APUNTES TELEDETECCIÓN ING. TÉC. TOPOGRAFÍA - CURSO 2009/2010 Profesora: Inés Santé Riveira
←
→
Transcripción del contenido de la página
Si su navegador no muestra la página correctamente, lea el contenido de la página a continuación

APUNTES TELEDETECCIÓN
ING. TÉC. TOPOGRAFÍA
CURSO 2009/2010
Profesora: Inés Santé Riveira
1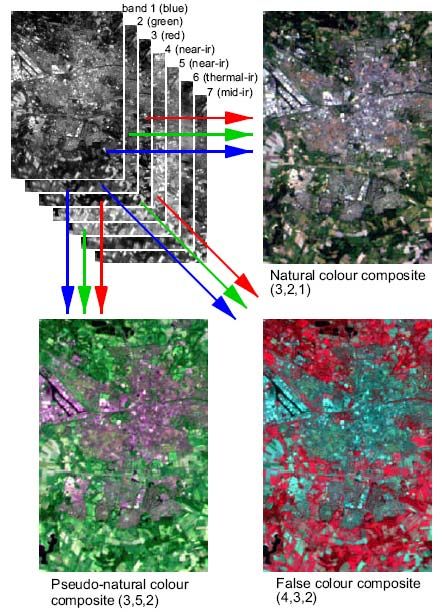
ÍNDICE
TEMA 6: TRATAMIENTOS DE REALCE Y MEJORA BÁSICOS ............................. 3
1. HISTOGRAMA DE UNA IMAGEN .......................................................................... 3
2. AJUSTE DEL CONTRASTE ...................................................................................... 5
3. COMPOSICIONES COLOREADAS ........................................................................ 10
4. EMPLEO DEL SEUDO-COLOR .............................................................................. 13
5. FILTRAJES ................................................................................................................ 14
6. TRANSFORMACIONES PREVIAS. ÍNDICES ....................................................... 16
TEMA 7: TRATAMIENTOS DIGITALES AVANZADOS ......................................... 21
1. ANÁLISIS DE COMPONENTES PRINCIPALES ................................................... 21
2. TRANSFORMACIÓN TASSELED CAP (TTC) ...................................................... 29
TEMA 8: EXTRACCIÓN DE LA INFORMACIÓN .................................................... 33
1. FUNDAMENTOS ...................................................................................................... 33
2. FASE DE ENTRENAMIENTO ................................................................................. 34
3. CLASIFICACIÓN NO SUPERVISADA Y SUPERVISADA .................................. 35
4. MEDIDA DE LA SEPARABILIDAD ENTRE CLASES ......................................... 37
5. FASE DE ASIGNACIÓN .......................................................................................... 38
6. ALGORITMOS DE CLASIFICACIÓN .................................................................... 39
TEMA 9: VERIFICACIÓN DE RESULTADOS .......................................................... 46
1. FUENTES DE ERROR EN LA CLASIFICACIÓN TEMÁTICA ............................ 46
2. MEDIDAS DE FIABILIDAD .................................................................................... 47
3. DISEÑO DEL MUESTREO PARA LA VERIFICACIÓN ....................................... 48
4. RECOGIDA DE INFORMACIÓN ............................................................................ 51
5. MEDIDAS DEL ERROR PARA VARIABLES CONTINUAS................................ 52
6. MEDIDAS DEL ERROR PARA IMÁGENES CLASIFICADAS: MATRIZ DE
CONFUSIÓN ................................................................................................................. 52
7. ANÁLISIS ESTADÍSTICO DE LA MATRIZ DE CONFUSIÓN ............................ 53
TEMA 10: CARACTERÍSTICAS DE LOS SENSORES ACTIVOS: RADAR Y
LIDAR ............................................................................................................................ 57
1. INTRODUCCIÓN ...................................................................................................... 57
2. RADAR DE APERTURA SINTÉTICA (SAR)......................................................... 58
3. BANDAS DEL RADAR ............................................................................................ 59
4. APARIENCIA DE LAS IMÁGENES ...................................................................... 60
5. DISTORSIONES DE UNA IMAGEN RADAR ........................................................ 62
6. PROPIEDADES DE LAS IMÁGENES RADAR ..................................................... 63
7. ECUACIÓN RADAR ................................................................................................ 64
8. TIPOS DE RADARES ............................................................................................... 65
9. LIDAR ........................................................................................................................ 66
TEMA 11: TRATAMIENTOS PROPIOS DE IMÁGENES RADAR .......................... 70
1. REALCE RADIOMÉTRICO ..................................................................................... 70
2. ANÁLISIS DE TEXTURA ........................................................................................ 76
3. TÉCNICAS AVANZADAS ....................................................................................... 83
2
TEMA 6: TRATAMIENTOS DE REALCE Y MEJORA BÁSICOS
En muchas etapas del proceso de elaboración de cartografía a partir de imágenes
satélite es preciso examinar visualmente la imagen. P. ej. para georreferenciarla es
preciso localizar puntos de control claves en la imagen. Es particularmente importante
en el caso de la interpretación visual.
En este tema vamos a ver las técnicas dirigidas hacia la mejora de la calidad
visual de la imagen. Tratan de disponer mejor los datos para su análisis visual, de forma
que sean más evidentes los rangos de interés de la imagen. En estas técnicas se incluyen
los procesos de mejora del contraste, composiciones coloreadas y filtrajes.
1. HISTOGRAMA DE UNA IMAGEN
Una imagen está definida por su histograma, en el que se representa la
probabilidad de encontrar un determinado valor de ND en la imagen. El histograma de
una imagen describe la distribución de los valores de los píxeles (los ND) de la imagen.
Un histograma indica el número de píxels para cada valor, en otras palabras, el
histograma contiene las frecuencias de los valores de ND en una imagen. El histograma
puede representarse en forma tabular o gráficamente. La representación tabular
normalmente consta de 5 columnas:
ND: nivel digital, en el rango [0…255]
- Npix: número de píxeles de la imagen con este ND (frecuencia)
- Perc: frecuencia como porcentaje del número total de píxeles de la imagen.
- CumNpix: número acumulado de píxeles en la imagen con valores menores o
iguales a ese ND.
- CumPerc: frecuencia acumulada como porcentaje del número total de píxeles de
la imagen.
Los datos del histograma pueden ser posteriormente resumidos mediante algunas
estadísticas como: media, desviación estándar, mínimo y máximo, valor 1% que es
valor por debajo del cual sólo se encuentran el 1% de los valores, valor 99%. Los
valores 1% y 99% pueden ser usados para definir un rango óptimo para la visualización.
