en ejemplos etiquetados de elementos conocidos; y regresión, donde se
predice una probabilidad.
El aprendizaje automático no supervisado se conoce a veces como análisis descriptivo, y permite
descubrir similitudes o regularidades en los datos de entrada.
Figura 4. Aprendizaje Automático supervisado y no supervisado (Fuente: DZone.com)
2“Demystifying AI, Machine Learning, and Deep Learning”. Agosto 2017 https://dzone.com/articles/demystifying-ai-
machine-learning-and-deep-learning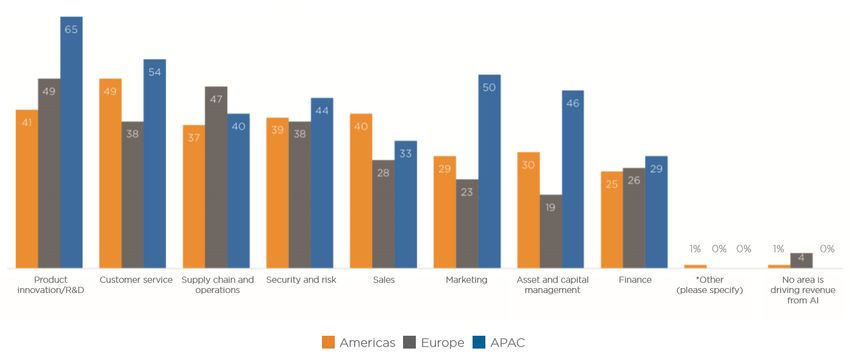
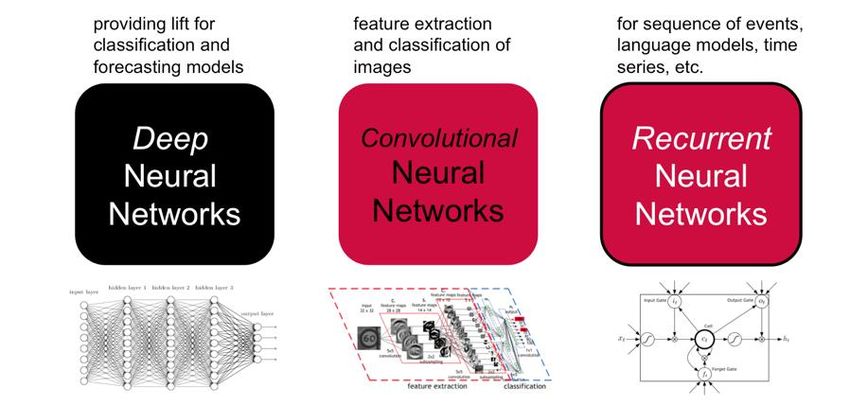
E.2.2 Informe de tendencias tecnológicas en el ámbito del proyecto 6 En definitiva, Machine Learning permite desarrollar técnicas para que las máquinas puedan aprender y tomar decisiones por sí mismas, para lo cual se detectan patrones dentro de un conjunto de datos y el propio programa predice qué situaciones podrían darse o no. Estos cálculos le permiten aprender para, finalmente, generar decisiones y resultados fiables3. Esta nueva metodología permite crear software que resuelve problemas no superados con los métodos tradicionales y además con precisión casi humana. En concreto, problemas de detección y reconocimiento de objetos, reconocimiento de voz y traducción de lenguaje. De esta forma, Machine Learning está proporcionando una tecnología clave para posibilitar aplicaciones como conducción automática, ayuda a la conducción en tiempo real, interfaces de usuario en diferentes lenguajes e interfaces de usuario dirigidas por voz. También es útil para motores de búsqueda web, sistemas de recomendación y publicidad personalizada. Algunos expertos predicen que el Machine Learning revolucionará la medicina, en especial en lo que refiere a la recogida y análisis automático de imágenes médicas como ayuda al diagnóstico clínico. También se ve como una herramienta prometedora en aspectos operativos de las empresas modernas, por ejemplo, para predicción de la demanda de los clientes y para optimización de las cadenas de suministro. Así mismo, se plantea como tecnología clave en el entrenamiento de robots para posibilitar tareas de fabricación flexible. En esta corriente, las investigaciones más recientes tienen que ver con los métodos de aprendizaje profundo (“Deep Learning”). La mayoría de los métodos de aprendizaje automático más ampliamente utilizados requieren que un científico de datos defina un conjunto de características que describan cada entrada (métodos supervisados). Con Deep Learning podemos alimentar al algoritmo de Machine Learning con datos en bruto sin necesidad de definir y extraer características previamente, por lo que se suele decir que se trata de aprendizaje automático no supervisado. Así, en problemas donde haya un gran gap entre entradas (imágenes, señales de voz, etc.) y salidas (objetos, frases, etc.), Deep Learning da mejores resultados que los métodos tradicionales. En aquellos problemas donde las características son fáciles de obtener, Deep Learning no aportará muchos beneficios, si alguno. Por otro lado, los algoritmos de aprendizaje profundo son difíciles de entrenar y requieren grandes tiempos de computación, por lo que en la mayoría de los problemas no son los métodos preferidos. También pueden darse casos en los que se combinen ambos con buenos resultados, supervisados y no supervisados. Aunque existen varias maneras de implementar Deep Learning, una de las más comunes es utilizar redes de neuronas. Las redes de neuronas son algoritmos matemáticos que modelan de forma similar a como funciona el cerebro. Esto implica muchos nodos (“neuronas”) que están siempre interconectadas en capas para formar una red. La red de neuronas al menos debe tener dos capas, una de entradas y otra de salidas. Entre la capa de entradas y la de salidas pueden existir capas “ocultas”, que se pueden aprovechar para extraer más información. Si la red tiene más de una capa “oculta”, entonces se considera “Deep Neural Network”. Existen otras arquitecturas de redes de neuronas que también se usan en ocasiones para implementar Deep Learning. Por ejemplo, las redes de neuronas recurrentes, que no tienen una estructura de capas, sino que permiten conexiones arbitrarias entre todas las neuronas, incluso creando ciclos. Esto permite incorporar a la red el concepto de temporalidad, y que la red tenga memoria. 3 “Machine learning challenges and impact: an interview with Thomas Dietterich”. Mayo 2017 https://academic.oup.com/nsr/advance-article/doi/10.1093/nsr/nwx045/3789514
E.2.2 Informe de tendencias tecnológicas en el ámbito del proyecto 7
Otra arquitectura interesante son las redes de neuronas convolucionales. En este caso se mantiene
el concepto de capas, pero cada neurona de una capa no recibe conexiones entrantes de todas las
neuronas de la capa anterior, sino sólo de algunas. Esto favorece que una neurona se especialice
en una región de la lista de números de la capa anterior, y reduce drásticamente el número de
pesos y de multiplicaciones necesarias.
