JADAWeb: A CBR System for Cooking Recipes
←
→
Transcripción del contenido de la página
Si su navegador no muestra la página correctamente, lea el contenido de la página a continuación
JADAWeb: A CBR System for Cooking Recipes
Miguel Ballesteros, Raúl Martı́n and Belén Dı́az-Agudo
Department of Software Engineering and Artificial Intelligence, Universidad
Complutense de Madrid, Spain.
miballes@fdi.ucm.es, rmb2000@gmail.com, belend@sip.ucm.es
Abstract. Recommender systems are used in a multitude of topics and
serve to generate automatic proposals by using the preferences of the
final user. JADAWeb system is able to recommend recipes known users
cuisine preferences and their constraints. The system is a third version of
JADACook[1], that was presented in previous Computer Cooking Con-
test, it improves the funcionality and expands the capacity by using
different tools.
1 Introducción
In this paper we describe JADAWeb, that is a third version of JADACook[1],
a CBR system that solves the task of suggest, to the final user, cooking recipes
given a rescricted set of ingredients and some optional dietary practices.
JADAWeb is able to adapt the user requests to a consistent recipe by sub-
stituting ingredients by using a similarity functio based on what it would be
possible to exchange any 2 ingredients based in a table of fuzzy similarities.
JADAWeb has been implemented using the jCOLIBRI framework [2], which is
a big help when planning a recommender system and it solves many of the tasks
of development.
JADAWeb is presented as a web system by using JSP [3] technology where
the input of data is a single character string on natural language, in English. We
implemented an algorithm to detect the negation in a sentence so it is able to
infer which ingredients the user want and which do not want. The algorithm is
based on multilingual dependency parsing[5].
JADAWeb also brings a number of substantial improvements in the decision
of which nouns that are present in the query are ingredients and which are not.
While in previous versions of JADACook the system only consider if the noun is
present in the ontology, JADAWeb search the noun in Wordnet[4] to infer if the
noun is an ingredient or not. We implemented, also, an algorithm that decides
which part of the ontology is better for the new ingredient if it was not present
before.
The JADAWeb suggestions are sorted according by the characteristics of
the season. Hotter meals, like a soup, will be presented before in winter, and
fresh meals, like salad, will be presented before if the query is in summer. The
information that JADAWeb uses to make this decision is the presence, or not,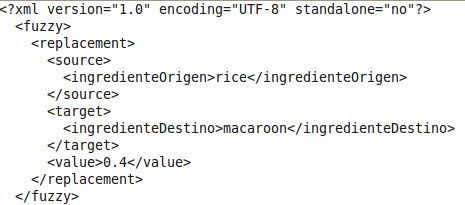
of some important words that are present in each recipe, like ‘hot’, ‘oven’, or
‘fresh’.
This paper is organized as follows: Section 2 describes the web-based graph-
ical user interface and the parsing of the input data. In Section 3 we define how
the adquisition of knowledge works. Section 4 describes the proccess of the case-
based reasoning, focusing on the similarity function and an evaluation measure
for it. Section 5 describes a set of examples tested in the system. Finally, Section
6 shows the conclusions and suggests some future work.
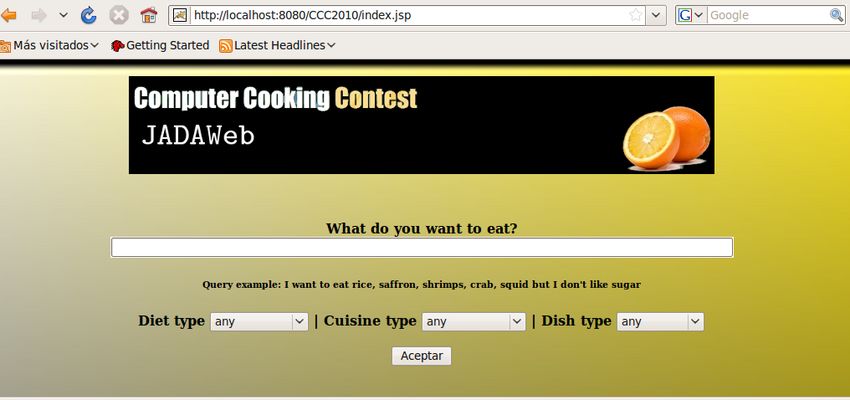
2 Web-Based Graphical User Interface
In this section we present how the web-based graphical user interface is built
and which stages it follows to generate the query that the system will process.