Ejemplo de histograma en forma tabular:
3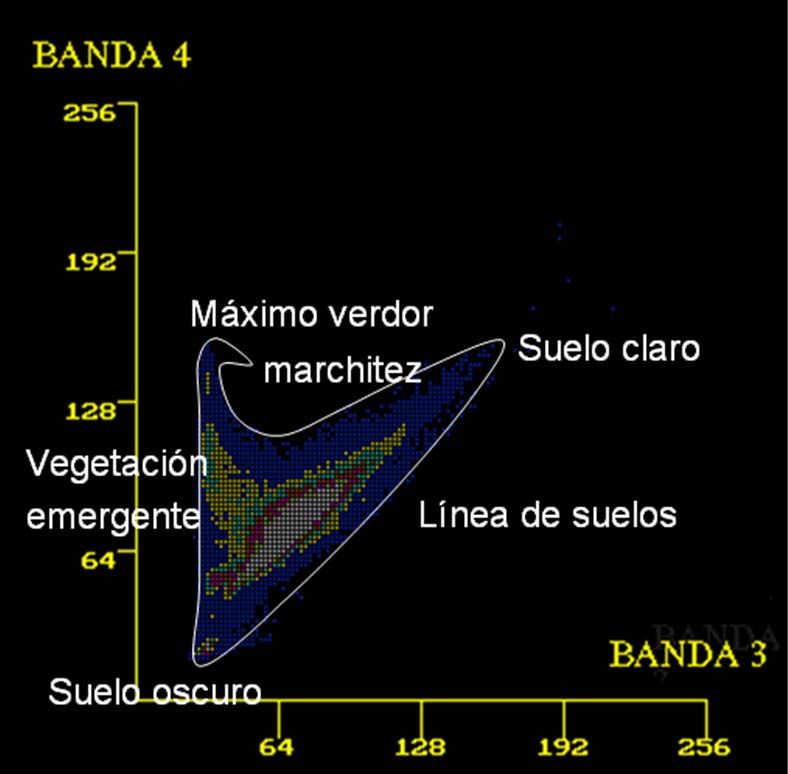
La representación gráfica muestra la curva de frecuencia acumulada, que
representa el porcentaje de píxeles con un ND igual o menor a un determinado valor.
4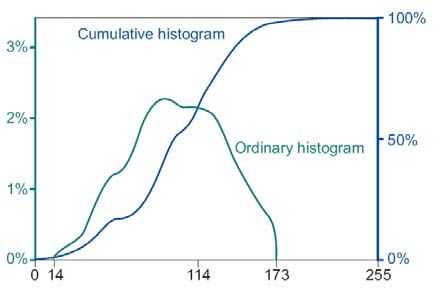
2. AJUSTE DEL CONTRASTE
Los sensores son calibrados para recibir un rango muy amplio de valores de
radiación. Sin embargo, en una imagen satélite puede haber sólo agua, vegetación, etc,
por lo que rango de valores de la imagen será mucho menor, habrá poca diferencia entre
el ND mínimo y el máximo. Con el realce radiométrico se busca un mayor contraste
visual.
El ajuste del contraste es un proceso que hace más fácilmente apreciables las
características de una imagen haciendo un uso óptimo de los colores disponibles para su
visualización.
Las imágenes son visualizadas normalmente usando una escala de grises. Los
grados de gris del monitor típicamente varían del negro (valor 0) al blanco (valor 255).
Si se usan los valores originales de la imagen para controlar los valores de grises del
monitor, normalmente resulta en una imagen con poco contraste porque sólo se usa un
número de valores de grises limitado. En la imagen del histograma anterior, solamente
sería usados 173-14=159 niveles de grises de los 255 disponibles. El rango de ND de la
imagen no coincide con el número de valores disponibles, por lo que se puede expandir
el contraste para hacer corresponder el rango de ND presentes en la imagen con el rango
de ND total disponible. Para optimizar el rango de valores de grises, una función de
transferencia convierte los valores de ND en niveles de grises del monitor. Esta función
5de transferencia puede ser de distintas formas. Las funciones de transferencia son
implementadas como modificaciones de los valores de la colour look up table.
Tablas de referencia del color
La tabla de referencia del color (CLUT, Colour Look up Table) indica el nivel
visual, NV o nivel de gris, con el que se representa en la pantalla cada ND. En la mayor
parte de los equipos la tabla de color es una matriz numérica de 3 columnas por 256
filas (ya que el rango de codificación va de 0 a 255). De modo que el orden de la fila
indica de ND de entrada, y en la tabla se almacena el NV con el que se representará ese
ND, las tres columnas de la matriz corresponden a los 3 colores elementales. En el caso
de que se esté trabajando con una sola banda, lo normal es que la imagen se represente
en pantalla en tonos de grises. Esto significa que cada ND tiene el mismo componente
de rojo, verde y azul. Un NV de 0,0,0 indica que el ND al que se aplique será
visualizado como negro, mientras que 127, 127, 127, supone un gris medio y 255,255,
255 blanco. Si los tres valores son distintos se estará representando una imagen en
color.
NV (azul) NV (verde) NV (rojo)
0 0 0
1 1 1
2 2 2
3 3 3
… … …
127 127 127
… … …
255 255 255
Gracias a la CLUT no es preciso transformar los ND para modificar el contraste
visual de la imagen, lo que conllevaría perder la información original o aumentar las
necesidades de almacenamiento. Basta únicamente transformar la relación entre ND y
NV que incluye la CLUT.
Una forma alternativa de visualizar una imagen es usar una pseudo-colour
lookup table que asigna colores entre el azul via ciano, verde y amarillo al rojo. El uso
de pseudo-color es especialmente útil para visualizar datos que no son medidas de
reflexión, p ej, datos de infrarrojo térmico, la asociación de frío-caliente con azul-rojo es
más intuitiva que con oscuro-claro.
6Expansión y comprensión del contraste
Pueden darse dos situaciones: 1) que el rango de ND de la imagen sea menor que
el de NV del monitor, 2) que la imagen presente un mayor número de ND que NV
posibles en el monitor. En el primer caso se deberá aplicar una expansión del contraste,
mientras que en el segundo una reducción del mismo. La expansión del contraste se
emplea rutinariamente en la mayor parte de las aplicaciones. Mientras que la
compresión del contraste, es está empleando para reducir el volumen de
almacenamiento de las imágenes y aprovechar los equipos de visualización de bajo
coste.
Expansión del contraste
El primer caso, la expansión del contraste, es el más habitual, ya que aunque la
resolución radiométrica de la mayor parte de los sensores actuales es de 8 bits por píxel,
en la práctica ninguna imagen aprovecha todo ese rango, ya que difícilmente en una sola
escena se encontrarán todos los posibles valores de radiancia para los que se calibró el
sensor. Visualmente esto implica que hay tonos de gris que no se utilizan, por lo que la
imagen se ve en el monitor con poco contraste. Es posible realzar el contraste diseñando
una tabla de color que haga corresponder el rango de ND presentes en la imagen con el
rango total de NV posibles. Si bien existe la posibilidad de realizar expansiones de
contraste de forma manual, las formas más habituales para realizar la expansión del
contraste son:
Expansión lineal del contraste
Es la forma más elemental de ajustar el contraste. El valor digital ND mínimo
del histograma se hace corresponder con el NV 0 (es el negro) y el máximo con el NV
255 (es el blanco), de modo que ocupe todo el rango de valores disponibles,
distribuyendo linealmente el resto de ND entre estos extremos mediante la siguiente
ecuación
ND ND min
NV 255
ND max ND min
De este modo se utiliza todo el rango de NV del monitor o dispositivo de salida.