Figura 5. Arquitecturas de Redes de Neuronas para Aprendizaje Profundo (Fuente: DZone.com)
Destacar también que otras de las herramientas utilizadas para implementar Deep Learning son los
auto-codificadores, que normalmente se implementan como redes de neuronas con tres capas
(solo una capa oculta).
Por último, recogemos a continuación los principales retos de investigación en Machine Learning
según los expertos:
Mejorar los métodos de aprendizaje automático no supervisado y de refuerzo, dado que
los avances actuales se han desarrollado en aprendizaje automático supervisado. El
aprendizaje por refuerzo es particularmente útil en problemas de control (conducción
automática de coches, robots, etc.), pero los métodos existentes todavía son muy lentos y
difíciles de aplicar. Además, solo operan en una única escala de tiempo. En este sentido se
está realizando investigación en aprendizaje de refuerzo jerárquico.
Verificación y validación de “cajas negras”. Los resultados del Machine Learning son
sistemas tipo caja negra que aceptan entradas y producen salidas, pero que son difícil de
inspeccionar. Por ello, un aspecto que está en investigación actualmente es el desarrollo
de métodos que permitan crear sistemas de aprendizaje automático más interpretables.
También se está investigando en métodos automáticos para verificación y validación de
sistemas caja negra. Una de las nuevas direcciones más interesantes en este sentido es la
creación de “adversarios” automáticos que intenten romper el sistema de Machine
Learning, pues éstos pueden descubrir entradas que hacen que el programa caiga. Un área
de investigación relacionada es el aprendizaje automático robusto. Se buscan algoritmos
de Machine Learning que funcionen bien incluso cuando sus suposiciones son violadas. El
supuesto más importante es que el conjunto de datos de entrenamiento se asume que está
distribuido independientemente y que es un ejemplo representativo de la futura entrada
al sistema. Varias investigaciones están explorando formas de hacer los sistemas de
Machine Learning más robustos ante fallos de esta suposición.
Sesgos. Con frecuencia hay sesgos en la forma en que los datos se recolectan. La
investigación actual va en torno a desarrollar métodos para detectar estos sesgos y para
crear algoritmos de aprendizaje automático que puedan recuperarse de los mismos.E.2.2 Informe de tendencias tecnológicas en el ámbito del proyecto 8
1.2 Grado de adopción y sectores de aplicación
Según el reciente informe de McKinsey Global Institute, “Artificial Intelligence, the next digital
frontier?”4, la Inteligencia Artificial está a punto de desencadenar la próxima ola de disrupción
digital. La inversión en IA está creciendo rápidamente, liderada por gigantes digitales como Google
y Baidu. Globalmente se estima que los gigantes tecnológicos habrán invertido en IA de 20 a 30 mil
millones de dólares en 2016, donde el 90% del gasto va destinado a investigación y desarrollo y el
10% restante en adquisiciones. También están creciendo las financiaciones capital riesgo y privado,
las subvenciones y las inversiones semilla, alcanzando en 2016 en total entre 6 y 9 mil millones de
dólares de forma combinada. Machine Learning, como tecnología habilitadora de la IA, es la que
está recibiendo más inversión, tanto interna como externa.
Así, los principales proveedores de Machine Learning, según el informe “Machine Learning Market
by Vertical, Deployment Mode, Service, Organization Size, and Region - Global Forecast to 2022”5,
son los siguientes:
Microsoft Corporation
IBM Corporation
SAP SE
SAS Institute Inc.
Google Inc.
Amazon Web Services Inc.
Baidu Inc.
BigML Inc.
Fair Isaac Corporation (FICO)
Hewlett Packard Enterprise Development LP (HPE)
Intel Corporation
KNIME.com AG
RapidMiner Inc.
Angoss Software Corporation
H2O.ai
Alpine Data
Domino Data Lab Inc.
Dataiku
Luminoso Technologies Inc.
TrademarkVision
Fractal Analytics Inc.
TIBCO Software Inc.
Teradata
Dell Inc.