The interface ask the user with a simple form, what the user wants, i.e: ”I want
to eat some fruits, like apple, but I don’t like kiwi”. The system will connect to
de dependency text parser to obtain the information contain in this query and
by using an algorithm generate which ingredients the user wish and which not.
It has been proposed in this system the use of several languages, in fact,
we implemented a tool that use an API of GOOGLE to translate by using
the ‘www.wordreference.com’ dictionary. The problem of this idea is that it
translates word by word, and this is because is not posible to use it in JADAWeb.
Some improvements in this area could be a good suggestion for future work.
Fig. 1. Web-Based Graphical User Interface
After infer this information the system shows what is the result of the parser.
The interface asks the user if he/she wish some dietary practices or if he/she
likes different type of cuisine(chinese, italian, etc.).
2.1 Textual Parsing of the Input
In this version of the recommender system we decided to propose a textual
input for the wishes and petitions of the final user. The textual input must be
in English and the user might express which ingredients he/she has and which
not. To make it possible we implemented an algorithm to detect the negation on
sentences by using dependency parsing[5].
The dependency parser used was Minipar[6], it has an API implemented in
C language and given a text plain sentence, Minipar returns a dependency tree,
like Figure 2. Using a wrapper1 for JAVA we can studied the information given
by the parser easy.
Given the tree with the dependency analysis we have implemented an algo-
rithm that detects the attachment of each noun and those who share the same
branch of a negation are marked as candidates for unwanted ingredients. All
other nouns are marked as wanted ingredients.
Fig. 2. Dependency tree.
The Figure 2 shows the information that Minipar parser return for the fol-
lowing sentence: ‘I want rice but I don’t want onions’, using this information our
algorithm infers the knowledge.
The results obtained by the algorithm are reliable but there are few errors
given by bad labelling from the dependency parser, Minipar.
Dependency parsing is an inportant branch on artificial intelligence research.
computational linguistics and machine learning. Where the best results achieve
by a dependency parser are around 90% of accuracy, because of that there is a
little posibility of error.
1
http://nlp.shef.ac.uk/result/software.html
3 Knowledge acquisition
La fuente fundamental de conocimiento que contiene JADAWeb es la Ontologı́a
de ingredientes heredada de los sistemas predecesores. Que fue construida incre-
mentalmente, conceptualizada y formalizada en el lenguaje OWL2 .
Además de la ontologı́a JADAWeb plantea una nueva forma de adquirir in-
gredientes no integrados en la misma mediante el sistema Wordnet[4] para de-
cidir si un sustantivo es realmente un ingrediente y posteriormente que tipo de
ingrediente.
3.1 Ontology
Como sus predecesores JADAWeb está basado en una ontologı́a que captura
el conocimiento del dominio de la cocina, organizando objetos(ingredientes) en
categorı́as para permitir la herencia de propiedades y crear taxonomı́as. En la
ontologı́a existen ingredientes de origen animal agrupados en varias subfamilias:
carne, pescado, leche, queso y huevos. Ingredientes de origen vegetal también
agrupados en varias subfamilias como cereales, frutas y vegetales. Existen otras
familias principales de ingredientes como dulces, bebidas e ingredientes básicos
como sal y aceite.
En esta versión de JADAWeb hemos decidido no ampliar la información
contenida en la ontologı́a ya que actualmente aporta un abanico de conceptos
muy elevado, dejando la ampliación del conocimiento de base a la utilización de
otra tecnologı́a como es Wordnet.
Aunque no hemos ampliado la ontologı́a, si que se ha modificado, para facili-
taztar la búsqueda y la igualdad entre palabras obtenidas por wordnet, quitando
plurales y palabras compuestas. Por ejemplo, se ha cambiado AnimalOrigin y
plantorigin por animal y plant, Drinks por drink y algunos más parecidos.