En lugar de utilizar el ND mínimo y máximo también se pueden utilizar otros valores
menos extremos, como los percentiles del 95% y 5% o el 1 y el 99%, lo que permite que
tengan menos influencia los posibles valores anómalos de la imagen.
7Expansión lineal restringida – los valores de NDmax y NDmin los decide el usuario en
lugar de corresponder a los valores reales de la imagen
ND ND min
Si NDmax>ND>NDmin NV 255
ND max ND min
Si NDmaxND NV=0
Ecualización del histograma
Igual que en el caso anterior, se asigna al ND mínimo el NV 0 y al ND máximo
el NV 255, pero distribuyendo el resto de ND según una función cuadrática. En la
expansión lineal no se tiene en cuenta la frecuencia de los ND, aquí sí, se tiene más
realce en los ND más frecuentes. Se tiene en cuenta la forma del histograma, la
distribución real de los valores, es decir, no sólo se tiene en cuenta el valor de ND sino
que se aplica una expansión proporcional a la frecuencia de aparición de cada uno de los
ND. Esto implica crear una tabla de referencia de color en la cual cada NV tenga,
aproximadamente, el mismo número de ND de la imagen. Es decir, aquellos ND con
mayor número de píxeles serán los que ocupen un mayor rango de visualización.
El proceso es más laborioso que en el caso anterior.
1. Se calcula la frecuencia absoluta y acumulada de los ND de la imagen original.
2. Esta frecuencia se compara con una frecuencia objeto, que sería la que se
obtendría si todos los NV de la imagen tuvieran la misma frecuencia (es decir,
el cociente entre el número total de píxeles de la imagen y el número de niveles
visuales posibles). P ej, 736136píxeles/256NV=2875,53píxeles por cada NV, en
frecuencia relativa el 0,3906%.
3. De esta comparación se selecciona, para cada ND, el NV que presente un valor
más próximo en la frecuencia objeto acumulada.
Ajuste gaussiano
Supone el ajuste del histograma observado al histograma que aparecería si la
distribución fuera gaussiana, es decir si:
1 (x ) 2
f ( x) exp
2 2
2
f(x) es la frecuencia de x, es la media y la desviación típica.
8Expansión especial del contraste
Se realza aquella zona de la imagen que más interesa. Se restringe el contraste a
un rango específico de ND, en donde se manifieste con mayor claridad una cubierta de
interés. La expansión especial puede realizarse asignado como umbral mínimo y
máximo el rango de ND de la cubierta que pretende realzarse (es el método lineal), o
limitando el histograma objeto al rango donde está presente dicha cubierta (es el realce
frecuencial).
Expansión adaptada del contraste
Es semejante a la ecualización pero resulta una imagen menos contrastada
porque se realzan más los extremos del histograma.
Infrecuencia
Consiste en asociar al ND menos frecuente el nivel de gris más alto y viceversa.
Imagen de Landsat TM sin mejora del contraste, con ecualización del histograma y
representación pseudo-color.
Comprensión del contraste
En el caso de que el rango del sensor supere el número de niveles de gris que
pueden visualizarse en pantalla, es necesario comprimir los ND originales. Este ajuste
es necesario en dos casos: 1) cuando se cuenta con un sistema gráfico de potencia
reducida, o 2) cuando se trabaja con un sensor de gran sensibilidad radiométrica (p. ej.
de 10 bits de AVHHRR, de 11 bits del Ikonos o de 16 bits de SAR).
9Este problema se puede solucionar de dos formas: eliminando una parte de la
escala que no se considere relevante, o estableciendo una función de compresión de
datos. La primera solución es poco habitual porque supone una eliminación arbitraria de
datos. La segunda puede abordarse de distintas formas.
La forma más habitual es reducir el rango original de ND a un número
conveniente de intervalos. Estos intervalos suelen señalarse en función de las
características de la distribución de los ND. Pueden utilizarse intervalos de igual
anchura, a cada uno de los cuales se asigna un único NV.
Existen algoritmos de compresión más elaborados, que controlan el número de
intervalos mediante un proceso similar a la clasificación no supervisada.
Actualmente, la mayor parte de los equipos cuentan con tarjetas gráficas de
mucha mayor potencia, por lo que la comprensión de imágenes no se suele realizar,
salvo por problemas de almacenamiento. Además, en este caso se suelen utilizar
algoritmos de compresión del color, que consiguen una calidad apenas diferenciable de
la original, por ejemplo el algoritmo LZW, que permite crear imágenes GIF, el JPEG o
el PNG.
3. COMPOSICIONES COLOREADAS
Percepción del color
La percepción del color tiene lugar en el ojo humano y en la parte asociada del
cerebro. No sé sabe exactamente cómo funciona la visión humana y qué sucede en los
ojos y el cerebro antes de que alguien decida que un objeto es azul. Sin embargo,
algunos modelos teóricos, soportados por resultados experimentales, son generalmente
aceptados. El ojo es sensible a longitudes de onda entre 400 y 700 nm. Diferentes
longitudes de onda en este rango son percibidas como colores distintos. La retina del
ojo tiene conos (receptores sensibles a la luz) que envían señales al cerebro cuando son
golpeados por fotones con niveles de energía que corresponden a las diferentes
longitudes de onda en el rango visible del espectro electromagnético. Hay tres clases
diferentes de conos, respondiendo al azul, verde y rojo. Las señales enviadas a nuestro
cerebro por estos conos, y las diferencias entre ellos, nos dan sensaciones de color.
Los equipos de visualización utilizan el proceso aditivo de formación del color,
basado en la mezcla por adición de los colores primarios. Una pantalla de televisión está
compuesta por un gran número de pequeños puntos compuestos por grupos de puntos
10rojos, verdes y azules. El número de puntos encendidos determina la cantidad de luz
roja, verde y azul emitida. Todos los colores pueden ser creados mezclando diferentes
cantidades de rojo, verde y azul. Esta mezcla tiene lugar en nuestro cerebro. Cuando
vemos luz amarilla monocromática, que tiene una longitud de onda de 570nm, tenemos
la misma impresión que cuando vemos una mezcla de rojo, 700 nm, y verde, 530nm. En
ambos casos, los conos son estimulados de la misma forma, de acuerdo con el modelo
de tres-estimulos.
