Supercómputo con grandes matrices de dispositivos móviles - Orador Ing. Carlos Alejandro Pérez Universidad Tecnológica Nacional 07.06.2018 - IEEE ...
←
→
Transcripción del contenido de la página
Si su navegador no muestra la página correctamente, lea el contenido de la página a continuación

Supercómputo con
grandes matrices de
dispositivos móviles
Orador Ing. Carlos Alejandro Pérez
Universidad Tecnológica Nacional
07.06.2018
IEEE COMPUTER INTELLIGENCE SOCIETY CAPITULO ARGENTINA
Objetivo •Construir un sistema de cálculo de alta performance utilizando una matriz de cantidades masivas de dispositivos móviles, en plataformas disímiles. • Caso de uso → fase de entrenamiento de una red neuronal.
PRIMERA PARTE
¿ES POSIBLE?
Primera parte: ¿es posible?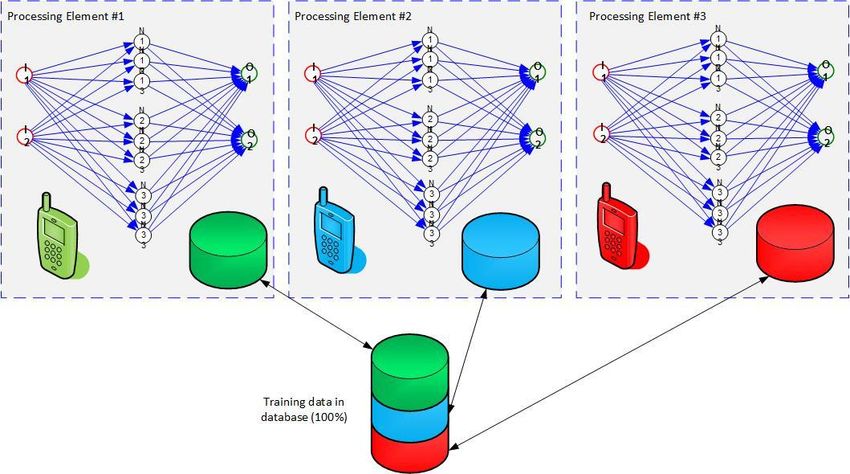
¿Qué es la convergencia?
• Es la evolución independiente de tecnologías que alcanzan a
un momento dado la habilidad de ejecutar tareas similares.
REDES
SISTEMA
SOFTWARE MICROELECTRÓNICA
CONVERGENTE
Primera parte: ¿es posible?
¿Hemos alcanzado la convergencia?
ES POSIBLE QUE SÍ
Las redes, hardware y software han dado enormes pasos.
Ya se tuveron los primeros ejemplos de sistemas
convergentes (Ubuntu Unity 8, Windows 10)
Subsisten enormes problemas y desafíos.
Estamos en los albores de una nueva época (ca.
2018)
Primera parte: ¿es posible?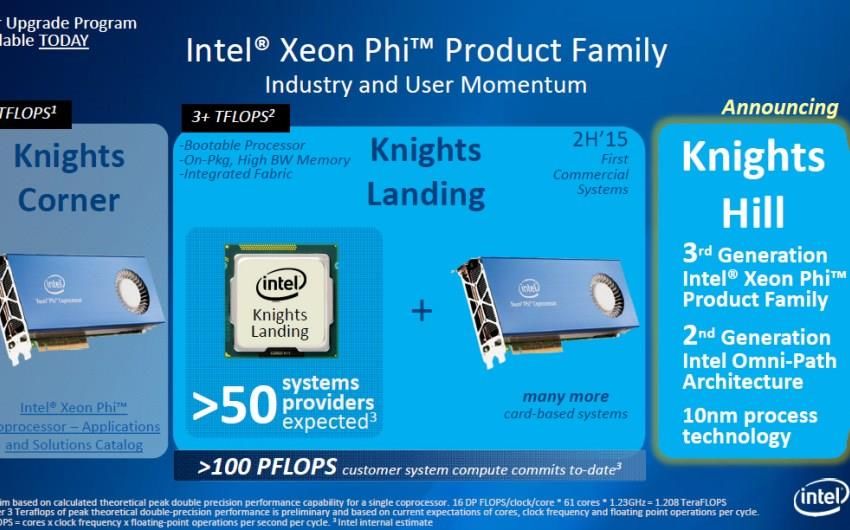
La microelectrónica convergente Primera parte: ¿es posible?