Oracle Corporation
La adopción de IA fuera del sector tecnológico todavía es incipiente, con frecuencia en fase de
experimentación. Pocas empresas lo han puesto en marcha a gran escala. En el citado estudio en
base a encuestas a 3.000 ejecutivos, de 10 países y 14 sectores, solo el 20% reconoce que usa
4 “McKinsey's State Of Machine Learning And AI”. Julio 2017
https://www.forbes.com/sites/louiscolumbus/2017/07/09/mckinseys-state-of-machine-learning-and-ai-
2017/#1ce660a475b6
5 “Machine Learning Market by Vertical, Deployment Mode, Service, Organization Size, and Region - Global Forecast to
2022”. Septiembre 2017 https://www.marketsandmarkets.com/Market-Reports/machine-learning-market-
263397704.htmlE.2.2 Informe de tendencias tecnológicas en el ámbito del proyecto 9
habitualmente cualquier tecnología relacionada con IA a escala o en el núcleo de su negocio.
Muchas empresas expresan que no tienen claro el modelo de negocio o el retorno de la inversión.
Comercialmente, se indica que solo se ha implantado en el 12% de los 160 casos de uso analizados.
El patrón de adopción de IA indica que hay un gap creciente entre los “early adopters” y el resto.
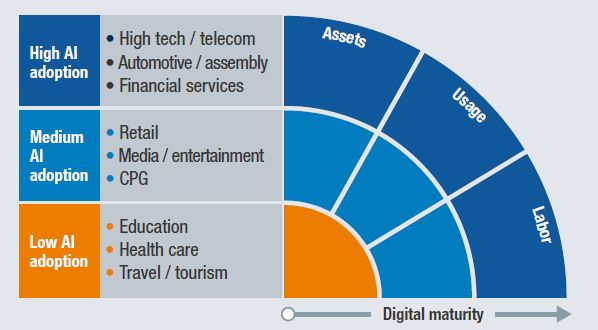
Sectores que están en el top en cuanto a digitalización como el propio TIC, el de automoción y el
de servicios financieros, están también liderando la adopción de IA. Así, los fabricantes de
automóviles usan IA para desarrollar vehículos automáticos y mejorar sus operaciones, mientras
que las empresas de servicios financieros la usan en funciones relacionadas con la experiencia del
cliente.
Figura 6. Adopción de IA por sectores versus nivel de digitalización (Fuente: McKinsey Global Institute)
Figura 7. Grado de adopción de IA por sectores y en la cadena de valor (Fuente: McKinsey Global Institute)
Las primeras evidencias están demostrando el valor que conlleva la apuesta por la IA. En concreto
se observa que aquellos que combinan una capacidad digital potente con estrategias proactivas en
torno a la IA tienen márgenes de beneficio mayores.E.2.2 Informe de tendencias tecnológicas en el ámbito del proyecto 10
En cuanto al retorno de la inversión es interesante la información ofrecida por el informe “State of
Artificial Intelligence for Enterprises” de Teradata 6 , donde se indica que las empresas esperan
obtener globalmente, por cada dólar invertido en Inteligencia Artificial hoy, un retorno de 1,23
dólares en los próximos 3 años, de 1,99 dólares en los próximos 5 años, y de 2,87 dólares en los
próximos 10. Además, según los directivos encuestados en dicho informe, las tres áreas de negocio
donde se están obteniendo ya beneficios mediante la incorporación de IA son el área de I+D o de
innovación de producto, el área de atención al cliente, y el área de operaciones y cadena de
suministro.
Figura 8. Áreas de la organización donde ya se están obteniendo beneficios por la IA (Fuente: Teradata)
Por otro lado, el informe recoge las diferencias existentes por regiones geográficas (América,
Europa, Asia…). Así, en Europa, los mayores retornos de inversión por IA se obtienen en el área de
operaciones y de la cadena de suministro, mientras que América lidera el ROI en el área de ventas
de las organizaciones.
Figura 9. Áreas de la organización donde ya se están obteniendo beneficios por la IA por región (Fuente: Teradata)
Entre los casos de aplicación del citado informe de McKinsey (comercio minorista, eléctricas,
fabricación, salud y educación) destaca el potencial de la IA para mejorar el pronóstico y la
búsqueda de información, optimizar y automatizar las operaciones y el mantenimiento,
desarrollar estrategias de marketing y de precio personalizadas, y mejorar la experiencia de
usuario. En las dos siguientes tablas se detalla cómo la IA puede crear valor a lo largo de la cadena
en los diferentes sectores de aplicación, con ganancias nada despreciables.