Composiciones coloreadas
Si tenemos en cuenta que el ojo humano es menos sensible a las tonalidades de
color gris que al cromatismo, la composición coloreada es quizás la técnica más
utilizada para resaltar los detalles de una imagen de satélite. Consiste en aplicar a tres
bandas diferentes los distintos colores elementales (rojo, verde, azul), de modo que se
puede apreciar información no distinguible de otro modo. Este proceso permite
visualizar, simultáneamente, información de distintas regiones del espectro, lo que
facilita la delimitación visual de algunas cubiertas.
La composición de color más obvia sería simular el color real asignando a la
banda del rojo el color rojo, a la del azul el azul y a la del verde el verde. Cuando se
aplica cada color a la banda del espectro que le corresponde se obtienen composiciones
en color verdadero. Sin embargo, no se suele aplicar a cada banda su color respectivo
por lo que se denominan composiciones de falso color.
La composición más habitual es la denominada color infrarrojo,
correspondiente a la aplicación de los colores rojo, verde y azul a las bandas del
infrarrojo cercano, rojo y verde respectivamente. El resultado es similar a la fotografía
infrarroja. Esta composición facilita la cartografía de masas vegetales, láminas de agua,
ciudades, etc, de ahí que se haya empleado ampliamente en diversos estudios de análisis
visual. La característica más peculiar de esta composición en falso color es que la
vegetación aparece de un color rojo púrpura. En la parte visible del espectro las plantas
reflejan la mayor parte de la luz verde pero su reflexión infrarroja es incluso mayor. Por
lo tanto, la vegetación en una composición en falso color aparece con una mezcla de
algo de azul, pero más rojo, resultando en un color rojizo púrpura.
Las combinaciones que visualizan el infrarrojo cercano como verde muestran la
vegetación de color verde, por eso se llaman composiciones en color pseudo-natural.
Dependiendo de la aplicación se pueden usar otras combinaciones de bandas. En
definitiva, estas composiciones sirven para resaltar los elementos que mayor
11reflectividad presentan en las bandas utilizadas, además de obtener visualizaciones más
o menos estéticas. La elección de las bandas para realizar la composición, y el orden de
los colores destinados a cada una, dependen del sensor sobre el que se trabaje y de la
aplicación a la que se destine. Por ejemplo, para el sensor TM de Landsat se utilizan las
siguientes composiciones:
3/2/1 - información en color real
5/4/3 o 4/5/3 aplicándoles RGB – para estudios de usos del suelo, se ha utilizado en el
proyecto europeo Corine, en el que se obtuvo el mapa de suelos para toda Europa
4/7/5 – es utilizada para el seguimiento de zonas quemadas
7/4/3 – se emplea para el estudio de cultivos en regadío
7/3/1 – tiene aplicaciones oceanográficas
La elección de las bandas depende del sensor con el que se trabaje. En general
deben seleccionarse las bandas que presenten la mayor varianza, es decir, aquellas en
las que la dispersión de los datos sea la mayor posible, y el mínimo coeficiente de
correlación entre ellas, es decir, que la información proporcionada por cada una de las
bandas sea lo más independiente posible de las informaciones proporcionadas por las
restantes. Para establecer un criterio objetivo para seleccionar las bandas más adecuadas
para una composición de color se han propuesto unos índices estadísticos, como el
denominado ‘índice óptimo’ o Optimum Index Factor, OIF:
s k
OIF k 1,3
r
j 1,3
j
donde Sk es la desviación típica de cada una de las 3 bandas y rj es el coeficiente de
correlación entre cada par de esas bandas. Cuanto más alto sea este índice mayor será el
contenido informativo de la composición.
124. EMPLEO DEL SEUDO‐COLOR
Se ha demostrado que el ojo humano distingue mejor distintos tonos de color
que intensidades de brillo o niveles de grises, por lo que, el empleo de color puede
ayudar a interpretar una imagen, incluso si sólo se dispone de una banda. En este caso,
no se puede hablar propiamente de color, pues se requerirían 3 bandas, sino más bien de
seudo-color.
Para una mezcla de 3 bandas utilizamos distintos NV en cada cañón de color,
RVA. Sin embargo, también se puede diseñar una CLUT en donde varíen los NV para
los 3 colores aunque sólo haya una banda de entrada. Es decir, el pseudo-color implica
crear una CLUT que asocie el ND de una sola banda a distintos componentes de rojo,
verde y azul. Esto tiene sentido en 2 casos:
1 – Cuando se quiere obtener una clave de color en una imagen clasificada (cada color
una categoría). Cada ND indica una clase temática distinta (p ej un uso del suelo), que
será visualizada con un color distinto.
2 – Cuando se intente realzar el análisis de una determinada banda sustituyendo los
niveles de gris por tonos de color. P. ej., se puede diseñar una CLUT con tonos azules
para los ND bajos y rojos para los ND altos. Esto se aplica por ejemplo para la
visualización de imágenes de temperaturas (azul-rojo) o de índices de vegetación (color
ocre-verde).
135. FILTRAJES
Otro componente de la imagen es el contraste espacial, que es la diferencia
entre el ND de un píxel y el de sus vecinos. Mediante las técnicas de filtraje se pretende
suavizar o reforzar estos contraste espaciales. Se filtra la imagen para suavizar o
reforzar los contrastes espaciales, es decir, para difuminarla o para resaltar determinados
aspectos, de modo que el ND de un píxel se diferencie o se asemeje más a los ND de los
píxeles que lo rodean.
Los filtros son transformaciones locales de la imagen: se calcula una nueva
imagen y el valor de un píxel dependerá de los valores de sus vecinos. El filtraje sí
implica modificar los ND originales y no sólo la forma en que se representan
visualmente. Los filtros consisten en aplicar a los ND de cada píxel una operación
aritmética que tenga en cuenta el valor de los píxeles próximos, estos son los filtros en
el dominio espacial.
Los filtros consisten en aplicar una matriz móvil de coeficientes de filtraje (CF)
(también se llama kernel), con un número impar de filas y columnas, sobre los ND de
los píxeles. Un filtro puede ser considerado como una ventana que se mueve a lo largo
de una imagen y considera todos los ND que caen dentro de la ventana. Cada valor de
un píxel es multiplicado por el coeficiente correspondiente del filtro. El valor resultante
sustituye al valor original del píxel central. La ventana se desplaza un píxel. Esta
operación se llama convolución. Cuanto mayor es el tamaño de la matriz mayor es el
efecto de suavizado o de realce del filtro.