Procesador. Memoria. Almacenamiento
• Los servicios actuales se han visto impulsado por la
explosión de dispositivos móviles
• La microelectrónica debe atacar simultáneamente dos
frentes: SERVIDOR y CLIENTE.
Primera parte: ¿es posible? Fuente: “The Zettabyte Era: Trend and Analysis (Mayo 2015)
Incremento constante en clientes Primera parte: ¿es posible? Fuente: “The Zettabyte Era: Trend and Analysis (Mayo 2015)
Entretenimiento demandante Primera parte: ¿es posible? Fuente: “The Zettabyte Era: Trend and Analysis (Mayo 2015)
Crecimiento explosivo
• 7294 millones de personas vs. 7620 millones líneas
celulares
• Crecimiento de datos móviles 2015 → 2021: 10X
• CAGR (compound annual growth rate) 25% en LTE
• Para 2021 → 4.100 millones de líneas LTE.
• Suponiendo que en 2021 esté en uso un perfil muy
conservador (ca. 2015):
• ARM 4-core @1.2GHz & 2GB RAM
• Poder de cómputo latente sin ser aprovechado
Primera parte: ¿es posible?Potencia latente
•Con un perfil muy conservador (ca. 2015):
• ARM 4-core @1.2GHz & 2GB RAM
•Y sólo 1% de antedicha cantidad de móviles
•3.74 exa-instructions per second (EIPS)
•1.9 exa-floating point operations per second
(EFLOPS)
•Memoria en bruto de 7.7 exa bytes.
Primera parte: ¿es posible?¿La red 4G es lenta para una grilla?
El sistema nervioso humano trasmite de 55 a
200 m/s
P: ¿Cómo podemos hacer todo lo que
hacemos con una red tan lenta?
R: Masividad de neuronas y conexiones.
No es posible replicar esa masividad con
la microelectrónica moderna.
Primera parte: ¿es posible?¿Computación cuántica?
No resuelve
cualquier
problema
La
computación
actual →
mucho
futuro aúnServer: IBM Power 8 (2015 - mainframe)
12 núcleos
96 hilos
96 MB caché interno
128 MB caché externo
4GHz
Power 9
20 núcleos?
160 hilos?
Nvidia Tesla GPU?Server: IBM Power 9 (2017 - mainframe)
Power 9
• 8.000 millones de transistores (4.200)
• Hasta 24 nucleos (12 núcleos)
• 14nm FinFET (22nm SOI)
• PCIe Gen4 (PCIe Gen3)
• 120 MB shared L3 cache (96 MB
shared L3 cache)
• Multihilos de 4-vías y 8-vías
simultáneos (8-way simultaneous
multithreading) → 192 hilos
• Ancho de banda 120 or 230 GB/sec
(230 GB/sec)Server: Intel Knights Landing (Nov-2015)
• MCDRAM (DRAM
multicanal) 5x velocidad
• 215 watts máx.
• 16 GB RAM on-chip
• 72 núcleos, 4 hilos por
núcleo = 288 hilosServer: ¿Intel Xeon Phi v3 2017?...No
Server: MCDRAM
• Memoria hibrida.
• 16 GBytes en chip.
500 GBytes/seg.
• Puede ser
• Todo caché
• RAM del sistema
• Parte caché, parte
RAM de sistemaClient: Qualcomm Snapdragon 820 S.o.C.
(2016)
HDMI 2.0 → 4K 60 fps 64 bits
Miracast → 4K 30 fps FINFET (familia lógica)
14 nanómetros
2,2 GHz (hasta 3GHz)
4 núcleos
Image Signal Processor
25 megapíxels máx.
14 bits
Por primera vez,
mejora de 2x en
WiFi 802.11 ad 4.6 Gbps @ 60 GHz un solo salto de
LTE Cat- 12 @ 600 Mbps generación.