6 “State of Artificial Intelligence for Enterprises”. Julio 2017
http://assets.teradata.com/resourceCenter/downloads/AnalystReports/Teradata_Report_AI.pdfInforme de tendencias tecnológicas en el ámbito del proyecto 11
tecnológico e institucional
Aplicabilidad Tecnologías IA Proyectos Producción Promoción Provisión
consideradas (I+D fundamentada, pronóstico (Operaciones con mayor (Productos y servicios al precio (Experiencia del cliente enriquecida,
en tiempo real, búsqueda productividad, menores costes óptimo, para clientes adecuados, personalizada y conveniente)
inteligente de información) y mayor eficiencia) con el mensaje acertado)
Comercio Aprendizaje automático: ALTA Anticipación de tendencias en la Automatización de las Optimización de la tarificación, Consejos y sugerencias
minorista Visión por ordenador: MEDIA demanda, a la vez que se optimiza operaciones de tiendas y promoción personalizada y personalizadas, asistencia directa
Lenguaje natural: MEDIA y se automatiza la negociación y la almacenes. anuncios web personalizados en mediante agentes virtuales,
Vehículos autónomos: ALTA contratación con proveedores Optimización de tiempo real automatización de la salida en tienda,
Robótica inteligente: ALTA “merchandising”, surtido de y provisión completa de última milla
Agentes virtuales: MEDIA productos y microespacios mediante drones
Eléctricas Aprendizaje automático: ALTA Mejora de la predicción de la Optimización del Optimización de la tarificación Automatización de la selección de
Visión por ordenador: MEDIA demanda y de la provisión, mantenimiento preventivo, mediante tarificación dinámica y proveedor, provisión de información
Lenguaje natural: BAJA fiabilidad de los equipos, y mejora del rendimiento de diaria. de consumo, automatización del
Vehículos autónomos: ALTA automatización de la respuesta a producción de electricidad, Emparejamiento de productores y servicio al cliente mediante agentes
Robótica inteligente: ALTA la demanda reducción del gasto energético, consumidores en tiempo real. virtuales, y personalización del uso
Agentes virtuales: MEDIA y prevención de la sustracción según las preferencias del consumidor
de electricidad
Fabricación Aprendizaje automático: ALTA Mejora del rendimiento y Mejora de procesos con Predicción de ventas de servicios Optimización de la planificación de
Visión por ordenador: MEDIA eficiencia en el diseño de realimentación de información de mantenimiento, optimización trayectorias y del enrutamiento de
Lenguaje natural: BAJA productos, automatización del de la tarea, automatización de de la tarificación, y refinamiento flotas.
Vehículos autónomos: ALTA asesoramiento de proveedor, y las líneas de ensamblado, de la priorización de clientes Entrenamiento enriquecido para
Robótica inteligente: ALTA anticipación de requisitos de reducción de errores, limitación potenciales ingenieros de mantenimiento
Agentes virtuales: BAJA piezas de la revisión de productos y mediante pilotos y simulaciones
reducción del tiempo de
provisión de material
Salud Aprendizaje automático: ALTA Predicción de enfermedades, Automatización y optimización Predicción de costes más precisa, Adaptación de terapias y
Visión por ordenador: ALTA identificación de grupos de de la operativa hospitalaria, centrada en la reducción de medicamentos a los pacientes,
Lenguaje natural: BAJA pacientes de alto riesgo, y automatización de los test de riesgos en los pacientes utilización de agentes virtuales para
Vehículos autónomos: BAJA lanzamiento de terapias diagnóstico y diagnósticos más ayudar a los pacientes en sus
Robótica inteligente: MEDIA preventivas rápidos y precisos desplazamientos por el hospital
Agentes virtuales: MEDIA
Educación Aprendizaje automático: ALTA Anticipación a la demanda de Automatización de tareas Aprendizaje personalizado,
Visión por ordenador: MEDIA trabajo, identificación de nuevos rutinarias del profesorado, aprendizaje continuo asesorado por
Lenguaje natural: MEDIA indicadores de rendimiento para identificación temprana de tutores y asesores virtuales, y
Vehículos autónomos: BAJA valorar al alumnado, y ayuda a los señales de desvinculación, y construcción de la autoconciencia de
Robótica inteligente: BAJA graduados para destacar sus optimización de la formación de los estudiantes
Agentes virtuales: MEDIA fortalezas grupos para los objetivos de
aprendizaje
Tabla 1. Escenarios de aportación de valor de la IA en los principales sectores de aplicación (Fuente: McKinsey Global Institute)Informe de tendencias tecnológicas en el ámbito del proyecto 12
tecnológico e institucional
Proyectos Producción Promoción Provisión
(Pronóstico preciso de la demanda, (Mayor productividad y minimización de (Productos y servicios al precio (Experiencia del cliente enriquecida,
búsqueda inteligente de información e I+D reparaciones y mantenimiento) óptimo, para clientes adecuados, personalizada y conveniente)
fundamentada) con el mensaje acertado)
Comercio Mejora del resultado de explotación 30% de reducción del tiempo de 50% de mejora en la
minorista (EBIT) en 1-2% usando Machine almacenamiento usando vehículos autónomos eficiencia de surtido
Learning para anticipar ventas de en almacenes Incrementos de ventas del 4-
frutas y verduras 6% usando modelado
20% de reducción del stock mediante geoespacial para mejorar el
aprendizaje profundo aplicado a la atractivo del micromercado
predicción de compras online
2 millones menos de devoluciones de
producto al año
Eléctricas Reducción del 10% en el uso de Aumento de la producción de energía en un Ahorros de entre 10 y 20 dólares
electricidad nacional mediante la 20% mediante Machine Learning y en la factura mensual usando
utilización de aprendizaje profundo sensorización inteligente para optimizar el Machine Learning para cambiar
para predecir la demanda y la provisión rendimiento de los activos automáticamente los acuerdos
de energía Mejora del resultado de explotación (EBIT) en de suministro de electricidad
10-20% usando Machine Learning para
mejorar el mantenimiento predictivo,
automatizar la predicción de fallas, y aumentar
la productividad de capital
Fabricación Mejora del rendimiento en un 10% por Mejora del tiempo de distribución de material Mejora del resultado de Ahorros en combustible del 12%
circuitos integrados que utilizan IA para en un 30% mediante Machine Learning explotación (EBIT) en un 13% para los clientes de los
mejorar el proceso de investigación y aplicado a determinar el ritmo de transmisión mediante Machine Learning fabricantes, las aerolíneas, por
desarrollo de las mercancías aplicado a la predicción de uso de Machine Learning para la
Reducción de la plantilla TI en un 39% Mejora del rendimiento de producción en un fuentes de ingresos por optimización de rutas de vuelo
por la utilización de IA para la 3-5% servicios y a la optimización
automatización completa de los de esfuerzos de ventas
procesos de compras
Salud Potencial ahorro de 300.000 millones Mejora de productividad entre 30 y 50% por el Reducción de gastos Ahorros de entre 2 y 10 trillones
de dólares en Estados Unidos por el uso apoyo a enfermería mediante herramientas IA sanitarios de entre 5 y 9% globalmente por medicinas y
de herramientas de Machine Learning Ahorro de hasta un 2% del Producto Interior por el uso de Machine tratamientos personalizados
para pronóstico de salud poblacional Bruto por eficiencias operativas en los países Learning para personalizar Aumento de la esperanza de vida
desarrollados los tratamientos y mantener media de entre 0,2 y 1,3 años.