El resultado de un filtro depende de los CF. Si estos tienden a ponderar el valor
central en detrimento de los circundantes, el píxel refuerza sus diferencias frente a los
vecinos (son los filtros de paso alto). Por el contrario, si los coeficientes favorecen a los
píxeles periféricos, el central se asemejará más a los adyacentes (son los filtros de paso
bajo). Por lo tanto, hay dos tipos de filtro:
a) Filtros de paso bajo
Difuminan la imagen, la suavizan, los contornos se hacen menos nítidos. Se
asemeja el ND de cada píxel al de los píxeles vecinos. Destacan el componente de
homogeneidad en la imagen. Estos filtros se emplean para eliminar errores aleatorios
que pueden presentarse en los ND de la imagen, también para reducir la variabilidad
espacial de algunas categorías como paso previo a la clasificación. En ambos casos, se
14pretende atenuar el denominado ‘ruido de la escena’. El filtro de paso bajo puede
obtenerse a partir de diversas matrices de filtraje, algunas de las más habituales son:
1 1 1 1 1 1 0,25 0,5 0,25
1 1 1 1 2 1 0,5 1 0,5
1 1 1 1 1 1 0,25 0,5 0,25
El filtro media suaviza la imagen para eliminar el ruido, calcular la suma de
todos los píxeles del kernel y luego divide la suma por el número total de píxeles del
kernel.
En los últimos años se ha aplicado otro tipo de filtraje, basado en la mediana en
lugar de la media. El filtro mediano consiste en sustituir el ND del píxel central por la
mediana de los ND de los píxeles vecinos. La mediana es menos sensible a valores
extremos. Este filtro preserva mejor los contornos que el filtro promedio, pero resulta
más complejo de calcular ya que hay que ordenar los valores de los píxeles de la
ventana y determinar cuál es el valor central. Tiene la ventaja de que el valor final del
píxel es un valor real presente en la imagen y no un promedio, de este modo se reduce el
efecto borroso que tienen las imágenes que han sufrido un filtro de media.
La mediana es el valor medio en un conjunto ordenado.
El filtro moda calcula la moda de los valores, es decir, el valor más frecuente del
kernel.
El problema de los filtros de paso bajo es hacerlos sin que se pierdan entidades
interesantes.
b) Filtros de paso alto
Resaltan los bordes, los contornos de las áreas homogéneas. Desatacan los ND
que sobresalen entre los valores más comunes. Destacan las áreas de alta variabilidad.
Se remarcan los elementos lineales de las fronteras con respecto a los vecinos, se usan
más.
El filtro de paso alto más sencillo consiste en restar a la imagen original la
obtenida por un filtro de paso bajo. Aunque es más común emplear matrices de filtraje,
similares a las anteriores, pero en las que se refuerza más el contraste entre el píxel
central y los vecinos. Estos filtros calculan la diferencia entre el píxel central y sus
vecinos. Esto es implementado usando valores negativos para los coeficientes de los
píxeles no centrales. Por ejemplo las siguientes matrices:
15-1 -1 -1 0 -1 0 -1 -1 -1
-1 9 -1 -1 4 -1 -1 16 -1
-1 -1 -1 0 -1 0 -1 -1 -1
Filtro de paso alto – Imagen original – Filtro de paso bajo
6. TRANSFORMACIONES PREVIAS. ÍNDICES
Estas transformaciones previas consisten en operar la imagen con un valor
numérico: sumar, restar, multiplicar o dividir píxel a píxel varias imágenes. La
transformación previa más común son los cocientes o ratios entre dos o más bandas de
la misma imagen, que se utilizan ampliamente en dos situaciones:
1. Para mejorar la discriminación entre dos cubiertas con comportamiento
reflectivo muy distinto en dos bandas
2. Para reducir el efecto del relieve
Estos índices se emplean principalmente para mejorar la discriminación de las
cubiertas vegetales y estimar algunas de sus variables biofísicas. Un índice de
vegetación es un “parámetro calculado a partir de los valores de la reflectividad a
distintas longitudes de onda y que pretende extraer de los mismos la información
relacionada con la vegetación minimizando la influencia de perturbaciones como las
debidas al suelo y a las condiciones atmosféricas”. Los índices de vegetación definidos
hasta el momento tienen en común el uso de los valores de reflectividad en la banda del
rojo y del infrarrojo cercano, debido al diferente comportamiento de la vegetación verde
y el suelo en estas bandas.
La vegetación verde apenas refleja radiación en el rango visible porque los
pigmentos de la hoja la absorben. Sin embargo estas sustancias no afectan al infrarrojo
16cercano. Por eso se produce un notable contraste espectral entre la baja reflectividad de
la banda R (roja del espectro) y la banda del IR cercano, lo que permite separar, con
relativa claridad, la vegetación sana de otras cubiertas. Cuando la vegetación sufre algún
tipo de estrés (p ej por plagas o sequías) su reflectividad en el IR cercano es menor, y
paralelamente aumenta en el rojo, por lo que el contraste entre ambas bandas será
mucho menor. En definitiva, cuanto mayor sea la diferencia entre las reflectividades
de la banda del IRC y el rojo, mayor vigor vegetal presentará la cubierta. Bajos
contrastes indican una vegetación enferma o con poca densidad, hasta llegar a los suelos
descubiertos o al agua, que presentan muy poco contraste entre el IRC y el rojo. En este
principio se apoyan la mayor parte de los índices de vegetación (IV). Durante los
últimos 20 años se han publicado cerca de 40 IVs. Los más empleados son el cociente
simple entre esas bandas (C), el denominado índice normalizado de vegetación (NDVI,
Normalizad Difference Vegetation Index)
i ,IRC
Ci
i ,R
i ,IRC i ,R
NDVI i
i ,IRC i ,R
i,IRC y i,R son las reflectividades del píxel i en la banda del infrarrojo cercano y del
rojo respectivamente.
El NDVI varía entre unos márgenes conocidos, entre -1 y +1, lo que facilita su
interpretación. Pudiendo establecerse como límite para las cubiertas vegetales un valor
de 0,1 y para la vegetación densa entre 0,5 y 0,7. Cualquier valor negativo implica la
ausencia de vegetación.
Aunque estos índices se refieren a reflectividades muchos autores emplean
directamente los ND de la imagen, ya que se sigue manteniendo el hecho de que cuanto
mayor sea el resultado mayor vigor vegetal presenta la zona observada. Sin embargo,
según algunos estudios el cálculo de este índice a partir de ND subestima entre 0,05 y
0,2 el valor calculado con reflectividades. Por lo que parece necesario una formulación
alternativa para corregir este error sistemático:
NDir 0,801NDr
NDVI
NDir 0,801NDr
La ventaja y el inconveniente del índice de vegetación es que no responde a una
variable concreta sino a un conjunto de factores (cobertura, estado fenológico, estado
17fitosanitario). Por tanto, no resulta sencillo utilizarla para estudiar aspectos específicos
de la vegetación pero aporta una idea de conjunto acerca de su estado. Entre las
variables que se han correlacionado con los índices de vegetación están; índice de área
foliar, contenido de agua de la hoja, flujo neto de CO2, radiación fotosintéticamente
activa absorbida por la planta, productividad neta de la vegetación, cantidad de lluvia
recibida por la vegetación, dinámica fenológica, evapotranspiración potencial.