3.2 Ingredient treatment using Wordnet
A pesar de la riqueza expresiva de la ontologı́a y amplio rango de definición en
el dominio de la cocina, hemos implementado un sistema para detectar nuevos
ingredientes en la entrada del usuario para poder usarlos posteriormente.
Una vez obtenidos los sustantivos candidatos para ser ingredientes se com-
prueba si los mismos se encuentran en la Ontologı́a. Si el elemento no se encuen-
tra en la ontologı́a no se deshecha todavı́a. Utilizando WordNet se comprueba
si la definición dada de ese sustantivo es plausible de pertenecer a alguna de las
categorı́as presentes en la ontologı́a, si es ası́ se añade a la memoria del sistema,
si se concluye que no finalmente se deshecha el elemento.
2
http://www.w3.org/2004/OWL3.3 Algorithm definition
Este sistema va a buscar el lugar exacto dentro de la ontologı́a donde se va
introducir el nuevo elemento. Ésto se consigue usando Wordnet. Wordnet es una
base de datos léxica de Inglés, desarrollada en la universidad de Princeton bajo
la dirección de George A. Miller. Permite, a partir de una palabra, obtener su
definición, sinónimos, antónimos entre otras operaciones. Esta herramienta nos
ha sido de gran utilidad para poder trabajar con la ontologı́a.
La primera operación que usamos con Wordnet es detectar si un ingrediente
está ya registrado, no solo se busca su nombre, si no que se buscan todos los
sinónimos. Si algunos de los sinónimos está en la jerarquı́a, se dará por cumplida
la búsqueda. Si no, hay que introducirlo.
El analizador sintáctico devuelve dos listados de ingredientes, que son los que
el usuario quiere utilizar y los que rechaza, ya sea por gusto o por no disponibili-
dad. El sistema de actualización de ontologı́a resuelve lo siguiente: coge cada uno
de los elementos de este listado y comprueba si están registrados. Si están esos
elementos o cualquiera de los sinónimos, no hace nada; si no están, los introduce
para tenerlos en cuenta en peticiones siguientes.
Para introducir un ingrediente en la ontologı́a, se parte de la definición. De
ésta, se cogen solo los sustantivos (Wordnet dispone de una función que, dada
una palabra, devuelve si es nombre, adjetivo, adverbio o verbo), descartando las
demás partes de la oración que para este caso puede añadir confusión. Todos los
sustantivos de la definición se buscan en la estructura. Si todas estas palabras
pertenecen al árbol y están en la misma rama (una rama es la parte del árbol
cuyos elementos guardan la relación sucesor antecesor unos de otros. Un hijo es
sucesor de su padre, abuelos... y el padre antecesor de hijos, nietos,...), serı́a fácil
localizar al padre del nuevo ingrediente, pero no siempre es ası́. En este caso,
el padre serı́a el elemento de la misma rama más bajo siempre y cuando no sea
hoja. Si es hoja, es el padre de la hoja.
El segundo caso es que en la definición aparazcan palabras que están en dis-
tintas ramas, se comprobará en cada rama cual de ellas contiene más elementos
de la definición en su rama. El sistema va a seguir buscando por aquella rama
que más sustantivos en la ontologı́a tenga Si dos o más ramas tienen el mismo
número de ingredientes, el elemento tendrá varios posibles padres (recordamos
que el sistema está buscando el mejor padre para colgar el nuevo ingrediente).
Este es el único caso en el que se se devuelven dos padres para que elija el usuario.
El resto de casos, se obtiene solución única al problema, aunque no siempre será
la ideal.
Si dentro de una rama, aparecen elementos de bifurcaciones diferentes, se
cogerá como padre el último elemento común.
De esta forma, se introducirá el ingrediente la forma más ajustada posible por
su definición, obteniendo resultados realmente buenos. (tiburón, buey, azafrán,
levadura, tofu, mandarina, guisante, salchichón, chorizo, ...). Para un 85 % ofrece
un padre muy aceptable.Fig. 3. Fragmento de la ontologı́a que usa JadaWeb, indicando dos ejemplos de ramas
dentro del árbol.
3.4 Cases
En esta nueva versión del sistema hemos usado la base de casos que se propor-
ciona por los organizadores del CCC-10, que es la misma que para el CCC-09.