a los pacientes involucradosInforme de tendencias tecnológicas en el ámbito del proyecto 13
tecnológico e institucional
Educación 40% de las preguntas rutinarias de estudiantes Incremento del 1% de las 85% de coincidencia con
pueden ser contestadas por ayudantes o inscripciones mediante la clasificación humana, usando
tutores virtuales utilización de asistentes Machine Learning y modelado
virtuales que hagan el predictivo
seguimiento de los
solicitantes
Tabla 2. Ejemplos de impactos en el negocio relacionados con la IA de casos de uso actuales (Fuente: McKinsey Global Institute)Informe de tendencias tecnológicas en el ámbito del proyecto 14
tecnológico e institucional
Por último, en dicho informe de McKinsey se destaca que, para la puesta en marcha con éxito de
esta transformación digital y analítica, las empresas deben: identificar el modelo de negocio,
establecer el ecosistema de datos adecuado, construir o adquirir las herramientas de IA y adaptar
los procesos de trabajo, las capacidades y la cultura de la organización. Algunos facilitadores clave
son la apuesta decidida desde la Dirección, capacidades técnicas y de gestión, y el acceso continuo
a los datos.
Así, algunos de los retos que se presentan a empresas, desarrolladores, gobiernos y empleados en
este contexto son: la actualización de las capacidades de los empleados, la atracción de talento e
inversión por parte de ciudades y países que les sitúen como núcleos de innovación, y la necesidad
de considerar los aspectos éticos, legales y regulatorios.
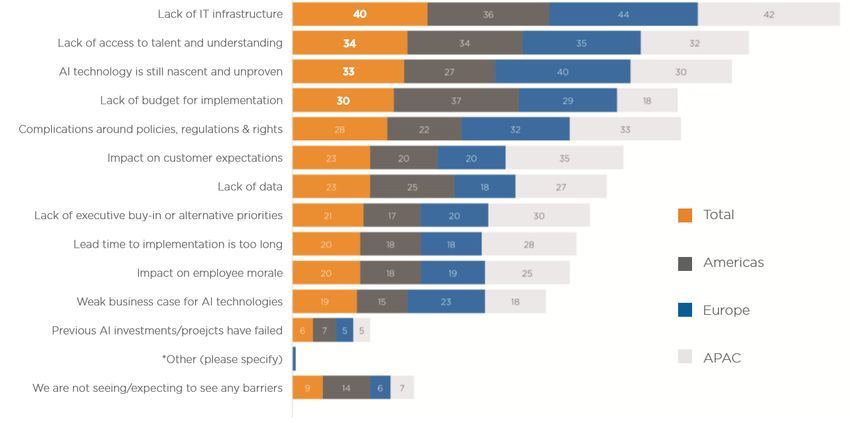
En este sentido, en el citado informe de Teradata también se analizan en detalle las barreras
existentes para la adopción de la Inteligencia Artificial en distintas regiones, que van en línea con lo
mencionado anteriormente, destacando dos principales: la falta de infraestructura TI y la falta de
talento y conocimiento en las organizaciones.
Figura 10. Barreras a la adopción de la IA en las empresas (Fuente: Teradata)Informe de tendencias tecnológicas en el ámbito del proyecto 15
tecnológico e institucional
2 “Machine Learning” en el sector Salud
2.1 Contexto y oportunidades
El Aprendizaje Automático o Machine Learning identifica patrones entre datos de diferente
naturaleza y predice comportamientos a través de algoritmos con capacidad de aprender y
evolucionar basándose en su propia experiencia. En el ámbito de la salud, los análisis predictivos
generados por esta disciplina podrían implicar un avance importante en áreas de prevención,
detección temprana de enfermedades y control de las mismas, aspecto crucial en una sociedad
envejecida donde aumentan las enfermedades crónicas. La Inteligencia Artificial que, a través de
Big Data y Machine Learning, permite convertir datos en conocimiento, apunta a convertirse en la
gran aliada de la prevención primaria y el cuidado de la salud de los próximos años, mejorando la
calidad de vida del paciente7.
Para la aplicación exitosa de Machine Learning en el cuidado de la salud, tan importantes como los
algoritmos son los datos. Tal y como se indica en el informe de Orion Health, “Machine Learning in
Healthcare”8, en un futuro no muy lejano el personal médico tendrá que hacer frente a un tsunami
de información sanitaria de los pacientes, en cuando se incorporen datos genómicos, de
microbioma y hasta el régimen de aptitudes físicas. Como se observa en la siguiente figura, el
espectro de datos sanitarios útiles es muy amplio y variado (datos clínicos habituales, datos
sociales, imágenes médicas, genoma, transcriptoma, metaboloma, proteoma, microbioma,
epigenética, exposoma, datos recogidos con dispositivos wearables, etc.).