LTE - UCLIENT: Intel Atom x5 y x7
4 núcleos
4 hilos
1.6 GHz → 2.4 GHz
2MB Caché
2 watts
16 shaders GPU
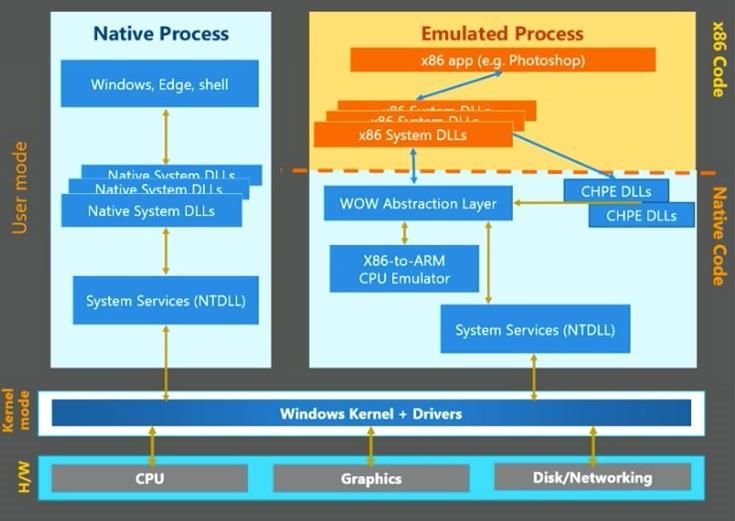
H.265 HEVCQualcomm Snapdragon 835 Avanza sobre la compatibilidad binaria con Windows (?) Un sistema Android ejecuta binarios Win32 instalados físicamente a velocidad casi-nativa.
Redes en la convergencia
Limitaciones actuales
• Los protocolos se definieron siempre para solucionar
un problema específico (árbol vs. bosque)
• En una red compleja, agregar un (1) dispositivo
implica:
• Tocar múltiples switches, routers, firewalls, portals.
• Actualizar ACLS, VLAN, QOS, protocolos → sólo accesibles
desde el mismo dispositivo
• La complejidad impide aplicar un conjunto consistente
de políticas en la red
• En una red mobile, puede llevar días reconfigurar listas de
acceso, seguridad y calidad de servicioLimitaciones actuales
• Escalamiento muy difícil.
• En los data centers existen miles de servidores
• ISP utilizaban modelos predictivos del tráfico
• Con los servicios actuales y la masividad, el tráfico es
impredecible
• Ciclos no sincronizados entre Carrier y Vendor
• Un proveedor de servicios (Google) depende de la
capacidad del vendor (HP, Cisco) en innovar.
• Ciclos de recambio tecnológico: 36 meses o más.
• Se necesita un modelo donde el Carrier pueda actualizar
la red más rápidamente → SDNRedes definidas por software (SDN)
• La red actual es una estructura arbórea, propia de
sistemas cliente-servidor, pero inadecuada por
• Cambios en los patrones de tráfico (este-oeste = P2P en
vez de norte-sur = C-S)
• IT pasa a ser de consumo masivo (smartphones)
• Explosión de servicios en la nube
• Datacenters de la nube requieren constante ampliación de
la red, miles de servidores.
Red es estática Servicios son dinámicos.Redes definidas por software - SDN • Una SDN permite administrar la red a través de capas de abstracción, los servicios se controlan por software, que interactúa con “el metal” a través de una interfaz, ej. OpenFlow
Redes definidas por software - SDN • El firmware de cada dispositivo (enrutador, conmutador, etc.) se migra a computadoras fácilmente accesibles. • Un solo punto lógico de administración • Este modelo simplificado es programable.
¿Qué es LTE-U? • Long Term Evolution – Unlicensed. • Propuesto por Qualcomm • Usar el espectro “descongestionado” de 5GHz que utiliza WiFi, pero coexiste con ella. • Los operadores celulares podrían ofrecer en esa banda sus servicios LTE • Muy controversial.
Gigabit internet • Conglomerado tecnológico a partir del 2-10-2015 • Contiene a Google después de la reestructuración • 1 GBPS download • 1 GBPS upload
LTE-U: en contra
WiFi 802.11 AD/ AF / AH
El Software convergente
Linux Ubuntu 8Sistemas operativos convergentes
• Plataforma = CPU + sistema operativo
• Compatibilidad binaria
• 32 – 64 bits
• Diferencias entre Big Endian (Motorola) y Little-Endian
(Intel)
• Buen rendimiento en factores de forma pequeños
• Interfaz del usuario unificada en el paradigma,
adaptable en tiempo de ejecuciónDesafíos en S.O.