Se han propuesto distintas variantes para mejorar este índice. Algunos autores
afirman que la influencia relativa de los efectos atmosféricos es minimizada más
efectivamente mediante combinaciones de bandas no lineales, por lo que proponen el
Global Environment Vegetation Index (GEMI), calculado como:
R 0.125
GEMI (1 0.25 )
1 R
2( IR 2 R 2 ) 1.5 IR 0.5 R
IR R 0.5
Además, un índice de vegetación ideal debe ser sensible a la parte verde de la
planta pero no al suelo. Por lo tanto, el objetivo fundamental es eliminar la influencia
que el suelo puede tener sobre las reflectividades en el rojo y el infrarrojo y que pueda
enmascarar las de la vegetación (lo que resulta espacialmente útil en medios
semiáridos). Para minimizar el efecto del suelo se utilizan los índices de vegetación
basados en el concepto de línea de suelos.
El principal factor que afecta a la reflexión del suelo es el contenido en
humedad. Sin embargo la influencia de la humedad es igual a lo largo del espectro, es
igual en todas las bandas. Por lo tanto, el ratio entre bandas espectrales, por ejemplo
entre las bandas Rojo e IR no depende de la humedad del suelo, por lo que es posible
definir el concepto ‘línea de suelo’, que es una línea que representa la relación entre las
reflexiones del suelo en el Rojo y el IR. La línea de suelos caracteriza el tipo de suelo y
es calculada por el método de regresión lineal y expresada así:
IR,suelo=a*R,suelo + b,
a y b – parámetros estimados mediante mínimos cuadrados, a es la pendiente y b el
origen de la recta.
18Perpendicular Vegetation Index (PVI)
PVI ( R , suelo R ,veg ) 2 ( IR ,suelo IR ,veg ) 2
Sustituyendo aquí la ecuación de la línea de suelos:
IR ,veg a R ,veg b
PVI a,b – parámetros de la línea de suelo
1 a 2
PVI=0 suelo desnudo
PVI 0 vegetación
Como PVI no depende de la humedad del suelo, es menos variable de un suelo a otro.
Soil-Adjusted Vegetation Index (SAVI)
( IR R )
SAVI (1 l )
( IR R l )
Normaliza mejor la influencia del suelo que los índices anteriores. La principal
desventaja es la determinación del parámetro l. El autor recomienda tomar un valor l=1
para densidades de vegetación bajas, 0.5 para valores intermedios y 0.25 para alta
densidad, por lo que se requiere información a priori.
Este índice fue mejorado dando lugar al Transformed Soil Adjusted
Vegetation Index (TSAVI):
a ( IR ,veg a R ,veg b)
TSAVI
R ,veg a IR,veg abX (1 a 2 )
X=0.08
TSAVI=0 suelo desnudo
LAI (Leaf area index - índice de superficie de hoja: superficie de hoja por unidad de
superficie de suelo) alto TSAVI proximo a 0.7.
Otras mejoras del SAVI son:
19Modified SAVI (MSAVI)
2 IR l (2 l ) 2 8( IR R )
MSAVI
2
Optimizad SAVI (OSAVI)
IR R
OSAVI
IR E Y
En diferentes estudios se ha demostrado que estos índices presentan resultados
diferentes dependiendo de las condiciones. Por lo tanto, el mejor índice de vegetación
dependerá del tipo de sensor y de las características de la zona.
Los índices se pueden utilizar en 3 tipos de operaciones:
- Comparación temporal de diferentes fuentes (imágenes tomadas en diferentes
fechas o desde dos satélites diferentes)
- Integración en un proceso de clasificación. Debido a su poder discriminatorio
los índices constituyen una fuente de información para delimitar con más
precisión los contenidos de la clasificación.
- Integración en un proceso de visualización. La calidad visual que aporta el
nuevo canal generado por el cálculo del índice puede usarse también en una
síntesis de canales como es la composición coloreada.
20TEMA 7: TRATAMIENTOS DIGITALES AVANZADOS
1. ANÁLISIS DE COMPONENTES PRINCIPALES
Consiste en la creación de unos canales artificiales a partir de los originales, que
contengan el máximo contenido en información, es decir, que tengan una correlación
mínima y una varianza máxima.
Su objetivo es resumir la información contenida en un grupo amplio de
variables en un nuevo conjunto, más pequeño, sin perder una parte significativa de esa
información. Por lo tanto, los factores o componentes principales vendrían a ser como
variables-resumen de las medidas iniciales, preservando lo más sustancioso de la
información original.
Esta capacidad de síntesis es interesante en teledetección porque la adquisición
de imágenes en bandas adyacentes del espectro, implica con frecuencia detectar
información redundante, puesto que las cubiertas suelen presentar un comportamiento
similar en longitudes de onda próximas. Por ello, las medidas realizadas en una banda
pueden presentar una importante correlación con las realizadas en otra banda. El ACP
permite sintetizar las bandas originales, creando unas nuevas bandas, los componentes
principales de la imagen, que recojan la parte más relevante de la información original.
Esta selección de bandas no correlacionadas resulta muy conveniente cuando se está
realizando un estudio multitemporal o cuando se intentan seleccionar las 3 bandas más
adecuadas para una composición de color.
El sentido y la fuerza de la correlación lineal entre dos variables puede
representarse mediante dos ejes, en cada uno de los cuales se representa una variable. Si
los datos de ambas bandas tienen una distribución normal el resultado es una elipse. La
elipse que limita la nube de puntos indica el grado de correlación, de modo que la
correlación será tanto mayor cuanto más se aproxime esta elipse a una recta. En el
contexto de la teledetección la nube de puntos indica la localización de los ND en las
dos bandas consideradas.
21El eje mayor de la elipse es el primer componente principal de los datos. La
dirección del primer componente principal es el primer eigenvector y la longitud es el
primer eigenvalor. Como el primer componente principal muestra la dirección y
longitud del eje mayor de la elipse es el que mide la mayor variación dentro de los
datos.
El segundo componente principal es el ortogonal al primer componente
principal, en una análisis en 2D es el eje menor de la elipse. Describe la varianza de los
datos que no es descrita por el primer componente principal. Y así sucesivamente: cada
componente principal es el mayor eje de la elipse que es perpendicular al componente
principal anterior y representa la variación de los datos que no está incluida en los
componentes principales anteriores.
Gráficamente se ve que una rotación de los ejes X, Y hacia las direcciones de A
y B mejorará la disposición original de los datos y, probablemente también la
separación entre grupos de ND homogéneos. Esta rotación se obtiene aplicando una
función del tipo
CP1 = a11NDi + a12NDk
CP es el primer componente principal obtenido a partir de los ND de las bandas i y k
tras aplicar los coeficientes a11 y a12. Desde el punto de vista geométrico, como puede
verse en la figura, este nuevo eje sólo supone una rotación de los originales. En
ocasiones, puede ser de gran interés acompañar la rotación con una traslación de los
ejes, situando el origen de coordenadas de los ejes en los valores mínimos de las dos
22bandas, es decir, una traslación, para ello se le suma a la ecuación anterior dos
constantes a01 y a02.