Figura 11. Datos útiles para la Medicina Personalizada (Fuente: Orion Health)
7 “Inteligencia artificial aplicada al diagnóstico y al tratamiento de las enfermedades”. Mayo 2017,
https://www.diagnosticsnews.com/empresas/26573-inteligencia-artificial-aplicada-al-diagnostico-y-al-tratamiento-de-
las-enfermedades
8 “Machine Learning in Healthcare”. http://web.orionhealth.com/rs/981-HEV-
035/images/OrionHealth_Machine_Learning_book_ROW.pdfInforme de tendencias tecnológicas en el ámbito del proyecto 16
tecnológico e institucional
Toda esta información deberá ser almacenada en la nube, en el registro electrónico del paciente,
pues se estima que alcanzará un volumen de 6 terabytes. Y es de hecho, la existencia de estos
grandes conjuntos de datos y de disciplinas para su análisis como el aprendizaje automático, la que
posibilitará la medicina de precisión o personalizada, tendencia mundial que permitirá:
Mejorar el cuidado de la salud.
Reducir la morbilidad y la mortalidad.
Incrementar la eficacia, precisión y efectividad de los tratamientos, y eliminar las reacciones
adversas a los mismos.
Reducir los costes de atención sanitaria
Así, las tecnologías de inteligencia artificial basadas en datos permitirán la identificación de
ineficiencias en los mercados sanitarios, reduciendo costes y carga de trabajo de los médicos.
Permitirán capturar grandes volúmenes de datos que describen el estado actual de los pacientes y
su pasado, proyectan estados futuros potenciales, analizan los datos en tiempo real, ayudan en la
toma de decisiones para alcanzar los objetivos clínicos, y proporcionan apoyo en tiempo real y
constante tanto a paciente como a profesional médico. Se pronostica que el 80% de las tareas
actuales de los médicos serán realizadas por esta disciplina tecnológica, dejándoles mayor tiempo
para trabajar con el paciente. No se tratará de “doctores robots”, sino de hacer más eficientes los
procesos de consumo y generación de datos, actualmente manuales y de gran consumo de tiempo
para los profesionales clínicos.
En definitiva, en los próximos años, el sector salud tiene la oportunidad de transformarse
completamente gracias a estas tecnologías. Algunos casos de uso serán9:
Entrenamiento médico con asistentes virtuales de inteligencia artificial (por ejemplo,
usando herramientas software similares al Siri de Apple, pero especializadas en salud). Los
asistentes inteligentes proporcionan apoyo y recomendaciones en tiempo real que ayudan
al médico en el diagnóstico y el tratamiento, además de dar soporte administrativo.
Ejemplos reales son Watson de IBM o la aplicación de Ada. Los asistentes virtuales
asimilarán, analizarán y compartirán grandes cantidades de datos de pacientes individuales
y de grupos de pacientes, tarea imposible de gestionar a mano. Los datos serán de todo
tipo: historias clínicas, estadísticas de epidemias y amenazas de salud, imágenes, vídeos,
datos de localización, comentarios de los médicos, etc.
Asistencia de más pacientes con enfermedades crónicas. Una inteligencia artificial básica
puede ser usada en la práctica clínica para alertas y recordatorios, diagnóstico, planificación
de terapias, recuperación de información e interpretación de imágenes médicas. Los
asistentes pueden tener habilidad conversacional y dar soporte a los médicos en
mensajería con los pacientes, respondiendo preguntas rutinarias, sugiriendo opciones de
tratamiento, etc.
Prevención y mantenimiento de la salud en pacientes y personas sanas. Una de las
grandes oportunidades de la inteligencia artificial en salud es mantener a la gente saludable,
más que tratarles si están enfermos. Los asistentes virtuales de inteligencia artificial serán
capaces de adquirir conocimiento profundo de la dieta, el ejercicio, las medicinas, el estado
emocional y mental, etc. Las tecnologías de visión por ordenador, comprensión del lenguaje
natural y aprendizaje automático, presentan capacidades de interfaz que permiten a las
personas hablar fácilmente con su asistente virtual acerca de lo que están haciendo.
Además, mediante detección de movimiento, sensores IoT y otros pueden recogerse
fácilmente datos personalizados y útiles, que permiten al asistente avisar, apoyar e incluso
animar a que hagan acciones más saludables.
9“What AI-enhanced health care could look like in 5 years”. Julio 2017. https://venturebeat.com/2017/07/23/what-ai-
enhanced-healthcare-could-look-like-in-5-years/Informe de tendencias tecnológicas en el ámbito del proyecto 17
tecnológico e institucional
Dispositivos médicos en el hogar para una monitorización más precisa y en tiempo real,
consiguiendo una población más saludable. En línea con los últimos avances en tecnología
de imagen y sensórica, se está generando equipamiento médico para el hogar capaz de
monitorizar diferentes variables biométricas y tomar medidas con frecuencia. Por ejemplo,
AliveCor para el seguimiento del ritmo cardíaco o Scanadu, que usa IA para medir el nivel
de compuestos químicos en muestras de orina.
Nuevas herramientas para diagnóstico y tratamiento de enfermedades basado en datos
recogidos de los smartphones, que cuentan con cámaras de gran resolución, acelerómetros,
giroscopios, micrófonos, etc. Por ejemplo, movimientos pequeños de la mano cuando se
sostiene un móvil pueden proporcionar pistas de la enfermedad de Párkinson, un cambio
en el uso de las redes sociales puede implicar depresión, el análisis de patrones vocales o
de sentimiento en el discurso puede identificar ansiedad, etc.