Orden “natural” según está escrito Orden “inverso” que facilita acceso a datos
Orden en el cual entran los bytes por la redSoftware convergente • Juegos y entretenimiento • Comunicaciones y procesamiento de señales • Visión por computadora y aplicaciones • Redes definidas por software • Redes y aplicaciones vehiculares inteligentes • Salud remota.
Sistema convergente
Windows 10
Desktop Mobile Xbox IoT IoT headless Surface Hub Holographic
Raspberry
PC Tablet Xbox Band Surface hub Hololens
PI
Home
2 en 1 Phablet
Automation
Phone UWP (Universal Windows Platform):
• Un mismo kernel para todos los factores de forma
• Una API para cada factor de forma.Proyección de Lenguaje (2012)
Windows Runtime (8.0, 8.1)
C#, C++, VB.NET y Javascript C++ App
Projection
Todo compilado
IInspectable
Código Binario
Puro (32-64 bits) IUnknown
C#/
Projection
VB
CLR
Maquina virtual
W
App
.NET , Java
Objeto
HTML
Projection
Chakra
App
Browser con marco
de ejecución
Windows
Metadata
(antes MS CLI)¿Evolución o Crisis? 2015 Framework modular
open-source (2.6
Interfaz millones de líneas),
Paginas web sin unificada XAML corre en Windows,
servidor web Linux y Android
¿obsoleto?
Nativo, sin VM
Todo se compila
a binario Intel o
ARM
Gran
dependencia del
servicio NUGET
Nuevo Jitter 64 bits Self-hosted compiler
para instalar
Pensado para carga de trabajo en Open Source
bibliotecas
datacenters. Varios órdenes de Deja de ser blackbox para
magnitud más rápido. Vectores. pasar a tener APIsSnapdragon 835 compatible con
binarios Win32 (Intel 32 bits) 2017
CHPE: COMPILED HYBRID
PORTABLE EXECUTION.
Al instalar una DLL de Intel
x86 32 bits, se traduce
binariamente, instrucción
por instrucción, a ARM 64
bits.
Pero la interfaz que exhibe
es 32 bits
ARM CODE + 32 bits
entry pointsBrowsers Contenido de 200 MB Servidor IIS 2.7GB Google Chrome 1 GB
Todo es servidor, todo es cliente
Smartphone Smartphone visualizando en el browser
corriendo un portal la pagina HTML 5 + Javascript. No se
HTTP para diagnostico admiten plugins en los browser móviles
y gestión de softwareFin de la introducción Veamos ahora PARALELISMO
Potencia de cálculo → Límite Causas del límite • Ruido electromagnético • Límites en la tecnología de la litografía (10 nm) • Arquitectura de la familia lógica difícilmente mejorable Workaround • Aumentar el paralelismo • A bordo del procesador • Aumentando los nodos de cómputo • Implica tener frameworks adecuados en software
PAR1: Memoria distribuida compartida
dynamic distributed mobile computing, D2MC
Liang,Hsieh, & Lyu, 2007PAR1: D2MC: dynamic distributed
mobile computing, D2MC
• Si el procesador se adapta 300 veces por segundo a la
carga instantánea de cómputo
• Podremos considerar que la energía eléctrica
consumida para resolver un problema distribuido, se
distribuye entre los nodos también.
• ¿Qué implicancias tendría sobre la entropía real vs.
información?PAR2: Interfaz de pase de mensajes MPI SCATTERNET Donegan, Doolan, & Tabirca, 2008 PICO-RED
PAR3: PVM, parallel virtual machines
• VM: es una máquina lógica única
• Ejecuta sobre cluster o conjunto de procesadores con memoria
distribuida
• Cluster puede ser de hardware heterogéneo , tiene una capa de
abstracción HAL
• Unidad de paralelismo es la TAREA: subproceso que se conmuta
a si mismo entre tareas de cálculo puro y tareas de
Comunicaciones
• Ejemplo: TRAVELER (Wims, B., Xu, C. Z, 1999)
• Colección de agentes Java desplegados en WAN.
• Bytecodes viajan de un nodo a otro para se ejecutados.