Para un número p de bandas la ecuación a aplicar será esta
CPj=i=1,paijNDi + Rj
CP es el componente principal j, aij es el coeficiente aplicado al ND de la banda i para
generar el componente j, Rj es una constante que suele introducirse para evitar valores
negativos.
La obtención de los CP implica una transformación matemática compleja.
Algebraicamente el ACP genera nuevos componentes mediante una combinación lineal
de las p variables o bandas originales.
En primer lugar, para realizar el ACP se utiliza una matriz bidimensional, donde
n son los píxeles de una imagen y p son las bandas de la imagen
La i-ésima fila de la matriz contiene los n niveles digitales de la i-ésima banda
1. Con la matriz de varianza-covarianza x
en la que los elementos de la diagonal son las varianzas de los N.D. en cada banda:
n n
n x ik2 ( x ik )2
ii k 1 k 1
n ( n 1)
y los elementos fuera de la diagonal son las covarianzas entre los N.D. de dos bandas:
Como la covarianza entre la banda i y la j es la misma que entre la banda j y la i
(sij = sji) la matriz Sx es simétrica. Cuando hay relación lineal entre los N.D. de dos
23bandas las covarianzas son grandes en comparación con las varianzas, por eso es que
esta matriz sirve para estudiar la relación entre pares de bandas.
A partir de la matriz de varianza-covarianza de las bandas que componen la
imagen original, se extraen los autovalores (). Los autovalores están dados por la
solución de la ecuación . Los autovalores expresan la longitud de cada uno
de los nuevos componentes, y, en última instancia, la proporción de información
original que retiene el componente principal asociado. Este dato resulta de gran interés
para decidir qué componentes principales son más interesantes; es decir, los que mayor
información original retengan.
Tal y como se obtienen los CP, el autovalor va disminuyendo progresivamente,
del primero a los últimos, pues se pretende maximizar sucesivamente la varianza
extraída en el análisis. La varianza original explicada por cada componente se calcula
como la proporción de su autovalor frente a la suma de todos los autovalores:
j
Vj
j
j 1, p
siendo p el número total de componentes.
A partir de los autovalores se pueden calcular los autovectores mediante la
siguiente expresión
x a1 1a1
Además de la longitud de cada eje, que nos proporcionaban los autovalores,
resulta también de gran interés conocer su dirección. Además, para calcular las
ecuaciones anteriores se precisa contar con los coeficientes de la transformación.
Ambos aspectos se pueden conocer a partir de los autovectores. El autovector indica la
ponderación que debe aplicarse a cada una de las bandas originales para obtener el
nuevo CP. Es decir, equivale a los coeficientes de regresión de una transformación
lineal estándar, siendo las bandas de la imagen las variables independientes y los CP las
dependientes. Una vez que conocemos los autovectores, el último paso es obtener una
imagen de los componentes principales, a partir de una combinación lineal de las bandas
originales.
CPj=i=1,paijNDi + Rj
Un módulo de ACP de un programa deberá proporcionar:
- Los mapas de valores de los componentes
24- Los auto-valores para determinar el porcentaje de varianza explicada por cada
componente
- La matriz de auto-vectores que permitirá determinar cuál es el peso de cada
variable (banda) en cada componente.
Ejemplo 1
Suponga que los N.D. de 6 píxeles en 2 bandas son:
Banda 1 2 4 5 5 3 2
Banda 2 2 3 4 5 4 3
El sentido y la fuerza de la correlación lineal entre dos bandas puede representarse
gráficamente mediante un diagrama de dispersión. Cuanto más se aproximan los puntos
a una recta mayor será el grado de correlación entre bandas.
Para este ejemplo
La matriz de varianza-covarianza de los datos es
Para determinar los componentes principales es necesario encontrar los autovalores y
autovectores de SX. Los autovalores están dados por la solución de la
ecuación , es decir ó equivalentemente
, es decir , que da por resultados
1=2.67 y 2=0.33.
Los autovectores se calculan mediante la expresión
25 x a1 1a1
1.9 1.1 a11 a11
2,67
1.1 1.1 a12 a12
0,77a11-1,1a12=0
1,57a12-1,1a11=0
Como, además, los autovectores deben estar normalizados a11 a12 1 . Esta
2 2
ecuación conjuntamente con el sistema anterior da por resultado
a11=0,82 a12=0,57
Repitiendo el mismo proceso para el autovalor 0,33 se obtienen los autovectores
a11=--0,57 a12=0,82
y los componentes principales son:
Para los datos del ejemplo resulta:
Como los valores del primer componente son grandes comparados con los del
segundo, la mayor variabilidad se da en la dirección del primer componente principal, lo
cual indica que contiene la mayor parte de la información. Más específicamente, el
primer componente contiene el de la variación total. De esta
manera, el primer componente muestra un alto contraste visual. Por otra parte el
segundo componente es perpendicular al primero (porque no están correlacionados) lo
que indica que contiene información no incluida en el primer componente. Todo esto se
confirma en la Figura 3, donde se han graficado los datos en los dos sistemas (bandas y
componentes principales).
26Ejemplo 2
A partir de una muestra sistemática de 1 de cada 8 píxeles se obtuvo la matriz de
varianza-covarianza para esas bandas:
B1 B2 B3 B4 B5 B7
B1 102,83
B2 107,91 123,68
B3 156,30 176,07 271,58
B4 71,71 114,86 127,63 583,76
B5 148,94 183,70 275,91 340,63 516,96
B7 141,22 161,53 251,25 157,26 369,24 314,29
27Los autovalores extraídos fueron: 1365,72, 410,24, 115,60, 9,64, 9,05 y 2,83.
Según
j
Vj
j
j 1, p
la varianza original asociada con cada uno de estos componentes resultó ser 71,39%
para el primer componente, 21,44% para el segundo, 6,04% para el tercero, 0,5% para el
cuarto, 0,47% para el quinto, y 0.15% para el sexto. De acuerdo a estos porcentajes se
seleccionaron únicamente los 3 primeros componentes, que retenían un total del 98,87%
de la varianza original de la imagen.
La matriz de auto-vectores:
B1 B2 B3 B4 B5 B7
CP1 0,213 0,258 0,374 0,462 0,589 0,434
CP2 -0,213 0,171 -0,354 0,834 -0,041 -0,321
CP3 0,381 0,400 0,464 0,238 -0,585 -0,284
La matriz de autovectores muestra el sentido espectral de los componentes, es
decir, evidencia la asociación entre cada componente y las bandas originales. En esta
tabla puede verse que el primer componente recoge una valoración de las características
espectrales comunes a todas las bandas, lo cual puede asimilarse con el brillo de la
imagen, similar al aspecto que podría presentar una imagen pancromática.