Asistencia a pacientes en el hogar mediante robótica y sistemas de inteligencia artificial.
Los robots podrán ayudar a los pacientes en sus casas a recodar tomar la medicación, en
las tareas del hogar como lavar los platos o hacer la colada, a acercar objetos fuera del
alcance de pacientes en silla de ruedas, a ayudar a las personas mayores en el baño y aseo
personal, e incluso a dar apoyo emocional, como las mascotas robot japonesas.
2.2 Retos de investigación y desarrollo tecnológico
En esta sección se revisan los retos y oportunidades desde el punto de vista técnico y tecnológico
de la aplicación de esta disciplina de la Inteligencia Artificial en el ámbito de la salud.
Según el informe “Big Data Technologies in Healthcare. Needs, opportunities and challenges”10, de
la Big Data Value Association (BDVA), los principales retos técnicos giran en torno a los datos y a
las plataformas e infraestructuras para su manejo, tal y como apuntábamos en el apartado previo:
Calidad de los datos. En investigación médica y farmacéutica, es necesario contar con
resultados fiables y reproducibles, teniendo en cuenta que además la recopilación de datos
es muy cara. El conocer la procedencia de los datos, esto es, cómo se recopilaron, en qué
condiciones, y cómo han sido procesados y transformados antes de ser almacenados, es
importante para la reproducibilidad de los análisis y experimentos, así como para
comprender la fiabilidad de los mismos, que puede afectar a los resultados de la
investigación.
Cantidad de datos. Ya se ha apuntado cómo el sector salud depende de los datos y su
análisis para mejorar los tratamientos y prácticas clínicas. Y como cada vez se está
recolectando más información del paciente. Es necesario lidiar con este gran volumen de
datos para mejorar la eficiencia y calidad del servicio sanitario.
Datos multi-modales. Los tipos de información sanitaria disponibles son muy amplios, tal
y como se refleja en la figura previa. Pueden ser estructurados y no estructurados. La fusión
de múltiples fuentes de datos sanitarios permitirá encontrar sinergias entre los mismos que
ayuden a mejorar la toma de decisiones clínicas e incluso a descubrir nuevos enfoques en
el tratamiento de las enfermedades. Esta combinación y análisis multi-modal tiene que
superar retos técnicos relativos a la interoperabilidad, al aprendizaje automático y a la
minería de datos.
Acceso a los datos. Actualmente siguen existiendo limitaciones y barreras en cuanto al
acceso y compartición de datos sanitarios entre diferentes instituciones y países. Se deben
resolver aún aspectos de privacidad, ética y seguridad de la información, para minimizar los
actuales silos de información que imposibilitan que ésta sea explotada al máximo.
10 “Big Data Technologies in Healthcare. Needs, opportunities and challenges”. Diciembre 2016
http://www.bdva.eu/sites/default/files/Big%20Data%20Technologies%20in%20Healthcare.pdfInforme de tendencias tecnológicas en el ámbito del proyecto 18
tecnológico e institucional
Datos generados por el paciente. La proliferación de sensores, tecnologías y dispositivos
“wearables” está posibilitando la monitorización de las actividades diarias y las respuestas
a tratamientos de pacientes crónicos, implicando al paciente en el cuidado de su salud y
mejorando el cuidado de estas enfermedades crónicas. Aquí el principal reto tiene que ver
con la procedencia de los datos, esto es, con el proceso de registro y almacenamiento de
los mismos, lo que debe solventarse mediante estandarización y armonización de las
infraestructuras de transferencia de datos.
Usabilidad / Puesta en marcha de la metodología. Para sacar el máximo provecho al
análisis avanzado de los datos sanitarios, es necesario definir concienzudamente las capas
de análisis y presentación de resultados, lo que requiere de la colaboración de los
departamentos TI y de los equipos directivos de las instituciones sanitarias.
Computación a exascala. Solo con mejoras radicales de capacidad y rendimiento
computacional podrá llevarse a cabo la medicina de precisión tan deseada. Para poder
analizar grandes cantidades de datos clínicos y genómicos que permitan el desarrollo de
tratamientos personalizados son necesarias las computadoras a exascala, máquinas que
pueden desarrollar mil millones de cálculos por segundo y tienen 100 veces más potencia
que los sistemas más rápido de hoy en día.
Infraestructura. Para poder manejar y explotar este tsunami de datos serán necesarias
nuevas infraestructuras fiables, estables y bien diseñadas. La virtualización y la
computación en la nube están ya facilitando el desarrollo de plataformas que permiten una
captura, almacenamiento y manipulación de grades volúmenes de datos más efectiva. Ya
hay tecnologías que van en esta dirección (Hadoop, MapReduce, MongoDB, Cassandra,
Lucene, etc.), pero todavía quedan algunos requisitos o aspectos a solventar como la
escalabilidad dinámica, la computación distribuida, el trabajo con bases de datos no
tradicionales o la interoperabilidad entre infraestructuras.
En lo que refiere a la propia Analítica de Datos, según el citado informe de la BDVA, los enfoques y
métodos especializados para el análisis de grandes cantidades de datos en salud giran en torno a
estas disciplinas y retos tecnológicos:
Aprendizaje Automático avanzado y aprendizaje por refuerzo. Mediante sistemas de
aprendizaje automático avanzados se puede relacionar información de muchas fuentes e
identificar correlaciones “ocultas” o inapreciables cuando solo se usa una fuente de datos.