Los casos, que describen las recetas, están organizados en un fichero XML, que
es procesado utilizando SAX y DOM donde la información es extraida y alma-
cenada como caso en la memoria del sistema.
4 Case-Based reasoning process
4.1 Similitude function
La función de similitud usado por JadaWeb está basado en JadaCook2, pero con
nuevas incorporaciones. La primera es la posibilidad de buscar ingredientes de
adaptación no solo entre los hermanos, sino también subiendo por la jerarquı́a.
La forma de buscar esta adaptación es restando 0.2 de 1 por cada vez que se
suba un nivel. De esta forma, se asemeja a los grados de parentesco familiares.
Si se busca entre descendientes, no penaliza. Esta búsqueda se parametriza,
dejando por defecto el valor 1 (busca por los hijos del ingrediente en cuestión, y
los hijos del padre). Si se permite búsqueda de más niveles, busca por los hijos
del antecesor del nivel parametrizado, penalizando, como hemos dicho, 0.2 por
subida de nivel.
Otra cuestión que tiene en cuenta en la función de similitud es el uso de
una tabla difusa de comparación entre ingredientes o tipo de ingredientes. EsFig. 4. Ejemplo de sustitución fuzzy.
una página XML donde se introducen que elementos pueden ser sustituidos por
cuales y con que valor. Por ejemplo, arroz por pasta en un 0.8. Esta función,
aunque es bastante general, ya que permite la adaptación entre ingredientes o
tipos de estos de distintas ramas, es fácilmente mejorable, pues en la versión
actual solo sustituye los elementos de la tabla (XML), sin tener en cuenta sus
hijos. Lo ideal es que si, por ejemplo, puedo adaptar carne por pescado, los hijos
de animal se puedan adaptar por hijos de pescado.
4.2 Measure evaluation of the similitude function.
Como medida de evaluación de la función de similitud y en definitiva del sistema
completo hemos planteado el siguiente experimento.
Table 1. Resultados obtenidos en la evaluación.
Nivel Satisface Sustituciones
1 90.0% 5.0%
2 70.0% 10.0%
3 40.0% 30.0%
Se ha probado la aplicación con un grupo de personas (12 personas) reali-
zando 5 querys cada uno.
Cada usuario introducı́a su petición escribiendo la query en inglés y el dándoles
a elegir entre el nivel de adaptación que quieres (previamente, se les ha explicado
que repercusión tiene esa elección). Con los datos introducidos, el usuario, para
valorar su satisfacción, tiene en cuenta los 5 platos recomendados, y también el
orden entre ellos. De esta manera, puede ser que la primera opción sea mala,
pero que los 5 mostrados sean buenos, o a la inversa.
Hay que destacar que la entrada de la query en Inglés para que la reconozca
el analizados tiene que seguir ciertos patrones y debe estar bien escrita. Estospatrones son, por ejemplo, suprimir adverbios cuantitativos (muy dulce, mucho
jamón). Aún ası́, el porcentaje de aceptación por el analizador a la hora de
introducir la query es de un 97% de las bien escritas.
Con todo esto, el resultado obtenido ha sido bastante bueno. Las pruebas se
han realizado con los tres niveles de adaptación de ingredientes oteniendo los
siguientes resultados.
5 Results and examples
Con el nivel de adaptación entre hermanos, la satisfacción con el plato recomen-
dado es muy buena. Sin embargo, la cosa disminuye cuando usamos niveles su-
periores. El motivo es porque adapta elementos que no esperamos, dando como
resultado platos distintos (por ejemplo, al sustituir el limón por pan, el resultado
se ve bastante afectado, aunque también un cambio de más nivel puede tener
su encanto en la recomendación). Con una ontologı́a de más profundidad, las
adaptaciones a mayor nivel darı́an resultado mucho más satisfactorios. Aún, el
porcentaje de 70% en nivel 2 es bueno, mientras que el 40% del nivel 3 es muy
bajo.
El número de sustituciones, también aumenta a medida que incrementamos
el nivel de adaptación. Esto también es lógico, porque entran más ingredientes
en juego.