El segundo componente muestra una importante asociación positiva con la
banda 4, apenas perceptible con la 5 y moderadamente negativa con el resto. En
definitiva, está evidenciando el contraste espectral entre el IRC y el resto de las bandas,
lo que muestra una valoración del vigor vegetal.
El tercer componente ofrece un claro contraste entre el visible-infrarrojo
próximo y el infrarrojo de onda corta, con correlaciones positivas para las primeras
bandas y negativas para las segundas. Esto parece indicar una valoración del contenido
de agua, por lo que se denomina componente humedad.
Las imágenes de los CP resultantes parecen demostrar esta interpretación. La
primera presenta una fisonomía similar a la de una imagen pancromática, con valores
promedio de las distintas cubiertas, bajos valores en el agua y la vegetación, medios en
los espacios edificados, y altos en los suelos descubiertos. El segundo componente
evidencia los sectores con una actividad clorofílica más intensa, como los pastizales y
cultivos, con tonos medios para los pinares y urbanizaciones, y tonos oscuros para los
28suelos descubiertos, aguas y vías de comunicación. El tercer componente remarca con
claridad las láminas de agua, vías de comunicación y espacios edificados.
Para facilitar la interpretación de toda esta información se puede generar una
composición en color con los 3 primeros componentes principales. Esta imagen se ha
obtenido asignando el cañón de color rojo al primero componente, el verde al segundo y
el azul al tercero. Las áreas de mayor vigor vegetal aparecen en verde o cian, mientras
los suelos descubiertos o áreas urbanas aparecen en magenta, y las láminas de agua en
azul.
La capacidad de síntesis del ACP la hace muy apropiada como filtro previo para
el análisis multitemporal. En este caso, el ACP sirve para retener la información más
significativa en cada período. Posteriormente, los CP de cada fecha se combinan, con
objeto de facilitar una mejor discriminación de cubiertas con perfiles estacionales
marcados. En este caso los primeros componentes resultantes del análisis no son los
más interesantes ya que recogen información común a las distintas fechas, es decir, la
información estable. Los últimos componentes son los que ofrecen la información no
común, es decir, la que cambió, que es la que interesa en este contexto.
Un problema inherente al ACP es la dificultad de establecer una interpretación a
priori de los componentes, ya que la transformación es puramente estadística y, por
tanto, muy dependiente de las características numéricas de la imagen. Algunos autores
sugieren que el primer componente siempre indica el brillo general y el segundo el
verdor. No obstante, esta afirmación es cierta cuando la imagen contiene una cantidad
suficiente de cobertura vegetal. De otra forma, el componente de vegetación puede ser
el tercero o cuarto. En definitiva, no pueden aplicarse reglas generales para la
interpretación de los CP.
2. TRANSFORMACIÓN TASSELED CAP (TTC)
Esta transformación se dirige a obtener nuevas bandas por combinación lineal de
las originales, con objeto de realzar algunos rasgos de interés en la escena. La diferencia
con el ACP es que la TTC ofrece unos componentes con significado físico,
independientes del tipo de imagen. Se basa en la evolución espectral de los cultivos a lo
largo de su período vegetativo.
La TTC fue ideada por la NASA y el USDA en los años 70 con objeto de
mejorar la predicción de cosechas. A partir de una serie de imágenes de zonas agrícolas
29se trató de sintetizar los ejes de variación espectral de los cultivos en una figura tri-
dimensional, de aspecto parecido a un gorro con borlas (tasseled cap). Considerando la
banda roja e infrarroja, la base de este gorro se define por la línea de suelos, donde se
sitúan los diferentes tipos de suelo.
A medida que crece la vegetación sobre un tipo de suelo, disminuye la
reflectividad en el rojo y aumenta en el infrarrojo cercano, por lo que el punto va
separándose de la línea del suelo en sentido ascendente y hacia la izquierda. Según el
cultivo va ganando en vigor, tiende a separarse de la línea del suelo, aproximándose al
eje de la banda infrarroja, y convergiendo en un punto cuando se produce la máxima
madurez. A partir de ahí el cultivo tiende a marchitarse, retornando hacia la línea de
suelos. La distancia de cada punto a la línea de suelo será, por tanto, proporcional a la
cantidad de vegetación.
La TTC tiende a poner más en evidencia el comportamiento espectral de la
vegetación y el suelo, a partir de crear nuevos ejes mejor ajustados a este espacio físico.
En este nuevo sistema de coordenadas se pretende que sea más nítida la separación entre
30ambas cubiertas. Para el caso de las imágenes MSS sobre las que se desarrolló esta
transformación, los nuevos ejes se obtuvieron a partir de:
u j R i' x i c
donde u es el vector correspondiente a la imagen transformada, xi el vector de entrada,
Ri el vector de coeficientes de transformación y c una constante para evitar valores
negativos. Los autores sugieren un valor c=32 y estos coeficientes. Los coeficientes
propuestos pueden aplicarse a distintas imágenes del mismo sensor, con la particular de
que fueron obtenidos a partir de las características de la cubierta agrícola del mediooeste
americano.
Los autores de esta transformación sugieren 3 componentes: uno denominado
Brillo (brightness), suma ponderada de las cuatro bandas originales, otro denominado
Verdor (greenness), relacionado con la actividad vegetativa (es similar a un índice de
vegetación y permite llevar a cabo un análisis de la densidad y estado de salud de la
vegetación), un tercero conocido como Marchitez (yellowness) que pretendía
relacionarse con la reducción en el vigor vegetal, y un cuarto sin significado aparente
(Nonsuch).
En un primer momento, esta transformación no se utilizó mucho. En los años 80 se
empezó a utilizar más y se demostró su aplicabilidad a otros sensores, principalmente al
TM y al AVHRR. En el sensor TM se puso de manifiesto la presencia de un nuevo
componente denominado Humedad (Wetness). En consecuencia, una imagen TM
presenta 3 ejes principales de variación:
1. Brillo (Brightness): refleja la reflectividad total de la escena.
2. Verdor (Greenness): indica el contraste entre las bandas visibles y el IRC.
3. Humedad (Wetness): se relaciona con el contenido de agua en la vegetación y en
el suelo, y se marca por el contraste entre el SWIR (infrarrojo de onda corta), en
donde se manifiesta con mayor claridad la absorción de agua, y el visible. Otros
autores han propuesto denominar a este componente Maturity, puesto que se ha
encontrado una clara relación con la madurez de la cubierta vegetal. En algunos
estudios se ha mostrado como un buen indicador de la edad y densidad de la
cobertura forestal. Además se observó que era el componente menos afectado
por la topografía.
31También puede leer

















