Esto permitirá el desarrollo de herramientas para diagnóstico automático y medicina
personalizada. El aprendizaje por refuerzo es un nuevo y prometedor método de
aprendizaje automático avanzado basado en recompensas o castigos. En el contexto
sanitario, podría ser aplicado para descubrir y optimizar automáticamente tratamientos
secuenciales para enfermedades crónicas y potencialmente mortales.
Enfoques basados en el conocimiento. El uso de bases de conocimiento construidas a
partir de ontologías sofisticadas está siendo una forma efectiva de expresar conocimiento
médico complejo y de apoyar la estructuración, gestión de calidad e integración de datos
médicos. Aprender de los datos complejos puede posibilitar la obtención de patrones en
los mismos más concisos, descriptivos y ricos semánticamente lo que repercute en mayor
relevancia clínica.
Aprendizaje Profundo. Típicamente se refiere a un conjunto de algoritmos de ML que
obtienen modelos jerárquicos profundos que deducen relaciones altamente no lineales en
los datos de entrada de bajo nivel y no estructurados. Estos algoritmos pueden usarse
paralelamente y así permitir el análisis de muy grandes y complejos datos, como imágenes
o vídeos, datos textuales u otra información no estructurada. Son especialmente
prometedores en el análisis de imágenes médicas, radiológicas o patológicas.Informe de tendencias tecnológicas en el ámbito del proyecto 19
tecnológico e institucional
Analítica en tiempo real. Existen aplicaciones sanitarias críticas que requieren actuación en
tiempo real, por ejemplo, cuando salta una alarma en la UCI. En ese contexto se debe ser
capaz de analizar múltiples flujos de datos heterogéneos en tiempo real.
Razonamiento clínico. Existe la necesidad de mejorar la toma de decisiones clínicas
mediante la incorporación de información de varios tipos (texto libre, mensajes de voz,
registros médicos, ontologías médicas, etc.) y donde la semántica lo facilite. El
razonamiento clínico aprovecha varias técnicas como la representación de información
distribuida, el aprendizaje automático, el procesamiento del lenguaje natural, el
razonamiento semántico, la inferencia estadística, la lógica difusa, el procesamiento de
imagen, el procesado de señal y las comunicaciones sinápticas en neuronas biológicas.
Analítica de datos dirigida por el usuario final. En el contexto sanitario, los usuarios son
expertos en el dominio (un doctor, un investigador biólogo, un gestor hospitalario, etc.)
pero carecen de conocimiento profundo de estadística, de procesado de datos y de
métodos y herramientas de análisis de datos. Es necesario herramientas inteligentes pero
fáciles de usar que permitan a los profesionales sanitarios hacer uso de la toma de
decisiones basada en datos a todos los niveles.
Procesado del lenguaje natural y análisis de texto. Los datos textuales forman parte de la
categoría de no estructurados, como las imágenes y los vídeos, debido a las complejidades
de sus estructuras internas. Se han creado tecnologías de recuperación de información y
análisis de texto para facilitar el acceso a esta gran cantidad de información textual. Se trata
de tecnologías y métodos en lingüística computacional y ciencias de la computación, como
el aprendizaje automático, para la detección y análisis automático de información relevante
en contenido textual no estructurado (texto libre).
Bases de conocimiento de salud. La creación de bases de conocimiento semánticas para
salud tiene un altísimo potencial e impacto práctico, puesto que facilitan la integración de
datos de múltiples fuentes, permiten el desarrollo de sistemas de filtrado de información y
facilitan las tareas de descubrimiento de conocimiento. En concreto, en los últimos años la
iniciativa Linked Open Data (LOD) ha alcanzado un grado de adopción significativo y se
considera la referencia práctica para la compartición y publicación de datos estructurados
en la web. Los datos sanitarios se generan en varias fuentes con diversos formatos que usan
diferentes terminologías, lo que provoca una muy baja accesibilidad a los mismos por parte
de los sistemas de análisis y de apoyo a la decisión clínica. Existen varios estándares de
vocabulario que describen problemas y procedimientos clínicos, medicamentos etc. pero
sigue necesitándose investigación en el procesado, reingeniería, enlace, formalización y
consumo de datos abierto. Actualmente, algunas agencias y organizaciones internacionales
están haciendo uso de estas bases de conocimiento semánticas en los sistemas sanitarios
para mejorar la precisión de los diagnósticos, al proporcionar en tiempo real correlaciones
de síntomas, resultados de test, etc. ; para ayudar a construir sistemas de información
sanitaria más potentes e interoperables; para apoyar el proceso de transmisión,
reutilización y compartición de datos de los pacientes; para proporcionar criterios
semánticos en las agregaciones estadísticas con diferentes propósitos en el ámbito clínico
y para, en definitiva, la integración de conocimiento de salud.
Análisis genómico de alto rendimiento. Actualmente las aplicaciones clínicas de
secuenciación de próxima generación se focalizan principalmente en la secuenciación del
exoma, que es el 2-3% del genoma, y en ensayos muy concretos, como los paneles
diagnósticos de genes cancerígenos. El diagnóstico de todo el genoma cada vez se está
haciendo más barato y accesible, pero para que pueda ser útil a miles de pacientes en cada
gran hospital cada año, necesitan solventarse las necesidades de computación y
almacenamiento. No es suficiente con sistemas computacionales individuales como hasta
ahora, sino que es necesario enfoques nuevos de concurrencia y paralelismo para una
mayor eficiencia y optimización.También puede leer

















