Como ejemplo sencillo a la aplicación mostramos una serie de sencillas querys
y adjuntamos los resultados que ofrece nuestra aplicación, de esta manera se
puede evaluar la calidad de las sugerencias. Para cada query el sistema devuelve
las cinco sugerencias a las que la función de similitud ha dado mayor valor.
First Experimento En este experimento se prueba con una query orientada a
obtener una paella por los ingredientes que se solicitan. No se especifica ningún
tipo de dieta, ni tipo de cocina ni tipo de plato
Q1: ’I want to eat rice, saffron, shrimps, chicken, crab, squid but I don’t like
sugar’.
Sugerencias: En primer lugar, el sistema devuelve una Paella(Paella in a Pot) que
contiene buena parte de los ingredientes contenidos en la query. Posteriormente
devuelve otros platos que contienen los ingredientes de la query.
Second Experiment En este experimento se prueba con una query en la que
se le dice al sistema que se desea una pizza de jamón, queso y tomate, pero que
no contenga cebolla. No se especifica ningún tipo de dieta, ni tipo de cocina ni
tipo de plato.
Q2: ” I like pizza with ham, cheese and tomato but I don’t want onions”.
Sugerencias: El sistema devuelve algunos tipos de pizza que contienen jamón y
queso. Además de unos macarrones con salsa de tomate, jamón y queso.Third Experiment En este experimento se prueba con una query en la que
se le dice al sistema que se desea algo de fruta, por ejemplo naranjas, limón o
manzana pero que en ningún caso contenga kiwi. No se especifica ningún tipo
de dieta, ni tipo de cocina pero se especifica que el tipo de plato sea una ensalada.
Q2: ” I like to eat some fruit, like orange, lemon and apple but I don’t want
kiwi”.
Sugerencias: El sistema devuelve cinco ensaladas dejando en primer lugar una
ensalada que contiene variedad de frutas: ”Festive Fruit Salad”. Además de otras
ensaladas como ”Ensalada de Naranja”.
6 Conclusion
The final system improve and extends previous versions of JADACook.
Using a web-based interface we bring greater access to the system, with all
the advantages that offers a web-based system, allowing system independence,
the final user can rut everywhere. Web-based interface offers another option
that is web accesibility. Accomplishing the requirements of AA or AAA W3C
makes the system useful for any person although the person has an inability, i.e
blindness.
By using a textual input, we enable a more natural treatment improvement
in the interaction with the final user. We can suggest some future work by
using a system that allows voice recognition that could be connected with our
dependency parser.
JADAWeb extends the possibilities by incorporating a fuzzy table which
allows similarity between two distant elements or types in the ontology, and the
inclusion of various levels in the adaptation algorithm.
It should be noted the great contribution obtained by using WordNet, it
contributes allowing more synonyms for some terms and it extends largely the
knowledge that it has, avoiding the limitation of the use of a finite ontology of
ingredients.
References
1. Herrera, P.J., Iglesias, P., Romero, D., Rubio, I., DÃaz-Agudo, B.: Jadacook: Java
application developed and cooked over ontological knowledge. In Schaaf, M., ed.:
ECCBR Workshops. (2008) 209–218
2. Recio-GarcÃa, J.A., DÃaz-Agudo, B., González-Calero, P.A.: Boosting the perfor-
mance of cbr applications with jcolibri. In: ICTAI, IEEE Computer Society (2009)
276–283
3. Fields, D.K., Kolb, M.A., Bayern, S.: Web Development with Java Server Pages.
Manning Publications Co., Greenwich, CT, USA (2001)
4. Fellbaum, C., ed.: WordNet: an electronic lexical database. MIT Press (1998)
5. Buchholz, S., Marsi, E.: Conll-x shared task on multilingual dependency parsing. In:
Proceedings of the 10th Conference on Computational Natural Language Learning
(CoNLL–X). (2006) 149–1646. Lin, D.: Dependency-based evaluation of minipar. In: Proc. Workshop on the Evaluation of Parsing Systems. Granada (1998)
También puede leer

















