• Utiliza matrices distribuidas para la comunicación
• Demostró que una solución pura OO es posible en entorno
distribuído utilizando VM y código móvil.Paralelismo de redes neuronales Nordström, 1995
Tipo paralelismo Hilos de ejecución Paralelismo tipo
Sesión de Por cada sesión de
De sesión de entrenamiento
entrenamiento entrenamiento
ANTECEDENTES
Por cada conjunto de ejemplos De conjunto de ejemplos de
Datos de ejemplo
dentro de una misma sesión entrenamiento
De capas (hacia adelante y hacia
Capa de neuronas Por cada capa de neuronas
atrás)
Neurona Por cada neurona en una capa De neurona
Para todos los pesos sinápticos de
Peso sináptico De peso sináptico
la neurona
Bits en el peso Para todos los bits del valor del
De bit de peso
sináptico peso sinápticoRedes y super-redes (1994) Arcand & Pelletier, 1994
• Una red neuronal distribuida es
• Una super-red
ANTECEDENTES
• Un numero determinado de sub-redes
• Cada sub-red se puede entrenar independientemente de las otras.
• Una vez entrenadas, las sub-redes se interconectan de tal forma que
la información puede circular a través de la
red como un todo.
• La red no puede entrenarse como un conjunto entero, sino que las
sub-redes deben hacerlo independientemente
• Una red está entrada si todas sus sub redes los estánPartición de datos (1997) Rogers & Skillicorn, 1997
• Cada procesador entrena la red utilizando un
subconjunto de datos
ANTECEDENTES
• Los cambios obtenidos se combinan y los nuevos valores se
aplican a la red una vez que la fase de entrenamiento ha
finalizado.
• Restricción: la sincronización debe
ocurrir una sola vez al finalizar el lapso de entrenamiento
debido a que la misma operación se ejecuta para cada
subconjunto de datos.Gran red distribuida (2001) Milea & Svasta, 2001
• RNA virtual, con algoritmo de retro-propagación
ANTECEDENTES
• Conjunto de PCs interconectadas
• Problemas
• Complejidad de la red → dificultad de entrenamiento
• Gran cantidad de ramas entre nodos
• Fase de retro propagación → cuello de botella de redOptimizando la comunicación (2005)
Se parte de dos modelos, y se los combina en un sistema híbrido
ANTECEDENTESModelo cooperativo de RNA de entorno
distribuido híbrido
ANTECEDENTES
Yang,
Wang, & Su, 2005Matriz de computo móvil
• Cada nodo de cálculo es un smartphone
• Se conectan por red inalámbrica (WiFi, WAN)
• Operador celular: alguien que desplegó la red por
nosotros
• Ventaja del smartphone
• Ampliamente programable
• Ampliamente conectable
• Importante potencia de cálculo
• System on a chip
• Dispositivos de visualización y entrada integradosDiagrama simplificado
Selection for PC#1
PC #1 PC #n Laptop #1
Smartphone #1
Carrier base
station
Tablet #1 Smartphone #2
Firewall WiFi AP
Router
HTTP
Server
MNIST database
Smartphone #3
Smartphone #n
Control INTERNET
Odata SignalR
service service pageEntrenamiento en paralelo por
patrones Dahl, Mc Avinney, & Newhall, 2008
• RNA completa se copia a cada dispositivo
1
• Cada dispositivo procesa un sub conjunto de datos, durante una época.
2
• Cada dispositivo transmite sus resultados al resto, y recibe los resultados del
3 resto y los combina con los propios (suma de los pesos sinápticos, etc.)
• Se verifica si se alcanzó la condición de error mínimo
4 • SI: red entrenada; NO: seguir con el proceso.Concepto de partida (impracticable)
Paralelismo de datos
Comunicación con estándar abierto
• OPEN DATA Protocol
• Transmisión y recepción de datos entre servidor y móviles
• HTML 5 WebSockets servicio
• Se puede montar una WebApi que utilice este modelo.
Los resultados se devuelven como documentos JSON
• HTML 5 persistent connection
• Permite emular un sistema distribuido con estado sobre
HTTP inherentemente state-less.Técnicas necesarias • Intra-process parallelism • Asynchronous calls. • Lazy evaluation techniques • Generic collections • Concurrent collections. • Support for universal applications (deprecated?) • Support for binary compatibility with Android • Snapdragon 835 or later processor
Open Data Los datos de un RDBMS se exponen a la web como documentos XML o JSON. Las consultas se realizan invocando una llamada HTTP estándar, como si navegásemos en la internet. http://host/servicio/Productos http://host/servicio/Rubros(1) http://host/servicio/Productos/Modelo.ElMasCaro()
SignalR • Proporciona respuesta real-time utilizando estándar abierto HTTP (!) • Utiliza hasta 4 transportes para lograrlo • HTML 1.1 Forever Frame • AJAX Long-polling • HTML5 Server-sent events • HTML 5 Websocket • Código compacto, Agnóstico a la conexión, Reconexión automática, Backplane con scale-out
SignalR – llamada en reverso
Clases neuralnetwork
Clases: Colecciones de objetos
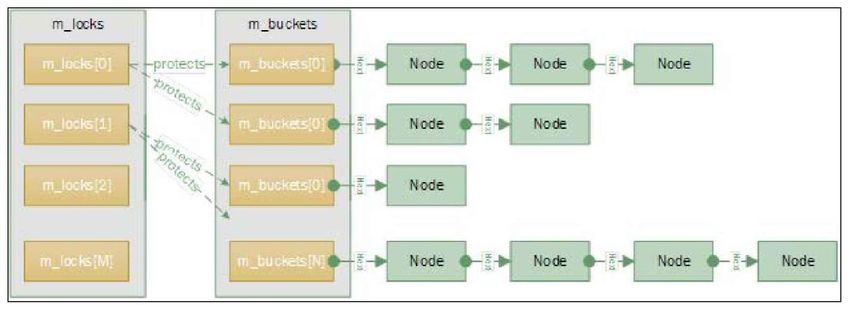
Colecciones de objetos • Matriz convencional. Un elemento=una neurona • Lista. N neuronas, se agregan al final. • Diccionario. N neuronas con índice b-tree • Bolsa de objetos. • Colección hash. N neuronas con método de almacenamiento y acceso basado en hash (25% menos eficiente en RAM)
Paralelismo de cálculo
• Los modernos frameworks móviles tienen amplias
facilidades para cálculo paralelo.
• Las tareas en segundo plano no son servicios o daemons
convencionales
• Deben verse como código ejecutable in-process.
• No se admiten servicios reales en segundo plano que no estén
previstos en el framework.
• Extraordinariamente difícil comunicar AppA con AppB en un
mismo dispositivo (sandboxing)
• Relativamente fácil conectar AppA y AppB a servicios fuera del
dispositivo.Paralelismo de cálculo en el móvil
• Por ello, todo cálculo paralelo debe ejecutarse en un
solo proceso de usuario.
• El framework
• distribuirá automáticamente el cálculo en los hilos
disponibles del procesador.
• Sincronizará automáticamente el conjunto de resultados
• Pondrá en cola las tareas si éstas son más que los núcleos
disponibles del procesador y las irá ejecutando a medida
que éstos queden libres.Paralelismo de cálculo en el móvil
• Un proceso en el hilo principal
• N subprocesos en paralelo en hilos secundarios (1 en cada
núcleo del procesador)
• El subproceso no puede comunicarse directamente al
hilo principal donde ejecuta la GUI.
• Lo hace a través de un despachador, objeto que puede
interactuar con todos los subprocesos de un procesoEjemplo de paralelismo de tareas
(2do. Nivel), perceptrón
Cada salida tiene
una colección de
ramas.
Por cada salida se
genera una tarea
paralela, que suma
los valores de
entrada , ejecuta la
activación y calcula
el error.Paralelismo de tercer nivel?
ES POSIBLE, CON
COLECCIONES
CONCURRENTESColecciones concurrentes • Son aquellas que pueden ser escritas al mismo tiempo desde N subprocesos. • El framework gestiona automáticamente la ejecución.
Diccionario concurrente
¿Podemos paralelizar datos, luego tareas, luego colecciones? • Si, pero no conviene. • Paralelizar la colección implica que el subproceso debería generar otro subproceso. • La gestión de este escenario gasta más recursos que la ganancia en performance. • → En 1 móvil = 1 nivel de paralelismo.
Tiempo(n_dispositivos)
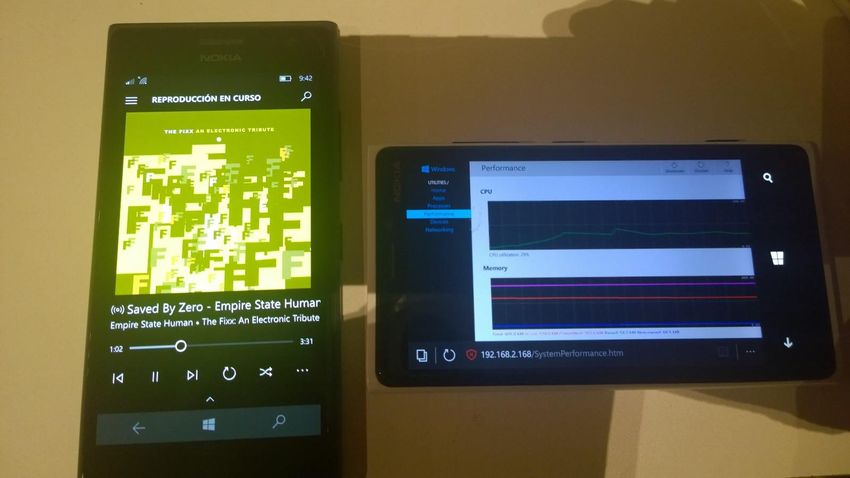
Medición de las colecciones en RAM Snapdragon 400, 1 GB RAM.
Tiempos de creación de colecciones Snapdragon 810, 3GB RAM
Programación asincrónica • Es obligatoria en dispositivos móviles. • No existen bases de datos on-board • ¿Qué pasó con HTML5 local database? • Los datos deben traerse desde servicios en la nube • Un servidor proporciona los datos de entrenamiento y los metadatos para construir la red neuronal en memoria en cada móvil. • La conexión entre el móvil y el servidor es WLAN o WiFi • Código es rápido, servidor es lento → asincrónica.
async Task MiTarea()
{
// crea cliente
HttpClient client = new HttpClient();
// GetStringAsync retorna una Task del tipo
Task getStringTask =
client.GetStringAsync("http://www.misitio.com");
// ejecute codigo que NO DEPENDA del resultadp
TrabajoIndependiente1();
TrabajoIndependiente2();
TrabajoIndependiente3();
// aqui se NECESITA el resultado, el codigo debe ESPERARLO
// el control se devuelve al llamador de MiTarea()
// la primitiva await bloquea la ejecución
string cualEsMiSitio = await getStringTask;
// con el resultado, el control se devuelve y se continúa
return cualEsMiSitio.Length;
}Recupera del servidor los datos
Código real (petición de datos al
servidor
public async Task GetTrainingInputs1(int startt2ID, int endt2ID)
{
// recuperar datos de entrenamiento, imágenes 1 a 100 inclusive
string lcUri = "http://localhost/t1?$filter=t2ID+ge+1+and+t2ID+le+100"
lcUri = System.Net.WebUtility.HtmlEncode(lcUri);
Uri serviceuri = new Uri(lcUri, UriKind.RelativeOrAbsolute);
HttpClient http = new HttpClient();
HttpResponseMessage response = http.GetAsync(serviceuri);
string json = await response.Content.ReadAsStringAsync();
SizeRetrieveTrainingData = json.Length;
JToken token = JToken.Parse(json);
JArray aj = (JArray)token.SelectToken("value");
TrainingInputList.Clear();
TrainingInputList = aj.ToObject();
}Medición de la potencia consumida
•Tarea extraordinariamente difícil (por la API).
•Números macro:
• AMD Threadripper @ 2.2 GHz, 16-core, 32 threads
100W+
• Intel I7 8850 mobile: 6-core, 12 threads @2.3-4.6
GHz. 45W.
• Snapdragon 835. big.LITTLE, 8-core, 8-threads
@2.45GHz+@1.9GHz. 2WNuevos desafíos •La ley de Amdahl y la de Gustafson se afecta por procesadores Asimetrcos •Y dejan de aplicarse en procesadores móviles componibles. •Un procesador que se “cablea” en tiempo real dependiendo de la demanda.
¿Preguntas? • Carlos Alejandro Pérez • cperez@rec.utn.edu.ar
También puede leer

















































